Parse PDF Document using Power Automate Cloud
In this article, we’ll demonstrate how to parse PDF documents using the PDF.co connector, and extract data from PDF with Power Automate in various formats such as JSON/CSV/XML. For this demo, we’ll extract invoice document information into JSON format. Let’s get started!
Create new instant cloud flow
The first step is to create a new instant cloud flow.
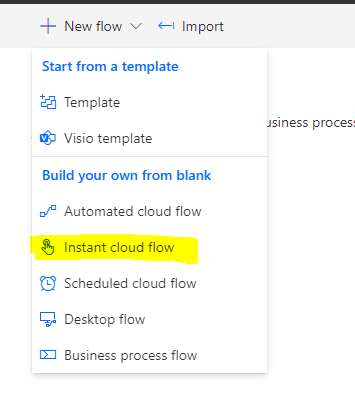
Next, we’ll name this flow “Doc Parser” and make it a manual trigger type.
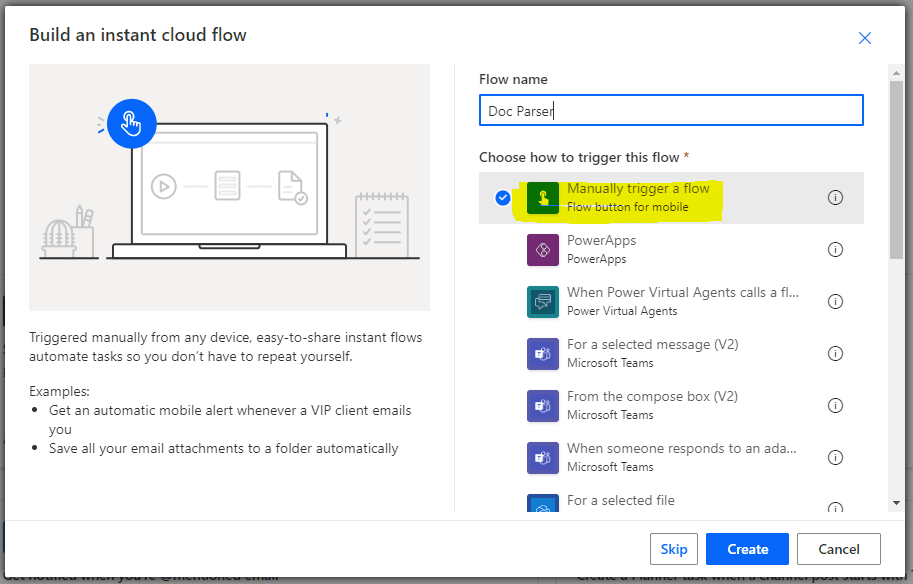
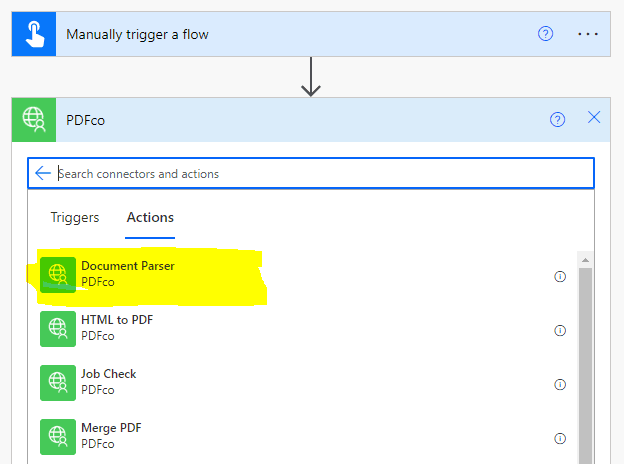
Add PDF.co Document Parser
Now, it’ll list all actions supported by the PDF.co connector. From the list, select “Document Parser”.
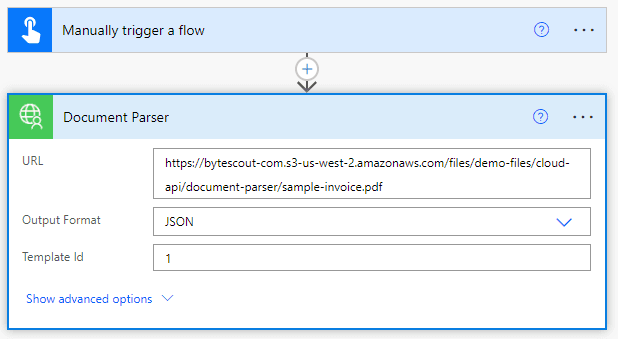
It’ll present all properties of Document Parser action. Here, we have to add values as per our requirements.
