In this tutorial, we will learn how convert a PDF into an image using PDF to Image Web API. We will also see the async option in practice by executing tests asynchronously.
Step 1: Use the Authentication Key
As usual, first of all, we are having the authentication keys. We are going to declare that and which will be utilized in the headers. We have the source file here.
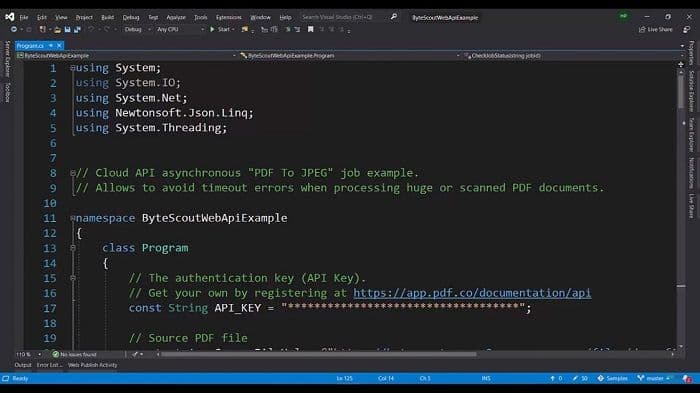
Step 2: Select the PDF Pages to be Converted to Images
Let’s see what’s inside. We have two PDF pages. We can specify the page numbers here, for example, which are the page numbers we want to convert to images, for example, 0 1? We can row in the comma-separated format. Or if we want to have the range – we can give 2-5, or if we want to have all the pages after a certain page number – we can do like “all the pages after the 7”.
If the PDF is encrypted, we can pull out the password. Make sure you provide the async option to true. So, upon providing the async option, we will have a different response. In the synchronous option, we directly get the output. It takes time to execute. But we get the output straight away. But in the async option, we will get the job as output and we have to check that job periodically.
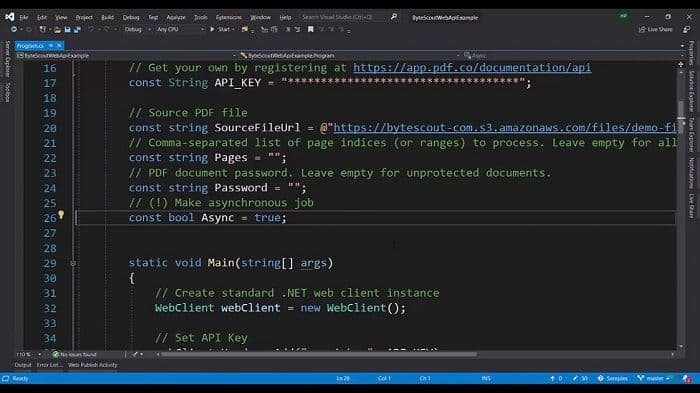
Step 3: Prepare URL for PDF to JPEG
We have the web client, we have declared the replied to object. We have provided headers for these. We are preparing the URL for PDF to JPEG. So we want to output in JPEG images. So unities and URLs will be converted from PDF to JPEG.
We provide the password and the pages. We provide the URL and enable the async option. So after this is done, the response string will be downloaded. We are going to parse it into JSON. We are using Newton’s opt for this and if this, all successful, then we are getting the job ID.
Step 4: Check the Result
We are going to check the result of this job in the row while loop. We are going into the infinite loop.
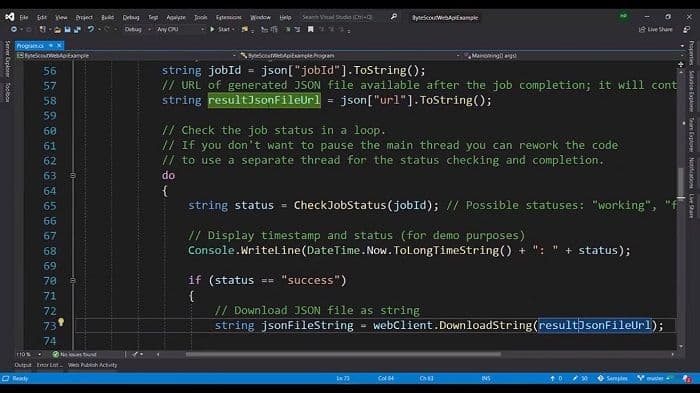
So you can see we are filing another Web API, which is basically just the status of the job. And we are providing the job ID here. Obviously, we are passing the API keys into headers. They’re getting their response and they’re passing the response into JSON. We are fetching the status and returning it. We are passing the JSON URLs.
Step 5: Download the File
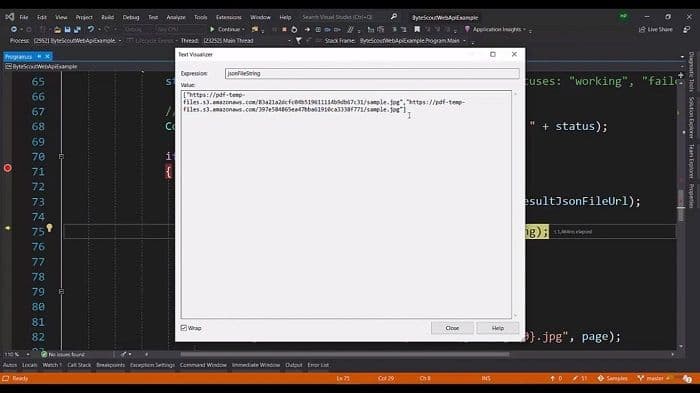
So once that’s ready, we are going to download this. Once the job is completed, we will see its output. Let’s see what’s inside. We are having the expected output file.
We’re going to download this file and we’re going to grab the response and we can see it is containing the two image URLs. Because the page, PDF itself is having two pages. So we’re getting the all pages URL and we are getting the one by one URL image by simply downloading these.
So it’s that easy to convert the PDF into images. If you want to get to know more about this Web API, you can always explore our documentation.
Check this PDF.co video tutorial using PDF.co Web API and follow us on YouTube!
Video Guide
Related Tutorials
