PDF Classifier (Document Classification Based on Classification Rules)
Classify and Sort Incoming PDF Documents and Scans Based on Easily Created Classification Rules in CSV Based on the Set of Keywords with Optional OR and AND Logics
If you need to extract data from a lot of PDF documents coming from different sources, then the best way is to first sort them by the vendor. We’ve created a PDF Classifier tool that is available in our PDF Extractor API.
How it Works
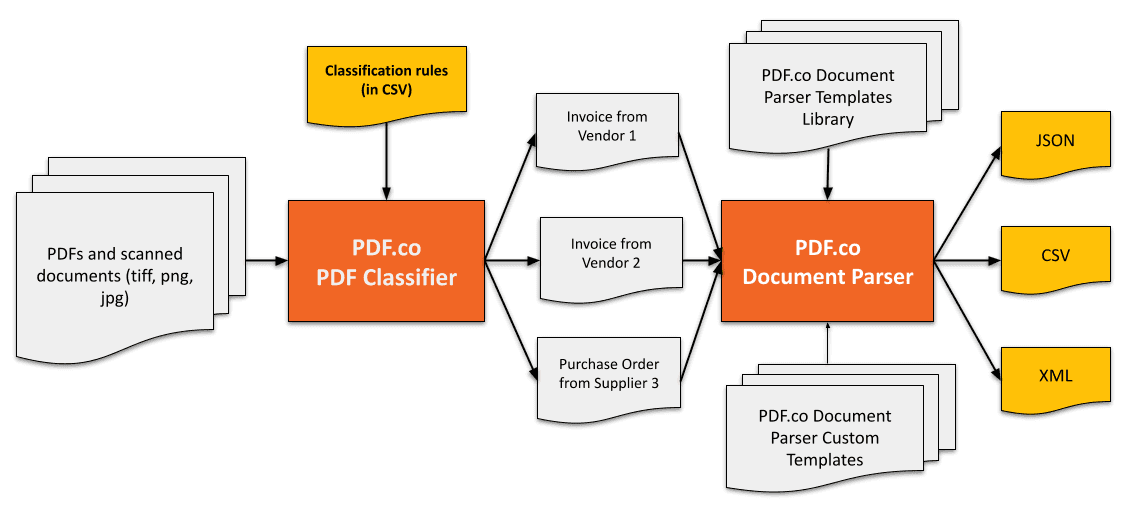
- Create rules as CSV (comma-separated values) where every row has the following columns: classname, OR or AND logic (OR is used by default), keyword1 or phrase1, keyword2 or phrase2,…
- Test these rules on your sample PDF files
- Generate JSON request for use with PDF.co or just save rules as CSV and pass the link along with all requests
- Use pdf/classifier endpoint in PDF.co (cloud) or API Server (on-prem)
- pdf/classifier endpoint will return detected class for input PDF, JPG, PNG, or TIFF document
To make it easy to quickly test, maintain, update your classification rules we’ve created the classification rules testing tool that is available as a part of the PDF Multitool desktop app (Download PDF Multitool).
PDF Multitool works quickly and no Internet is required because no files are uploaded. With PDF Multitool, you can:
- Create and Test Classification Rules
- Use the spreadsheet-like interface to define new classes with rules, use plain text, use regular expressions and quickly test rules to see how they work on your PDF documents.
- Test Classification Rules on Folders With PDF Documents
- As the ultimate goal is to sort PDF files in a batch, you can test classification rules on folders with PDF files to see which class every file will produce.
- Test Classification Rules on Scanned Documents
- You can also test classification rules on scanned documents as well.
- Copy Rules as JSON
- You can save classification rules into a CSV file or you can simply copy ready-to-use JSON request. You can use this request with PDF.co.
How to Use PDF Classifier in PDF.co
In this tutorial, we will demonstrate how to use the PDF Classifier in PDF.co. To follow along, you can download the sample file. We will use both PDF Multitool and PDF.co to showcase this functionality. If you haven’t yet, visit this page to download the PDF Multitool.
PDF Multitool Classifier Test Tool
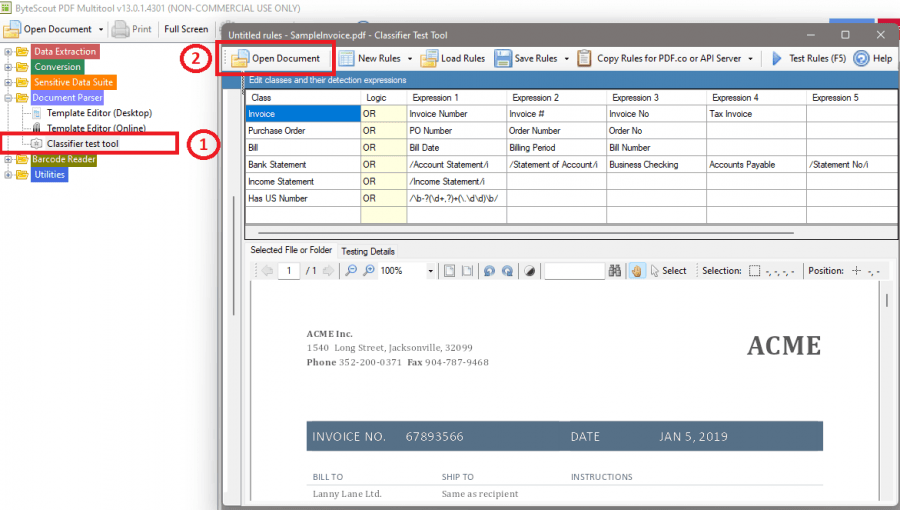
First, download and open the file in the PDF Multitool Classifier Test Tool.
