How to Parse Invoice using Salesforce Apex using PDF.co
In this step-by-step guide, we’ll briefly see steps on how to parse invoice files using Document Parser in Salesforce Apex using PDF.co. Initially, we’ll go through all the basic steps of Salesforce integration. Later we’ll also see the code and demo video. Let’s get started!
Step 1: Create Remote Site Settings
Create one remote site settings in the Salesforce Org like below.
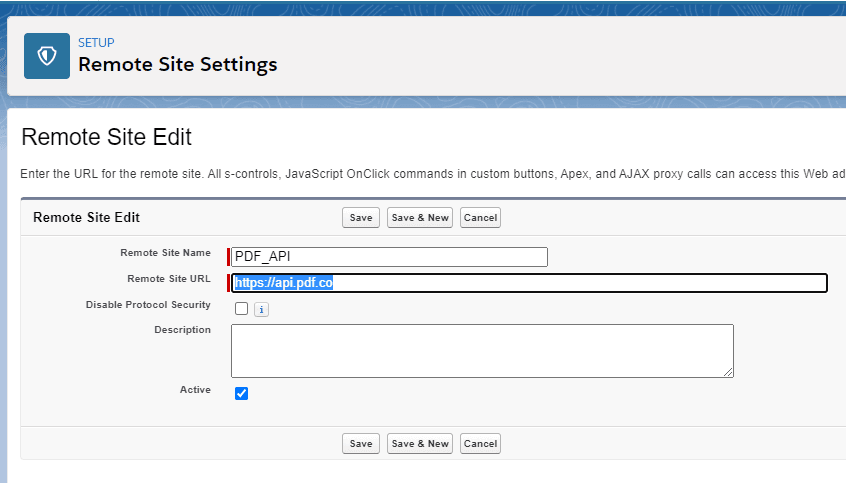
Note that the URL is “https://api.pdf.co”.
Step 2: Create an Apex Class in Salesforce
Create an apex class in Salesforce like below and paste the code there.
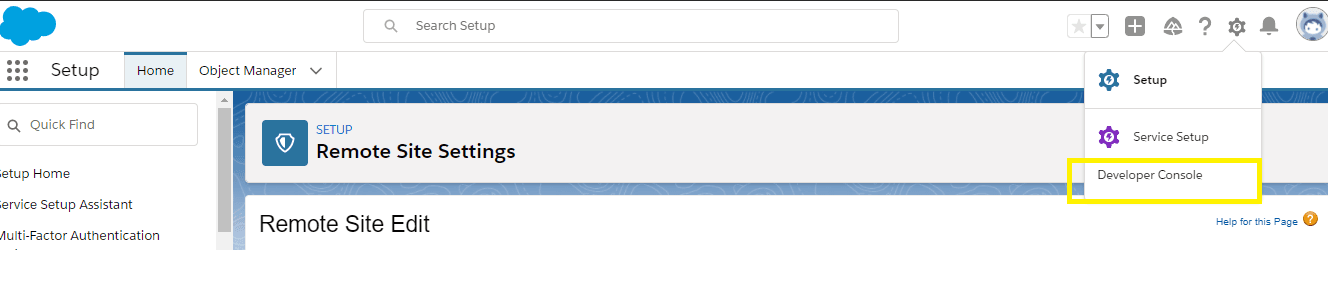
Once you login to the Salesforce org, you will see the screen like below and click on “Developer Console”
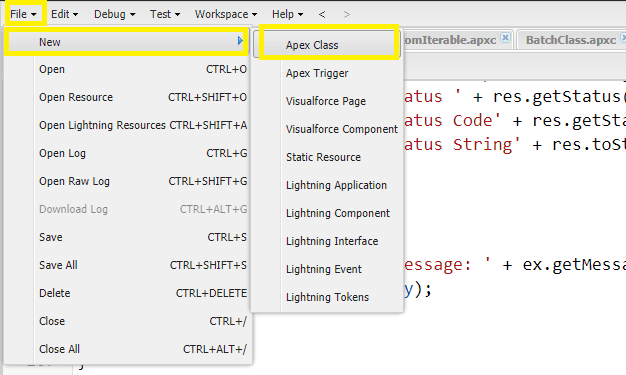
Create an apex class. For this, click on “Files” then “New” then “Apex Class”.
Write the class name “DocumentParserOutputAsJSON” and click “Ok”. Now copy the DocumentParserOutputAsJSON code in this file.
Similarly, create a new file with the name “DocumentParserOutputAsJSONTest” and copy the code.
Step 3: Enter API Key
In the DocumentParserOutputAsJSON file, please add the PDF.co API key by replacing the ‘******************************************’.

Step 4: Verify Code
To Verify the code, please open the execute Anonymous window and call the method like below.
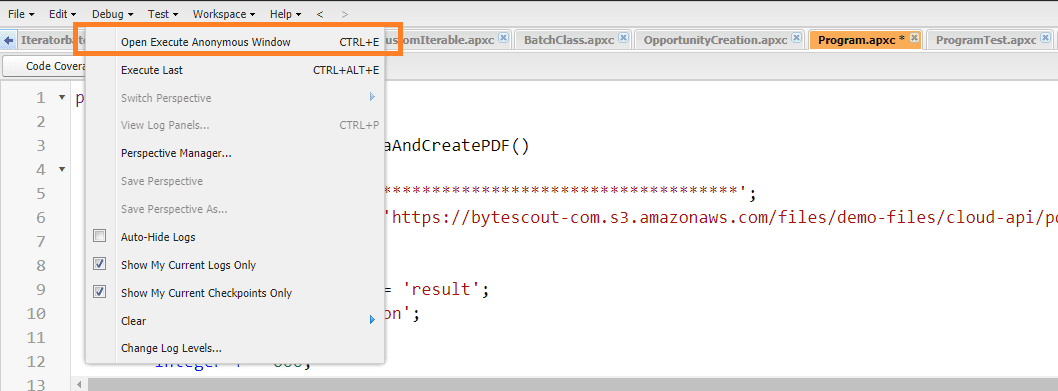
Then Click on “Execute”.
