Split Large PDF with Multiple Pages and Parse each Page using PDF.co and Make
Splitting a large PDF with multiple pages and parsing each page individually can be a challenging and time-consuming task when done manually. However, you can simplify the process by utilizing the capabilities of PDF.co and Make. These powerful tools allow you to efficiently divide the PDF into distinct pages and parse the valuable data within each page.
With the combination of PDF.co and Make, you have the capability to parse and extract the desired information from each page of the split PDF. PDF.co offers a wide range of extraction options to meet your specific requirements. Smoothly iterating through each split page, the process of extracting the relevant content is automated easily.
In this guide, we will explore how to effectively split a large PDF with multiple pages and parse each page individually, all made possible by the combination of PDF.co and Make. These tools provide a smooth solution, allowing you to effectively divide the PDF into separate pages and extract the valuable content within each page.
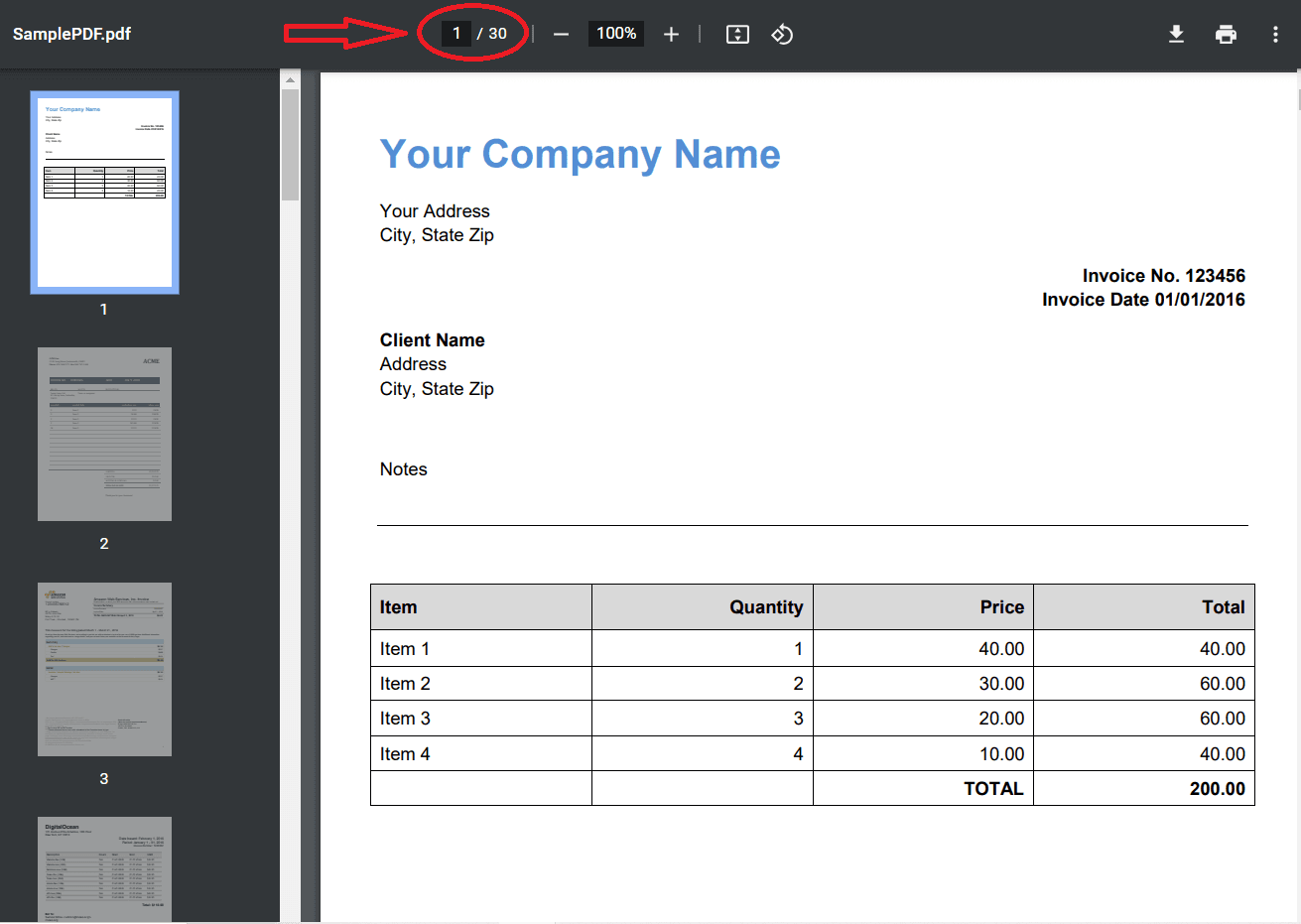
We will split this sample large PDF with multiple pages into individual files and parse each page separately. By following the steps outlined, you’ll learn how to effectively divide the PDF into individual pages and extract the desired information from each page.
Step 1: Create a New Scenario
- To begin, log into your Make account and create a new scenario.
Step 2: Add PDF.co Module
- Next, search and select the PDF.co app and choose the Make an API Call module. This will allow us to access and utilize the functionalities and data provided by the API.
