How to Convert PDF to HTML Using PDF.co API
In this article, we’re going to see how to convert PDF to HTML using the PDF.co web API. The URL for the API is Convert to HTML and this method basically converts PDF, PNG, or JPG documents to the HTML. We can have the two versions like the GET and POST request. It’s supposed to do both and it automatically preserves the layout vector’s image formatting. So it will take care of all the things.
Step 1: Enter API Key and Open the PDF or its URL
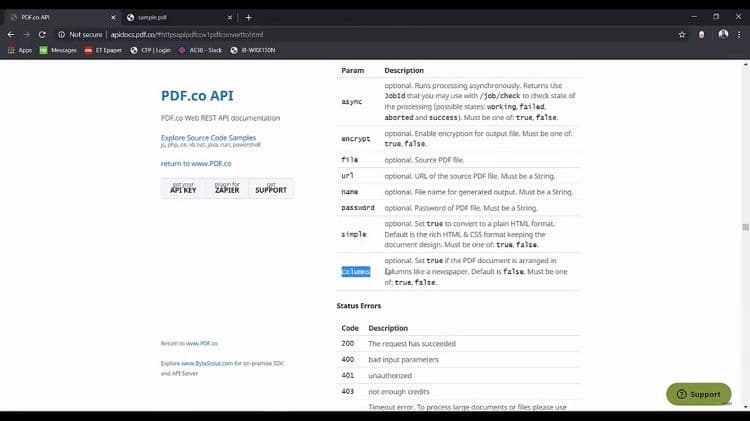
We can have the async version of these files also. If the PDF file is weak, we should have the async version because it gives us a job ID. And it will take time to run, so we can periodically come here and check the status of the job if it is completed or not. If you want to output the file as an encrypted version, we can enable this file. We can provide the input file in two ways. We can either provide the file or the URL of the PDF.
This is the optional output file, the name of the file. If the PDF file is password protected, we should set this password parameters here. By default simple parameter is false, but if we want to have the plain HTML as the output then we can set simple parameters to true.
Step 2: Set the Input Parameters and Send the Query Path Convert to HTML
If our PDF files have the column formatted enable like the newspaper, it has the columns – we should enable column parameters and let us see this in action.
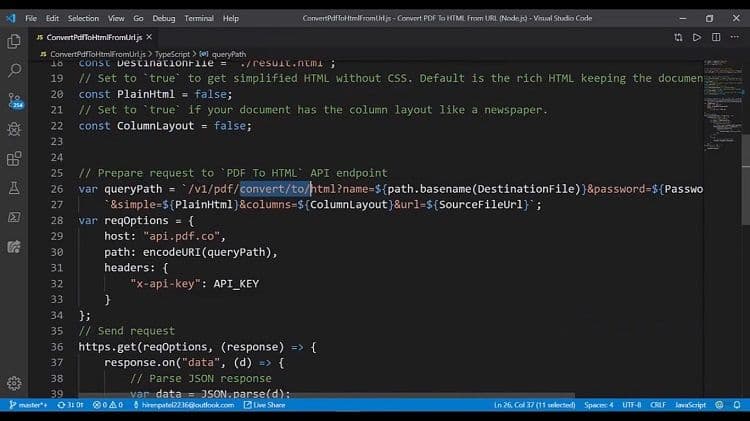
Here we have the input file. We have the standard invoice as input. Then we have the pages, the password destination file. We have enabled the plain HTML to false. We have enabled the column layout to false. We’re generating the query path here. So we have the convert to HTML and we provide the different parameters, like the name, password, pages, simple columns, and URL.
Step 3: Grab and Store Destination File and Check Result
We generate the request option here. We provide the host here. We have the query string in the path parameter and we provide the header file. We enable the GET response and once record the data, we are converting to the JSON. If JSON doesn’t have any error, we are grabbing the destination file and we are going to store it.
So let us see this in action and fire up the terminal. So it’s executing and successfully generated result.html file. Let us see using Explorer and here it is.
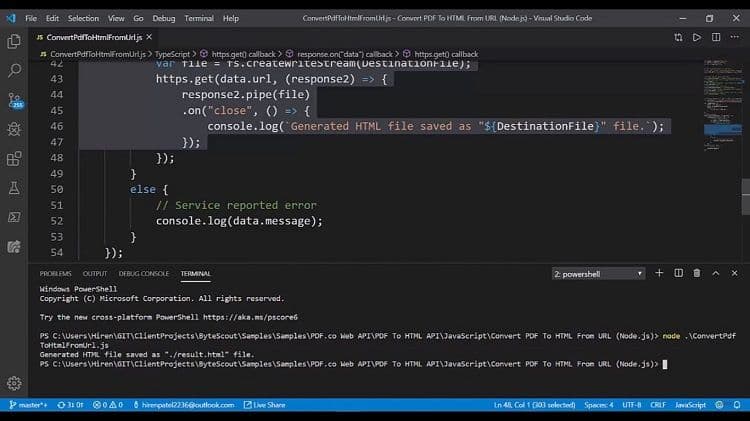
Basically, this is the HTML file, but it has preserved all the formatting of the PDF file. So it’s that easy to convert to any HTML, any PDF to HTML format using the PDF.co web API.
Check this PDF.co video tutorial on how to use PDF.co Web API and follow us on YouTube!
Video Guide
Related Tutorials

