Extract Text Content from PDF or XPS in C#
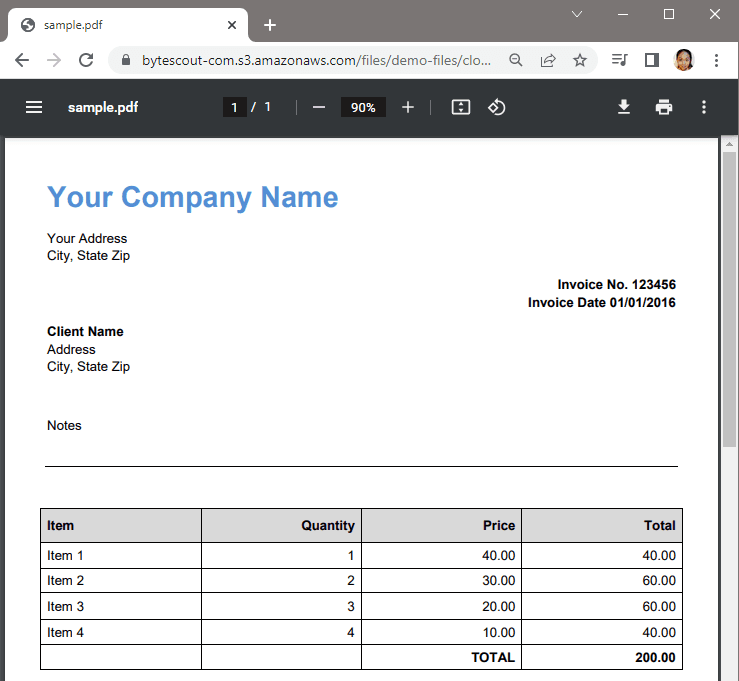
In this tutorial, we will show you how to extract text content from PDF in C# using the PDF.co PDF to Text Web API. Below is the PDF Invoice that we will convert to Text.
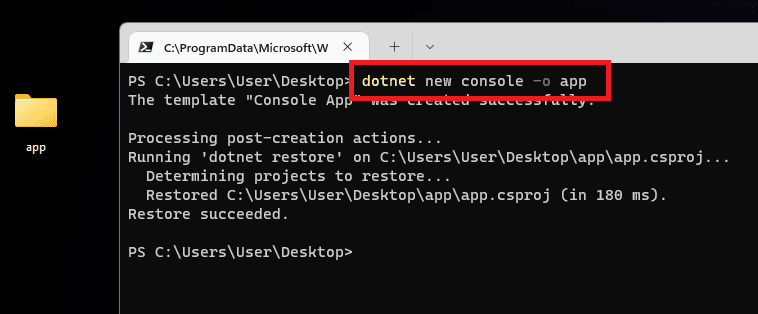
Step 1: Create New Project
To begin, let’s create a new project inside app folder using this command dotnet new console -o app.
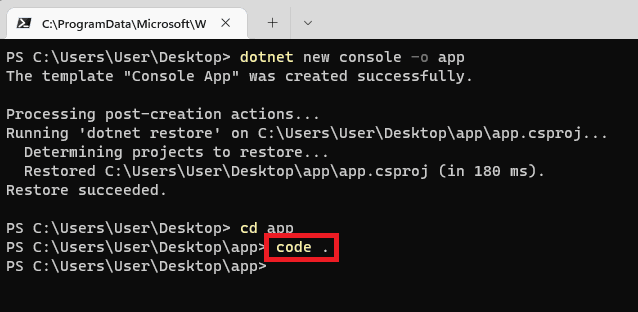
Step 2: Open VSCode
Type cd app to go to the folder and enter code . to open VSCode.
Step 3: Add Source Code
Let’s copy the PDF to Text from URL in C# source code from the documentation sample.
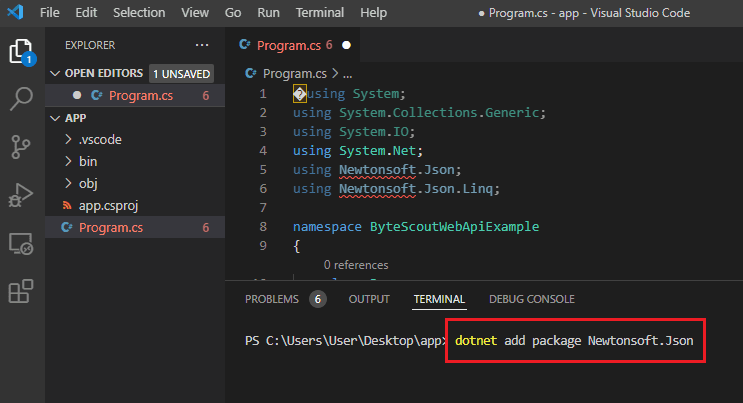
Step 4: Add Package
Then, let’s add a Newtonsoft.Json package using this command dotnet add package Newtonsoft.Json.
Step 5: Add API Key
Now, let’s add our PDF.co API Key in line 14. You can get your API Key in the PDF.co dashboard.

Step 6: Add Source File
In line 18, you can find the PDF Invoice URL. If you’d like to try your file, please replace the sample link.

Step 7: Add Destination File
In line 24, enter your desired output filename.

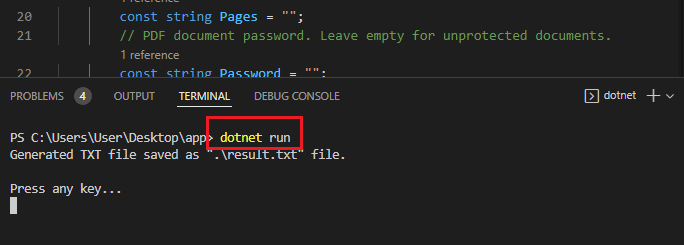
Step 8: Run Project
We are now ready to run the project. In the terminal type the command dotnet run.
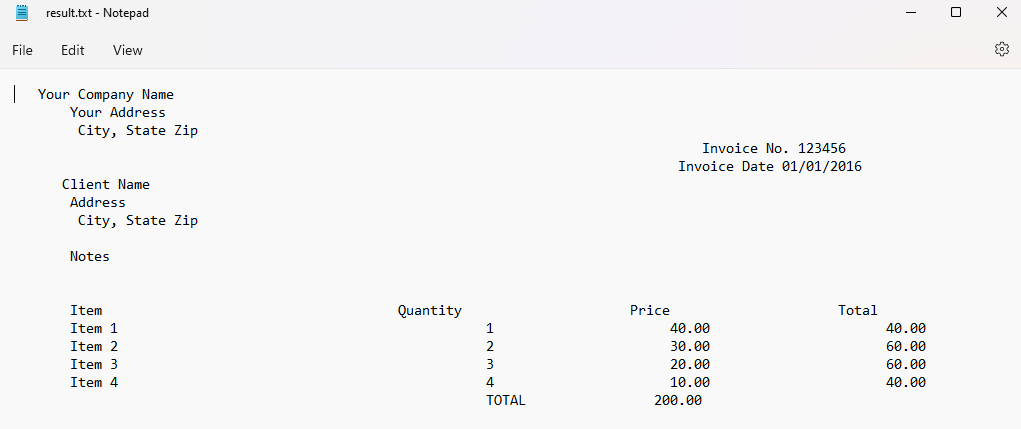
Step 9: Extracted Text Output
Here’s our extracted text output.
In this tutorial, you learned how to extract text from PDF in C# using PDF.co Web API. You learned how to create a new project in C#. You also learned how to add a Newtonsoft.Json package.
Related Tutorials