Step 5: Check the Output
Now, You will see the output in the debug log.
Step 6: Source Code Files:
DocumentParserOutputAsJSON.cls
public class DocumentParserOutputAsJSON {
// The authentication key (API Key).
// Get your own by registering at https://app.pdf.co/documentation/api
static String API_KEY = '***********************';
// Direct URL of source PDF file.
static string SourceFileUrl = 'https://bytescout-com.s3-us-west-2.amazonaws.com/files/demo-files/cloud-api/document-parser/sample-invoice.pdf';
// PDF document password. Leave empty for unprotected documents.
static string Password = '';
@TestVisible
String jsonOutput;
public void parseDocumentAsJSON()
{
try
{
// Create HTTP client instance
Http http = new Http();
HttpRequest request = new HttpRequest();
// Set API Key
request.setHeader('x-api-key', API_KEY);
Boolean async = false;
String inline = 'true';
String profiles = '';
Boolean encrypt = false;
Boolean storeResult = false;
// Prepare requests params as JSON
// See documentation: https://docs.pdf.co
// Create JSON payload
JSONGenerator gen = JSON.createGenerator(true);
gen.writeStartObject();
gen.writeStringField('url', SourceFileUrl);
gen.writeStringField('outputFormat', 'JSON');
gen.writeStringField('templateId', '1');
gen.writeBooleanField('async', async);
gen.writeBooleanField('encrypt', encrypt);
gen.writeStringField('inline', inline);
gen.writeStringField('password', password);
gen.writeStringField('profiles', profiles);
gen.writeBooleanField('storeResult', false);
gen.writeEndObject();
// Convert dictionary of params to JSON
String jsonPayload = gen.getAsString();
// URL of 'PDF Edit' endpoint
string url = 'https://api.pdf.co/v1/pdf/documentparser';
request.setEndpoint(url);
request.setHeader('Content-Type', 'application/json;charset=UTF-8');
request.setMethod('POST');
request.setBody(jsonPayload);
// Execute request
HttpResponse response = http.send(request);
if(response.getStatusCode() == 200)
{
// Parse JSON response
Map<String, Object> json = (Map<String, Object>)JSON.deserializeUntyped(response.getBody());
if ((Boolean)json.get('error') == false)
{
jsonOutput = response.getBody();
System.debug('JSON '+ jsonOutput);
}
}
else
{
System.debug('Error Response ' + response.getBody());
System.Debug(' Status ' + response.getStatus());
System.Debug(' Status Code' + response.getStatusCode());
System.Debug(' Response String' + response.toString());
}
}
catch (Exception ex)
{
String errorBody = 'Message: ' + ex.getMessage() + ' -- Cause: ' + ex.getCause() + ' -- Stacktrace: ' + ex.getStackTraceString();
System.Debug(errorBody);
}
}
}DocumentParserOutputAsJSONTest.cls
@isTest
public class DocumentParserOutputAsJSONTest
{
private testmethod static void testparseDocumentAsJSON()
{
Test.setMock(HttpCalloutMock.class, new DocumentParserOutputAsJSONTest.DocumentCreationMock());
DocumentParserOutputAsJSON docParse = new DocumentParserOutputAsJSON();
docParse.parseDocumentAsJSON();
System.assert(docParse.jsonOutput.contains('John A. Doe'));
}
private testmethod static void testparseDocumentAsJSONException()
{
DocumentParserOutputAsJSON docParse = new DocumentParserOutputAsJSON();
docParse.parseDocumentAsJSON();
System.assert(null == docParse.jsonOutput);
}
public class DocumentCreationMock implements HttpCalloutMock {
public HTTPResponse respond(HTTPRequest req) {
HttpResponse res = new HttpResponse();
String testBody = '{"hash":"John A. Doe","url":"https://pdf-temp-files.s3-us-west-2.amazonaws.com/0c336bfcef1a473d98492bda25d8da03/newDocument.pdf?X-Amz-Expires=3600&x-amz-security-token=FwoGZXIvYXdzEO7%2F%2F%2F%2F%2F%2F%2F%2F%2F%2FwEaDHWK1dY4d4lOgsheliKBATwE%2FZewASPTEnPxTn%2BOdYhP4h3gljAJfqbRvQptDX7wdWLmrBS7Tg4qTU6pAbxIdXChGPjBWpSbtiADJKmqkmyhkUmE8GSM1%2FGtJO6bga2pgzvFLXmzxjTf3%2BFNqwYOvbyApIZdVLoPpEKY6PlCflQtLTd30dhelm6xpB8pitbdhSjdz8KCBjIobVy%2Fjwybwp6OQgB%2FT6QkIo2dU07gtFREdn5jhRyvnS5lkccweBV1%2Bw%3D%3D&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=ASIA4NRRSZPHMV5P3JOS/20210316/us-west-2/s3/aws4_request&X-Amz-Date=20210316T124309Z&X-Amz-SignedHeaders=host;x-amz-security-token&X-Amz-Signature=95287bf3c007fed4c2c5aeea1ce75c846cc6c68b22aaf35175ebe41a105f54e1","pageCount":1,"error":false,"status":200,"name":"newDocument","remainingCredits":9913694,"credits":3}';
res.setHeader('Content-Type', 'application/json');
res.setBody(testBody);
res.setStatusCode(200);
return res;
}
}
}Learn how you can extract data from PDF invoices using PDF.co API and Salesforce integration.
Video Guide
Related Tutorials
