How to Convert PDF to JSON with UiPath
In this tutorial, we will see how to convert PDF to JSON using PDF.co and UiPath automation.
Implement PDF.co Scope
Before performing PDF activities, you must add and configure PDF.co Scope giving you the best way to utilize the PDF.co API key. Check out the figure below for more details.
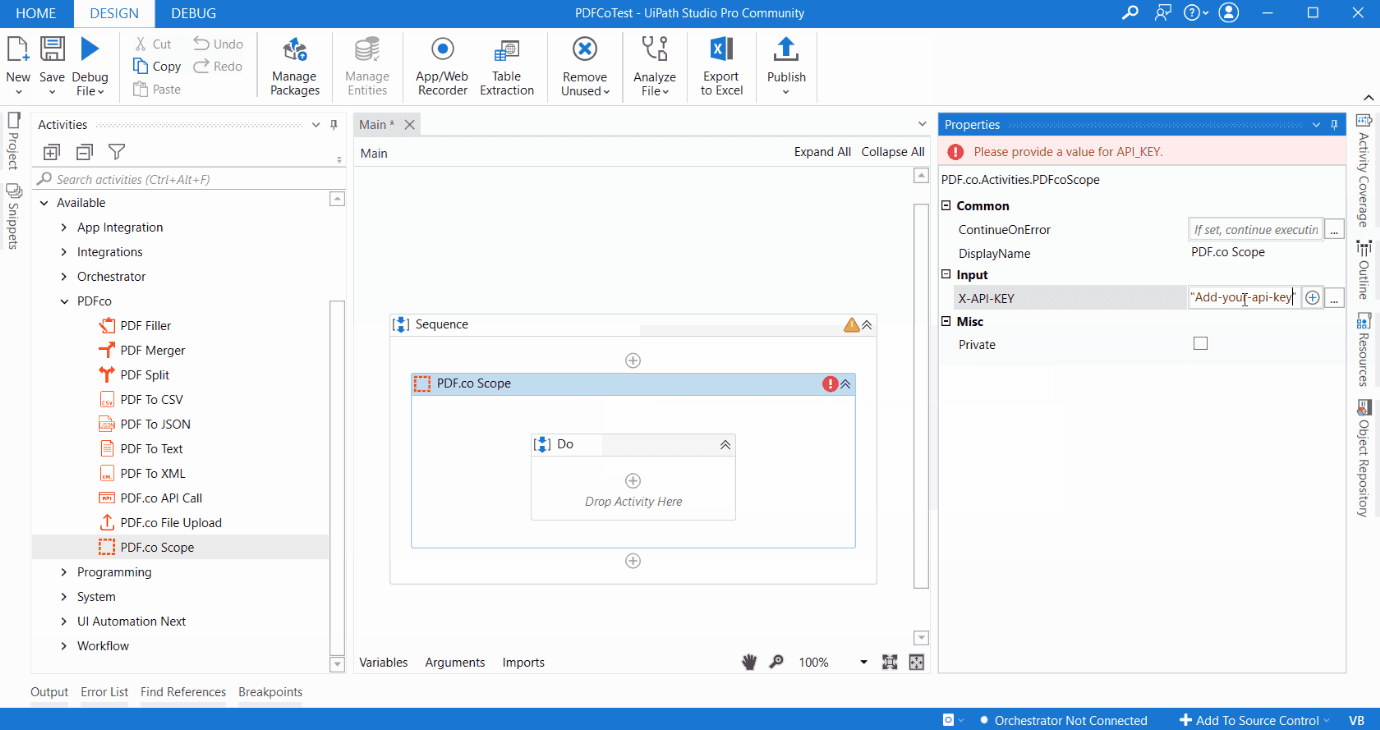
It is good to know that other PDF.co activities such as PDF to JSON, PDF to CSV, PDF Merge, PDF Split, PDF Filler, PDF to XML must be run inside PDF.co Scope. They use PDF.co API key from PDF.co Scope as well.
