Here the SourceFileURL field contains the URL of the filled PDF form that you get as a result of executing code in section 2.
Fill and Extract PDF Form Fields using PDF.co Web API in Python
14 Minutes Read
In this article, you will see how PDF.co Web API is called in Python to automatically fill a PDF form. In addition, you will also see how to make a non-searchable form as searchable and how to extract PDF form fields using PDF.co Web API in Python.
To see the details of all the Web API functionalities provided by PDF.co, check out the official documentation.
Step 1: Converting a Non-Searchable PDF Form to a Searchable PDF Form
Before you can fill out a PDF form containing some fields, you have to convert that PDF form into a searchable format. With PDF.co Web API, you can convert a non-searchable form to a searchable form in Python by performing the following steps.
The first step is to import the required libraries as shown in the following script.
import os
import requests
import time
import datetimeThe next step is to initialize some variables that you will be using to make calls to the PDF.co Web API.
API_KEY = "***********************************************"
BASE_URL = "https://api.pdf.co/v1"
SourceFileURL = "https://pdf-temp-files.s3.amazonaws.com/b73b01311064415ca30fc78e5596665b/D__Datasets_f1040.pdf"
Pages = ""
Password = ""
Language = "eng"
Async = True
DestinationFile = ".\\result.pdf"The variables in this case are:
API_KEY:You can get it when you create an account with PDF.coBASE_URL: This is the base URL for the PDF.co Web API. All API functionalities exist at this base location.SourceFileURL: This is the URL to the non-searchable input PDF file that you want to convert to a searchable PDF. In our case, we will be using the non-searchable tax. A part of the form looks like this:
4. Pages (optional): Specifies the pages of your PDF document that you want to convert. Leaving this field empty means all pages should be converted
5. Language (optional): The language of the input PDF document
6. Async: When setting to true calls the PDF.co Web API in asynchronous mode.
7. DestinationFile: Name of the output searchable PDF document
The API call to the PDF.co Web API expects parameter values that you specified in the previous step, in the form of a dictionary. The following script defines the parameter dictionary.
parameters = {}
parameters["async"] = Async
parameters["name"] = os.path.basename(DestinationFile)
parameters["password"] = Password
parameters["pages"] = Pages
parameters["lang"] = Language
parameters["url"] = SourceFileURLThe next step is to define the URL which contains a call to the PDF.co Web API that converts a non-searchable PDF form to a searchable form.
To actually make the API call, the URL for the API call, along with the parameter dictionary and the API key is passed to the post() method of the requests module as shown in the script below:
url = "{}/pdf/makesearchable".format(BASE_URL)
response = requests.post(url, data=parameters, headers={ "x-api-key": API_KEY })Since we set the “async” attribute of the parameter dictionary to True, the API call that you made in the last step will run asynchronously. To check the status of the call at any point of time we define a function checkJobStatus() which accepts the Job-Id of the API call that you sent to the PDF.co Web API, and returns the status of the call which can be any of the: “working”, “failed”, “aborted”, “success”.
def checkJobStatus(jobId):
"""Checks server job status"""url = f"{BASE_URL}/job/check?jobid={jobId}"
response = requests.get(url, headers={ "x-api-key": API_KEY })
if (response.status_code == 200):
json = response.json()
return json["status"]
else:
print(f"Request error: {response.status_code} {response.reason}")
return NoneThough the checkJobStatus() method is defined first, you should execute the following script immediately after you make a call to the Web API using the post() method. The following script gets the JSON data from the response object returned by the post() method.
If the response status code is 200, and the error is False, a loop executes which checks the status of the call via the checkJobStatus() method. When the checkJobStatus() method returns “success” as the status value, the ULR of the newly converted searchable PDF form is printed on the console.
searchable_pdf_url = ""
if (response.status_code == 200):
json = response.json()
if json["error"] == False:
jobId = json["jobId"]
resultFileUrl = json["url"]
while True:
status = checkJobStatus(jobId) # Possible statuses: "working", "failed", "aborted", "success".
print(datetime.datetime.now().strftime("%H:%M.%S") + ": " + status)
if status == "success":
searchable_pdf_url = resultFileUrl
break;
print(searchable_pdf_url)In the output below you can see the API call status along with time.
17:53.15: working
17:53.16: working
17:53.17: working
17:53.18: working
17:53.18: working
17:53.19: working
17:53.20: working
17:53.21: success
https://pdf-temp-files.s3.amazonaws.com/cb45d02dd34f4d65b231c036e3c5fa5b/result.pdfNow if you try to search and select text within your PDF form, you will be able to do so.
Step 2: Filling a PDF Form
Filling a PDF form using PDF.co Web API in Python is straightforward. You have to define some parameter values as shown below. You have seen most of them already in the first section except FieldsStrings.
