How to Convert HTML to PDF in Salesforce Apex using PDF.co
In this step-by-step guide, we’ll briefly see steps on how to convert HTML to PDF in Salesforce Apex using PDF.co. Initially, we’ll go through all the basic steps on salesforce integration. Later we’ll also see the code and demo video. Let’s get started!
Step 1: Create Remote Site Settings
Create two remote site settings in the Salesforce Org like below:
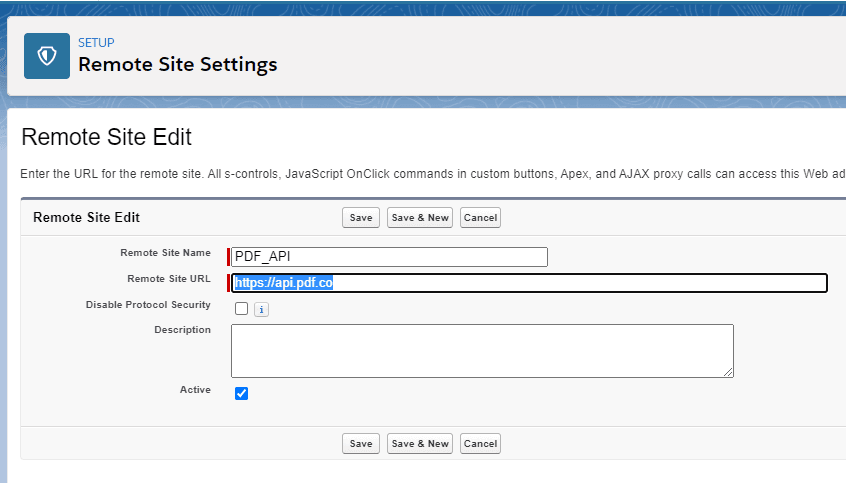
Please note URL is “https://api.pdf.co”
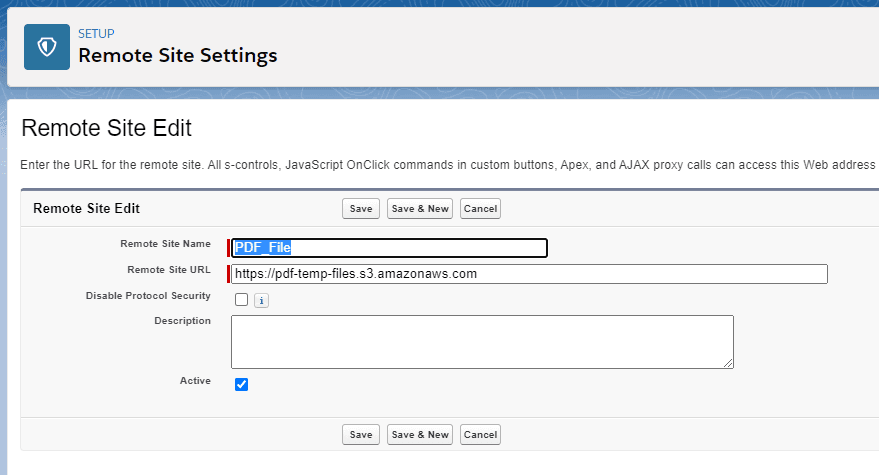
Please note URL is “https://pdf-temp-files.s3.amazonaws.com”
Step 2: Create an Apex Class in Salesforce
Create an apex class in Salesforce like below and paste the code there.