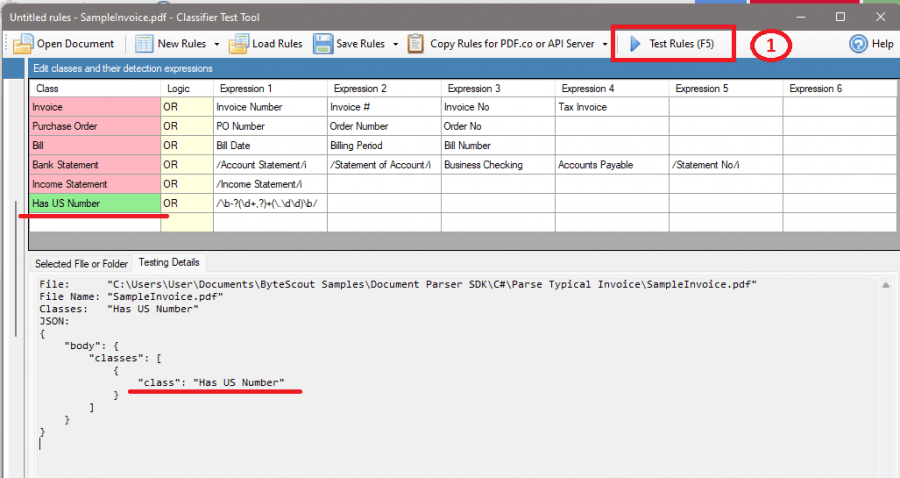
Run Test Rules
Run the Test Rules.
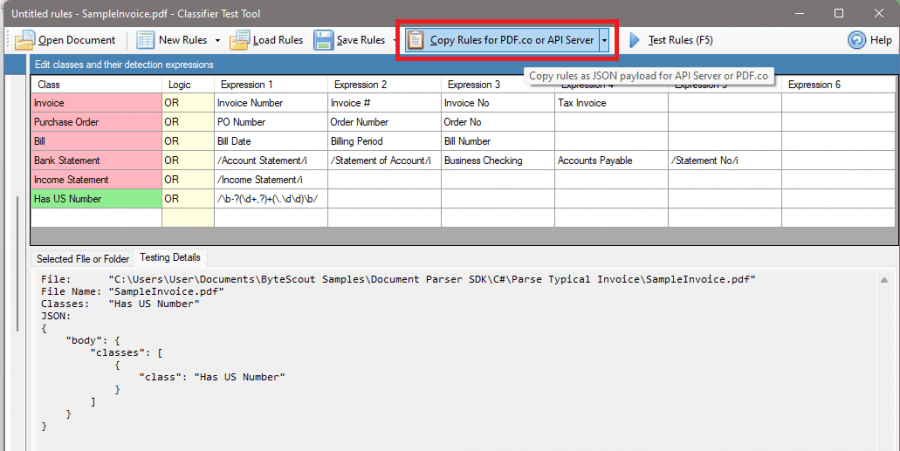
Copy Rules
Click on the Copy Rules for PDF.co or API Server.
Get rulesCSV Value
Paste the JSON in your favorite text editor and copy the rulesCSV value.
Open Request Tester
Open the PDF.co Request Tester. This will require that you log in to your PDF.co account. Here’s the direct link: https://app.pdf.co/request-tester.
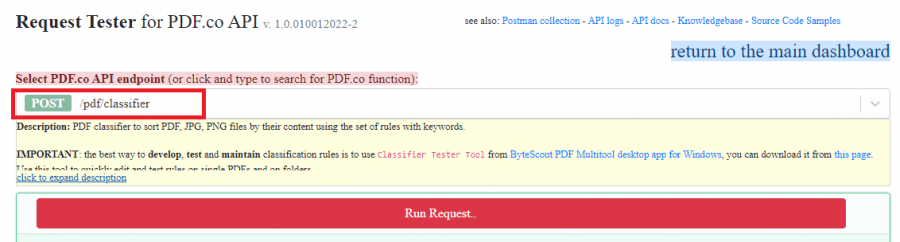
Insert rulesCSV Value
Remove the rulescsv parameter’s default value and paste the rulesCSV value that we copied from the Classifier Test Tool.
Run Request
Run the Request button to see the output.
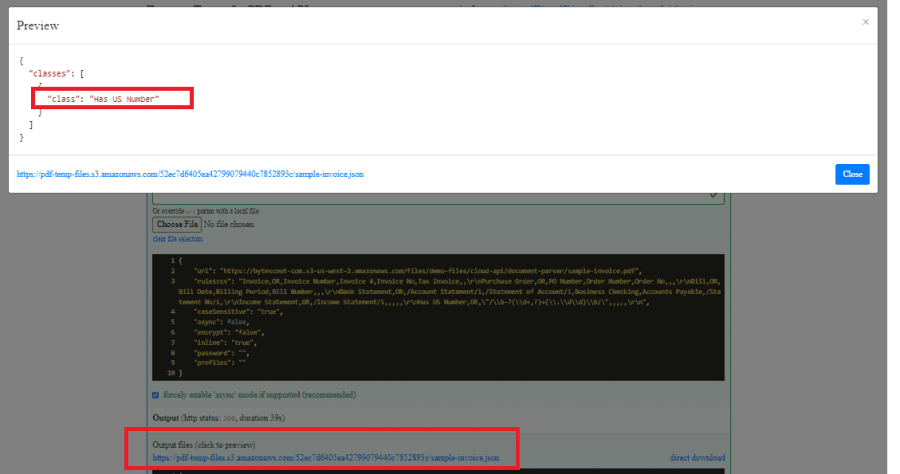
Preview Output
Click on the output file link to preview.
Head to this page to download the PDF classification testing tool. (Download the PDF Multitool app).
Related Tutorials