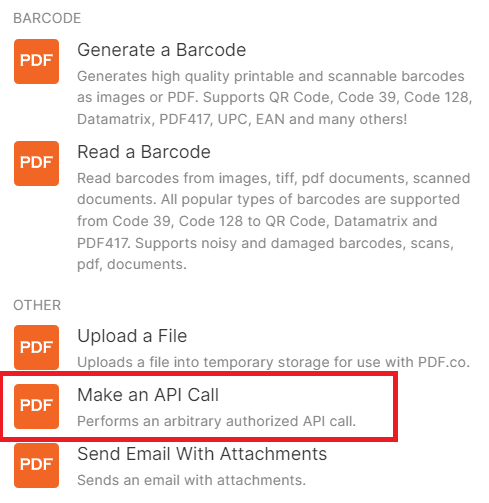
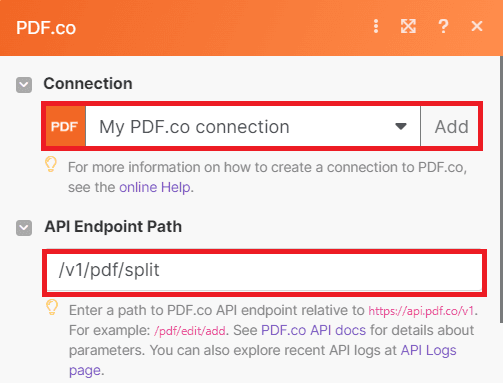
Step 3: Setup PDF.co Configuration
Let’s set up the PDF.co configuration.
- Start by connecting your PDF.co account to Make. Add the API Key, which can be obtained from your PDF.co dashboard or by signing up at this link.
- In the API Endpoint Path field, enter the endpoint for splitting PDF pages. This specific endpoint allows us to split multiple pages into individual files.
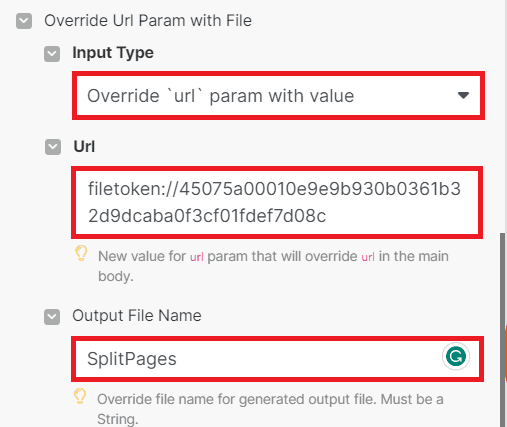
- In the Input Type field, choose the Override URL param with value option. This selection enables you to directly input the URL of the source file.
- For the URL field, input the link of the source file. If you’re using a file instead of a URL, you have the option to utilize PDF.co File Storage. This service can store your file and convert it into a URL that is exclusively used for PDF.co processes.
- Then, provide a name for the desired output file.
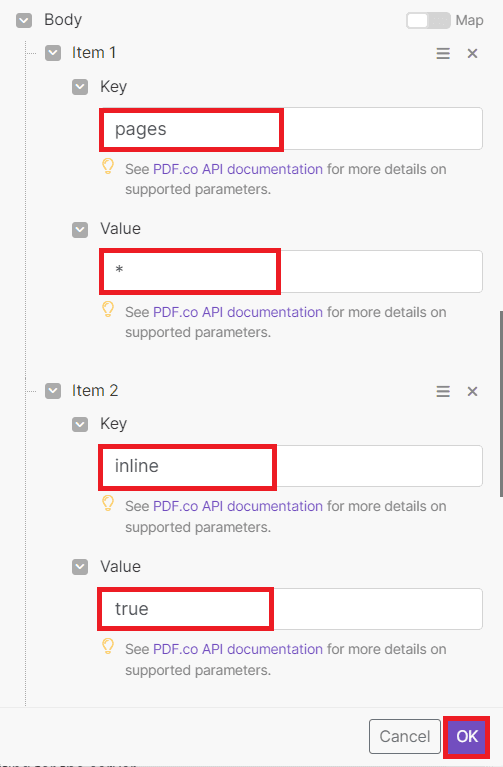
- In the Body param section, for Item 1, specify pages as the Key and use an asterisk (*) as the value. Including the asterisk ensures that all pages will be split into individual files.
- For Item 2, enter inline as the Key and set the value to true. Setting the value of inline to true will result in the inclusion of the response’s results within the response itself.
After setting up the configuration, run the scenario to split the pages into individual files.
Step 4: Split Pages Result
- Great! We successfully split PDF pages into individual PDF files. We will now add the Iterator tools to iterate the details of the files and process the collection as a whole.

Step 5: Add Iterator Tools
- In this step, we will incorporate Iterator tools, which will enable us to access the details of all files and perform operations on each file as a whole.