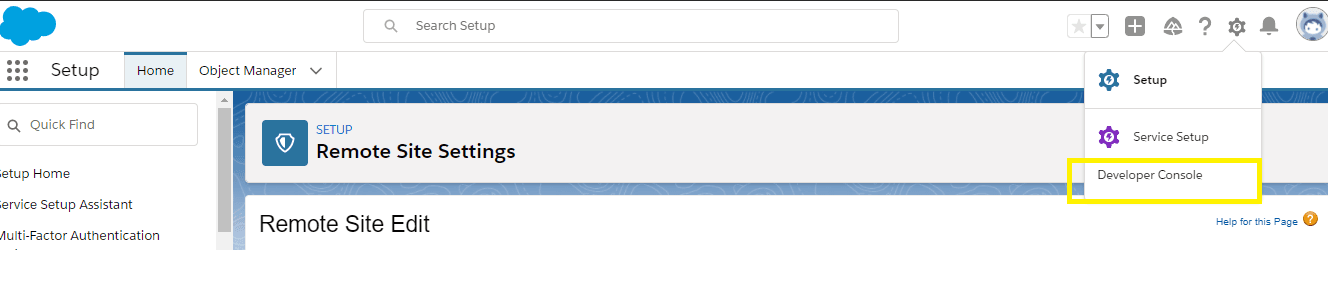
Once you login to the Salesforce org, you will see the screen like below and click on “Developer Console”
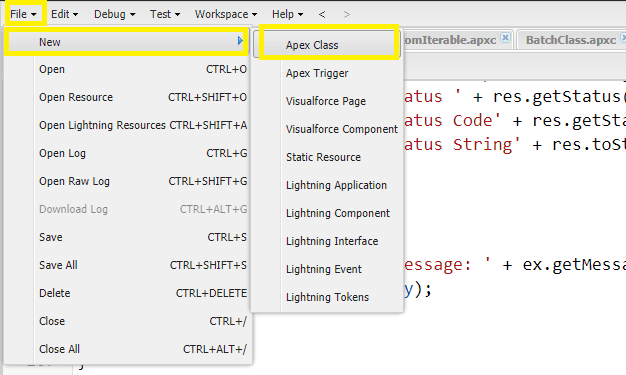
Create an apex class. For this, click on “Files” then “New” then “Apex Class”.
Write the class name “GeneratePDFFromHTML” and click “Ok”. Now copy the GeneratePDFFromHTML code in this file.
Similarly, create a new file with the name “GeneratePDFFromHTMLTest” and copy the code.
Step 3: Enter the API Key
In the GeneratePDFFromHTML file, please add the PDF.co API key by replacing the ‘******************************************’.

Similarly, please add the HTML file name instead of sampleHTMLDocument. Then please add the Destination file name which you want as a PDF.
Step 4: Search Files from the App Launcher and Upload HTML
Now, Search Files from the “App Launcher” and upload the HTML file here.
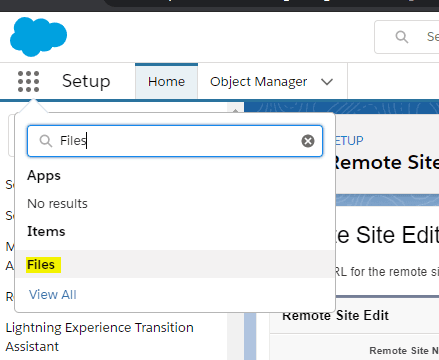

Step 5: Verify the Code
To Verify the code, please open the execute Anonymous window and call the method like below.
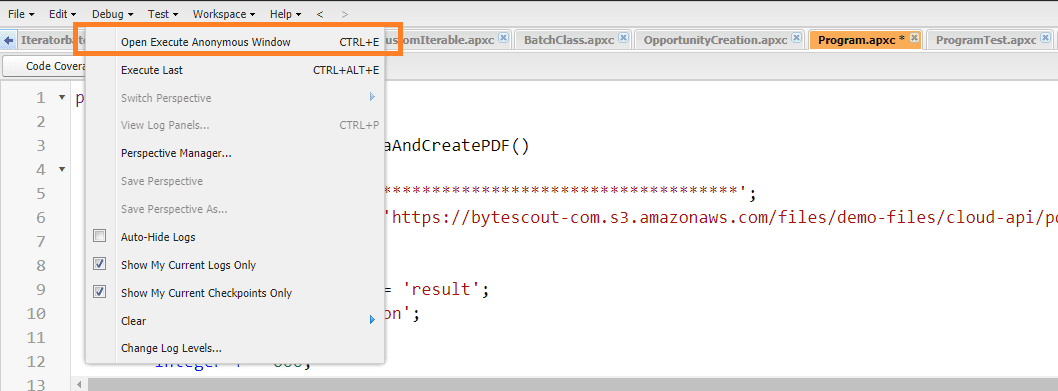
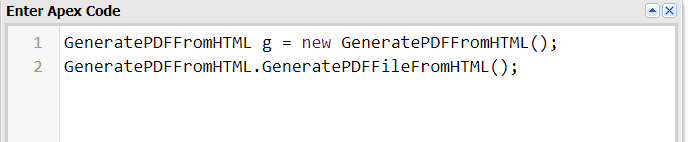
Step 6: Search Files
Now, Search Files from the “App Launcher”.