The following table briefly explains some properties of the Document Parser action.
URL - Url to the source document
Output Format - Output data format. Can be JSON, CSV or XML.
Template Id - Set Id of document parser template to be used.
Here, TemplateId is the most important parameter. A Template is a bunch of data extraction information in YAML format. We can specify field names and what part of the PDF to extract data from. After login, navigate to the Document Parser page and there we can create a new template and get its template id.
Checking response
Now that we have configured all document parser parameters, let’s create a new email notification action to check the output. Here, we have set the output URL in the email body.
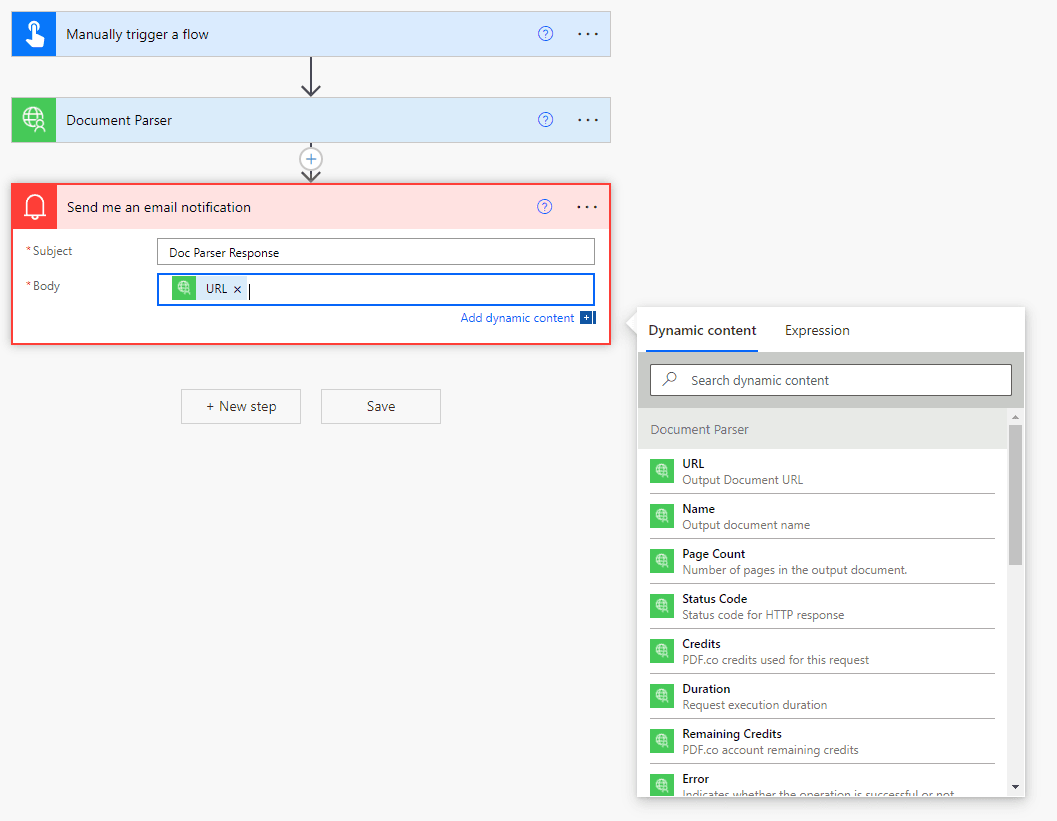
With all configurations completed, let’s save this flow and execute it.
Upon successful execution completion, we’ll have an email containing document parser information.