Please use PDF.co API key for PDF.co request authentication. You can get the PDF.co API key upon signing up.
Convert PDF to JSON with UiPath
I have already added the PDF to JSON activity into PDF.co scope. Here we can see that mainly it’s containing the PDF file as an input parameter. We can provide either the URL or the absolute file path in the inputs and there are other inputs, for example, if we want to restrict the extraction of the data as JSON for a certain region only then we can provide the coordinates of the region in the Extraction region box.
If we want to restrict the extraction to certain pages only then we can provide the page numbers in a comma-separated format in the pages box. If our input PDF is password protected then we can provide the PDF document password. Here are some other outputs, for example, the output text contains the JSON text format for the extraction result and the result file URL contains the URL of the generated extractor JSON. Let’s see this in action.
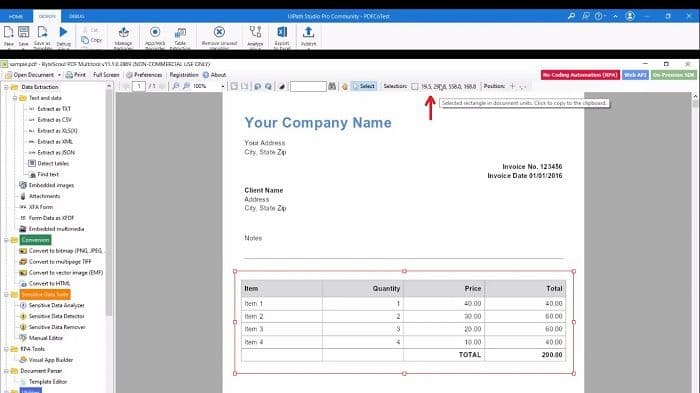
Here I have one sample file of the invoice which contains some dummy items here. Now try to extract this particular table in JSON format. First of all, we need to provide the input file. I do copy and paste the PDF file path here and provide the destination file path also. Let’s assume as our destination will be in the output folder. I’m providing a path to the output file.
We only want to extract this table, not all the documents. So to get coordinates, I’m using the program named PDF Multitool. It’s a freeware service provided by ByteScout. If you want this program, you can just google this out and install it. Now select the table here and click on the coordinate to copy to the clipboard and provide the extraction region here.
For the output text, I create in the variable and name it ExtractedJSON. Here, in the message box add the path, a variable name like ExtractedJson, and click on the run option.
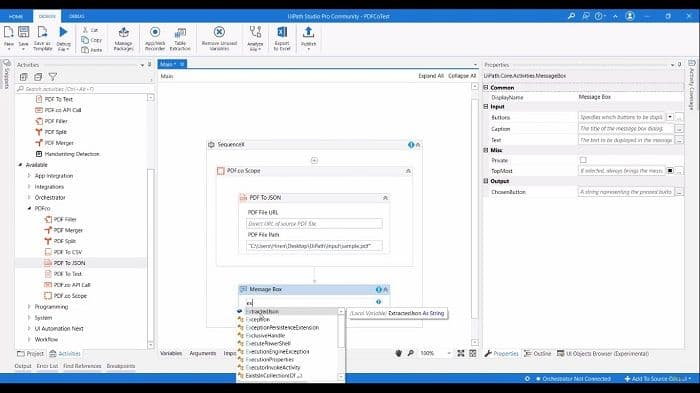
So after the successful execution, we will see our message contains the JSON output, and as well as the result file should be generated. We can see the message box containing all the JSON, and it is also providing the other aspects of the element, for example, font name, font size, coordinates along with the text. It’s very useful. Now check these JSON also and open them with the sublime text.
We can see all the data are here. This is how we can use the PDF to JSON UiPath activity to extract JSON from PDF documents.
Integrate PDF.co and UiPath
To start, please use the button below:
Visit the UiPath Marketplaceor
Download the Latest UiPath Plugin for PDF.coNeed help or support? Please contact us.
Related Tutorials