You will see the output PDF file there.
Step 7: Source Code Files:
GeneratePDFFromHTML.cls
public with sharing class GeneratePDFFromHTML {
static String API_KEY = '"*****************************************';
@TestVisible
String fileName = 'SampleHTMLDocument';
string destinationFile = 'generatedPDFFromHTML.pdf';
public void GeneratePDFFileFromHTML()
{
try
{
ContentVersion cv = [select Title, VersionData from ContentVersion where Title = :fileName limit 1];
String body = cv.VersionData.toString();
Map<string, Object> parameters = new Map<string, Object>();
parameters.put('html', body);
parameters.put('name', destinationFile);
parameters.put('margins', '5px 5px 5px 5px');
parameters.put('paperSize', 'Letter');
parameters.put('orientation', 'Portrait');
parameters.put('printBackground', true);
parameters.put('asyncy', false);
parameters.put('header', '');
parameters.put('footer', '');
string jsonPayload = Json.serialize(parameters);
string url = 'https://api.pdf.co/v1/pdf/convert/from/html';
HttpRequest req1 = new HttpRequest();
req1.setBody(jsonPayload);
req1.setHeader('x-api-key', API_KEY);
req1.setHeader('Content-Type', 'application/json');
req1.setEndpoint(url);
req1.setMethod('POST');
req1.setTimeout(60000);
Http http = new Http();
HTTPResponse res1 = http.send(req1);
if(res1.getStatusCode() == 200)
{
Map<String, Object> deserializedBody = (Map<String, Object>)JSON.deserializeUntyped(res1.getBody());
Boolean isError = Boolean.ValueOf(deserializedBody.get('error'));
if(isError == false)
{
String urlVal = (String)deserializedBody.get('url');
downloadPDFAndStore(urlVal, DestinationFile);
}
}
else
{
System.debug('Success Response ' + res1.getBody());
System.Debug(' Status ' + res1.getStatus());
System.Debug(' Status Code' + res1.getStatusCode());
System.Debug(' Status String' + res1.toString());
}
}
catch(Exception ex)
{
String errorBody = 'Message: ' + ex.getMessage() + ' -- Cause: ' + ex.getCause() + ' -- Stacktrace: ' + ex.getStackTraceString();
System.Debug(errorBody);
}
}
@TestVisible
private static void downloadPDFAndStore(String extFileUrl, String DestinationFile)
{
try
{
Http h = new Http();
HttpRequest req = new HttpRequest();
extFileUrl = extFileUrl.replace(' ', '%20');
req.setEndpoint(extFileUrl);
req.setMethod('GET');
req.setHeader('Content-Type', 'application/pdf');
req.setCompressed(true);
req.setTimeout(60000);
//Now Send HTTP Request
HttpResponse res = h.send(req);
if(res.getStatusCode() == 200)
{
blob fileContent = res.getBodyAsBlob();
ContentVersion conVer = new ContentVersion();
conVer.ContentLocation = 'S'; // to use S specify this document is in Salesforce, to use E for external files
conVer.PathOnClient = DestinationFile + '.pdf'; // The files name, extension is very important here which will help the file in preview.