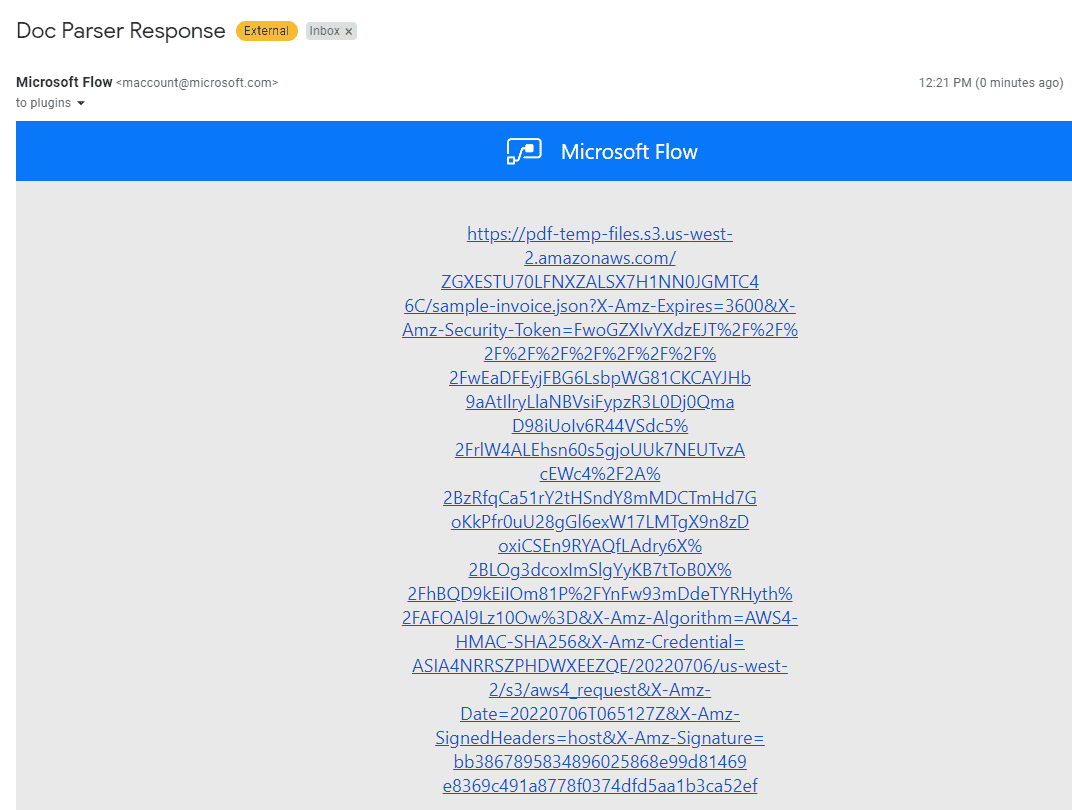
If we open this URL, we’ll view the JSON output as below. Fields from this JSON can be used further as per our requirements.
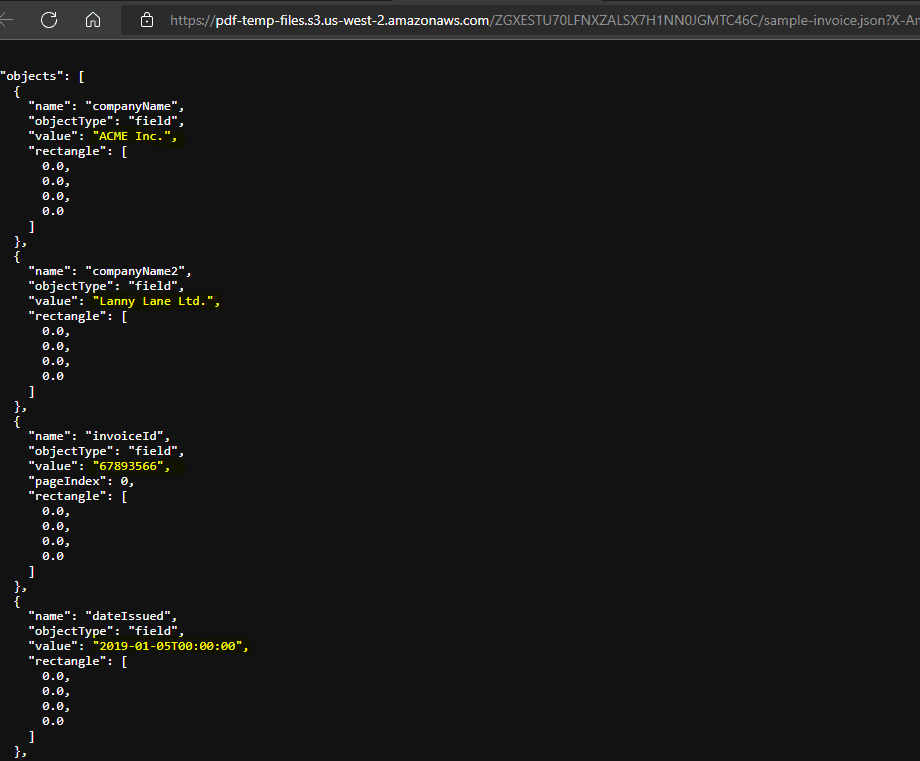
That’s all guys! It’s that easy to parse PDF documents using PDF.co Power automate connector. It also works seamlessly with scanned PDFs and images too.
So, you learned to extract data from PDF with Power Automate. Please try it out yourself for better exposure. Thank you!
Related Tutorials