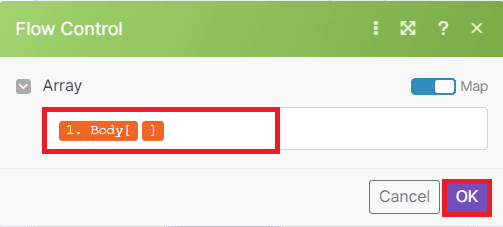
Step 7: Run Iterator Result
- The scenario has been executed successfully and has returned the Iterator value. Now, we can proceed to add another module and parse each file individually.
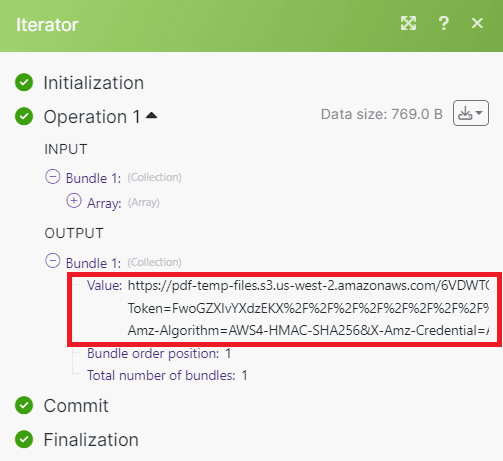
Step 8: Add Another PDF.co Module
- In this step, we will incorporate an additional module by selecting the PDF.co app. From there, we will choose the Parse a Document option, allowing us to parse the data of each file individually.
Step 9: Configure PDF.co Settings
Let’s proceed with configuring the PDF.co settings.
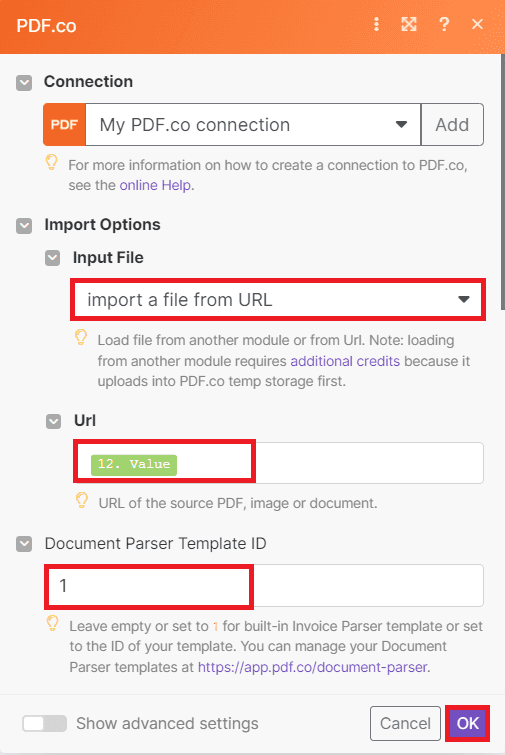
- First, select the Import a file from URL option in the Input File field to utilize the Iterator response value.
- Next, select the Iterator response value for the URL field.
- Then, enter the ID of the template containing the parsed data in the Document Parser Template ID field. You can create a template ID using the PDF.co Document Parser Template Editor. For a quick tutorial on template creation, refer to the provided link.
Once the configuration is set up, proceed to execute the scenario in order to parse the data of each file individually.
Step 10: Parse Document Result
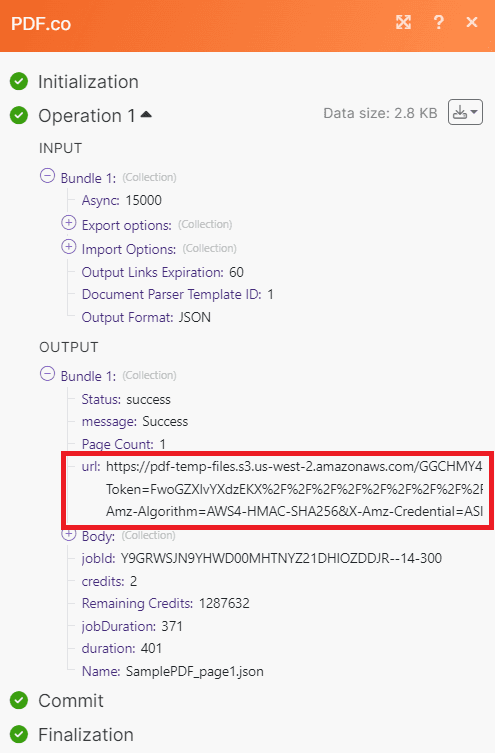
- Excellent! PDF.co successfully processes our request and parse the data of each file. Copy the URL and paste it into your browser to view the output.
Step 11: Parsed Data Value
- Here’s the parsed data value in JSON format.

In this tutorial, you have learned valuable techniques for splitting large PDF files with multiple pages and parsing the data of each page using PDF.co and Make. You gained insights into utilizing the PDF.co PDF Split features to efficiently divide multiple pages into separate files. Additionally, you explored the powerful capabilities of the PDF.co Document Parser to extract and process data from PDF documents. By combining these features, you have expanded your knowledge of effectively working with PDF files and extracting valuable information.
Video Guide
Related Tutorials