conVer.Title = DestinationFile; // Display name of the files
conVer.VersionData = fileContent;
insert conVer;
System.Debug('Success');
}
else
{
System.debug('Success Response ' + res.getBody());
System.Debug(' Status ' + res.getStatus());
System.Debug(' Status Code' + res.getStatusCode());
System.Debug(' Status String' + res.toString());
}
}
catch(Exception ex)
{
String errorBody = 'Message: ' + ex.getMessage() + ' -- Cause: ' + ex.getCause() + ' -- Stacktrace: ' + ex.getStackTraceString();
System.Debug(errorBody);
}
}
}GeneratePDFFromHTMLTest.cls
@isTest
public class GeneratePDFFromHTMLTest
{
@TestSetup
static void makeData(){
ContentVersion conVer = new ContentVersion();
conVer.ContentLocation = 'S'; // to use S specify this document is in Salesforce, to use E for external files
conVer.PathOnClient = 'DestinationFile.pdf'; // The files name, extension is very important here which will help the file in preview.
conVer.Title = 'Sample'; // Display name of the files
conVer.VersionData = Blob.ValueOf('fileContent');
insert conVer;
}
private testmethod static void testGeneratePDFFileFromHTML()
{
Test.setMock(HttpCalloutMock.class, new GeneratePDFFromHTMLTest.DocumentCreationMock());
Test.startTest();
GeneratePDFFromHTML dc = new GeneratePDFFromHTML();
dc.fileName = 'Sample';
dc.GeneratePDFFileFromHTML();
Test.stopTest();
List cv = [select Id from ContentVersion];
System.assertEquals(2, cv.size());
}
private testmethod static void testGeneratePDFFileFromHTMLException()
{
Test.startTest();
GeneratePDFFromHTML dc = new GeneratePDFFromHTML();
dc.GeneratePDFFileFromHTML();
Test.stopTest();
List cv = [select Id from ContentVersion];
System.assertEquals(1, cv.size());
}
private testmethod static void testdownloadPDFAndStoreException()
{
GeneratePDFFromHTML.downloadPDFAndStore(null, null);
List cv = [select Id from ContentVersion];
System.assertEquals(1, cv.size());
}
public class DocumentCreationMock implements HttpCalloutMock {
public HTTPResponse respond(HTTPRequest req) {
HttpResponse res = new HttpResponse();
String testBody = '{"hash":"e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855","url":"https://pdf-temp-files.s3-us-west-2.amazonaws.com/0c336bfcef1a473d98492bda25d8da03/newDocument.pdf?X-Amz-Expires=3600&x-amz-security-token=FwoGZXIvYXdzEO7%2F%2F%2F%2F%2F%2F%2F%2F%2F%2FwEaDHWK1dY4d4lOgsheliKBATwE%2FZewASPTEnPxTn%2BOdYhP4h3gljAJfqbRvQptDX7wdWLmrBS7Tg4qTU6pAbxIdXChGPjBWpSbtiADJKmqkmyhkUmE8GSM1%2FGtJO6bga2pgzvFLXmzxjTf3%2BFNqwYOvbyApIZdVLoPpEKY6PlCflQtLTd30dhelm6xpB8pitbdhSjdz8KCBjIobVy%2Fjwybwp6OQgB%2FT6QkIo2dU07gtFREdn5jhRyvnS5lkccweBV1%2Bw%3D%3D&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=ASIA4NRRSZPHMV5P3JOS/20210316/us-west-2/s3/aws4_request&X-Amz-Date=20210316T124309Z&X-Amz-SignedHeaders=host;x-amz-security-token&X-Amz-Signature=95287bf3c007fed4c2c5aeea1ce75c846cc6c68b22aaf35175ebe41a105f54e1","pageCount":1,"error":false,"status":200,"name":"newDocument","remainingCredits":9913694,"credits":3}';
res.setHeader('Content-Type', 'application/json');
res.setBody(testBody);
res.setStatusCode(200);
return res;
}
}
}Video Guide
Related Tutorials