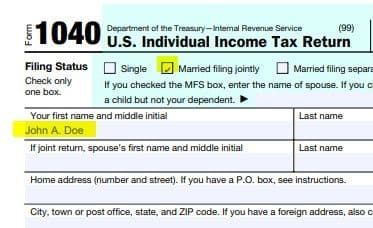
The FieldsStrings parameter specifies the form field ids, along with the text that you want to enter in those fields. In the following script the first name field is set to “John A. Doe”, the “Married filing jointly” text box is set to true, and some value for the social security number is entered.
Also, we make the API call synchronously as the “Async” parameter is set to false. You can set it to True if you prefer.
import os
import requestsAPI_KEY = "***********************************************"
BASE_URL = "https://api.pdf.co/v1"
SourceFileUrl = "https://bytescout-com.s3-us-west-2.amazonaws.com/files/demo-files/cloud-api/pdf-form/f1040.pdf"
FieldsStrings = "1;topmostSubform[0].Page1[0].f1_02[0];John A. Doe|1;topmostSubform[0].Page1[0].FilingStatus[0].c1_01[1];true|1;topmostSubform[0].Page1[0].YourSocial_ReadOrderControl[0].f1_04[0];123456789"
Async = "False"
DestinationFile = ".\\result2.pdf"The rest of the steps are similar to the first section. The following script creates a parameter dictionary.
parameters = {}
parameters["name"] = os.path.basename(DestinationFile)
parameters["url"] = SourceFileUrl
parameters["fieldsString"] = FieldsStrings
parameters["async"] = AsyncThe following script defines the URL for the API call.
url = "{}/pdf/edit/add".format(BASE_URL)And the script below uses the post() method to send the API call.
response = requests.post(url, data=parameters, headers={ "x-api-key": API_KEY })From the response JSON returned by the post() method you can extract the URL of the filled PDF form as shown below:
filled_pdf_url = ""
if (response.status_code == 200):
json = response.json()if json["error"] == False:
# Get URL of result file
filled_pdf_url = json["url"]
print(filled_pdf_url)If you open the form, you will see the filled PDF form fields that you specified in the API call to PDF.co Web API, as shown below.
Step 3: Extract PDF Forms Filled Info
Finally, you can also extract form fields, along with the field values from a PDF form using the PDF.co Web API in Python.
The process is similar to what you have seen before. You have to import some Python libraries and then initialize some variables as shown in the script below.
import os
import requestsAPI_KEY = "***********************************************"
BASE_URL = "https://api.pdf.co/v1"
SourceFileURL = "https://pdf-temp-files.s3.amazonaws.com/966872f9d8ac477e96e5cf55e64808dc/result2.pdf"
Async = "False"
DestinationFile = ".\\result3.pdf"The next step is to create a parameter dictionary as shown below:
parameters = {}
parameters["async"] = Async
parameters["name"] = os.path.basename(DestinationFile)
parameters["url"] = SourceFileURLThe following script defines the URL call for the API that extracts form field info from a PDF document.
url = "{}/pdf/info/fields".format(BASE_URL)Finally, the parameter dictionary, the URL for the API call, and the API key are passed to the post() method to send an API call to the PDF.co Web API.
response = requests.post(url, data=parameters, headers={ "x-api-key": API_KEY })The response JSON object can be printed as text using the following script:
print(response.text.encode('utf8'))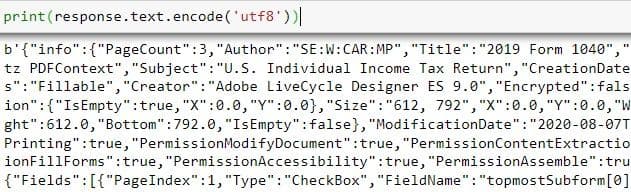
From the above output, it is difficult to view the form fields along with their values.
The following script iterates through all the form fields and corresponding values in the form and prints them on the console.
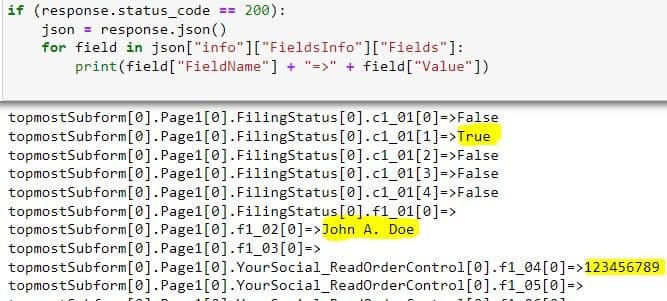
if (response.status_code == 200):
json = response.json()
for field in json["info"]["FieldsInfo"]["Fields"]:
print(field["FieldName"] + "=>" + field["Value"])In the output below, you can see form fields along with their values. You can see the highlighted values that you used to fill the PDF form in the previous section.
PDF.co Web API allows Python developers to integrate various PDF-related functionalities in their applications. In this article, you saw three such functionalities where you first converted a non-searchable PDF form to searchable format, you then filled PDF form fields using the API call to PDF.co Web API. Finally, you saw how to extract information about form fields and values via a call to PDF.co Web API from a Python application.
Related Tutorials
