How to Extract Data from PDF File Based on Keywords using PDF.co Document Parser
Extracting specific data from PDF files can be challenging, particularly when dealing with large documents or a high volume of files. PDF.co Document Parser offers a solution for extracting data from PDF files based on keywords.
PDF.co Document Parser is a powerful tool for data extraction that automates the extraction of data from PDF files, making the process faster, more accurate, and more efficient.
In this article, we will show you the capabilities of PDF.co Document Parser to easily extract relevant data from PDF files based on keywords, saving you time, effort, and resources.
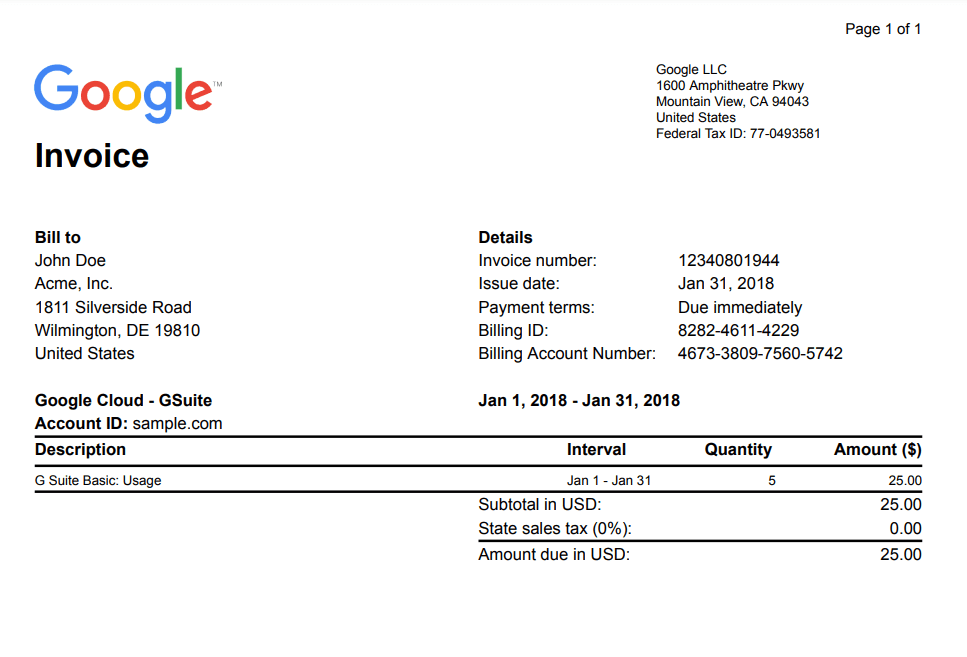
We will use this sample PDF document and extract data based on keywords using PDF.co Document Parser. So let’s begin!
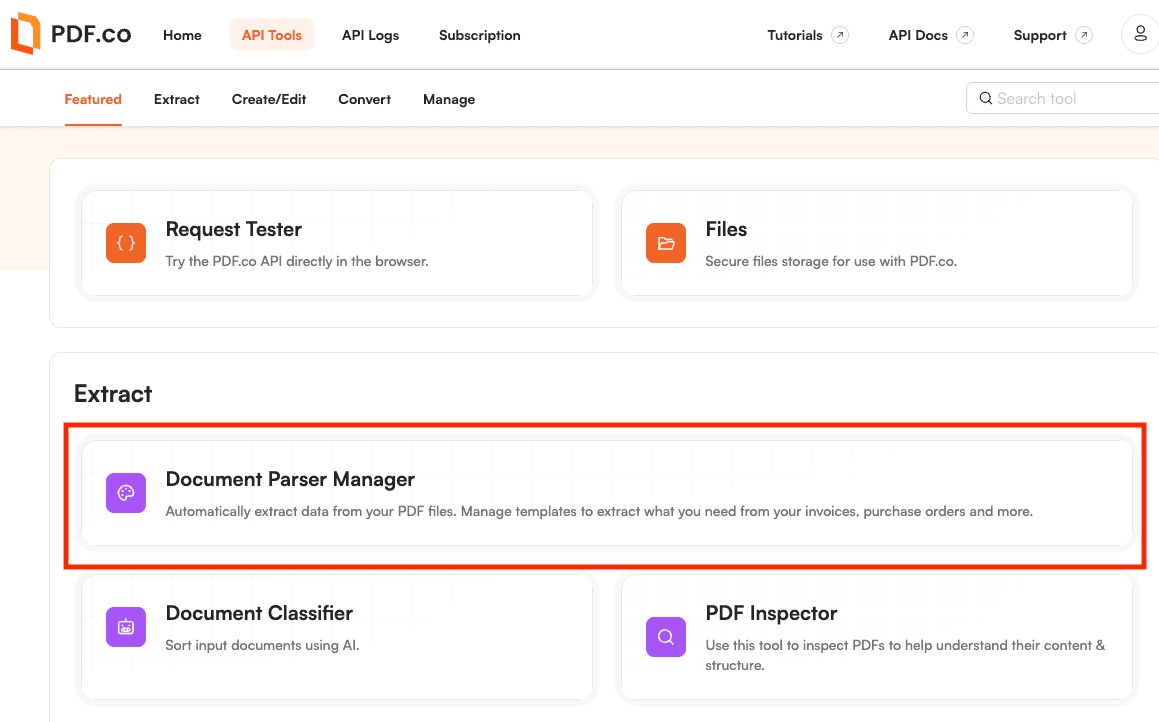
Step 1: Open Document Parser
To start, you will need to log in to your PDF.co account.
From the API Tools tab, select Document Parser.
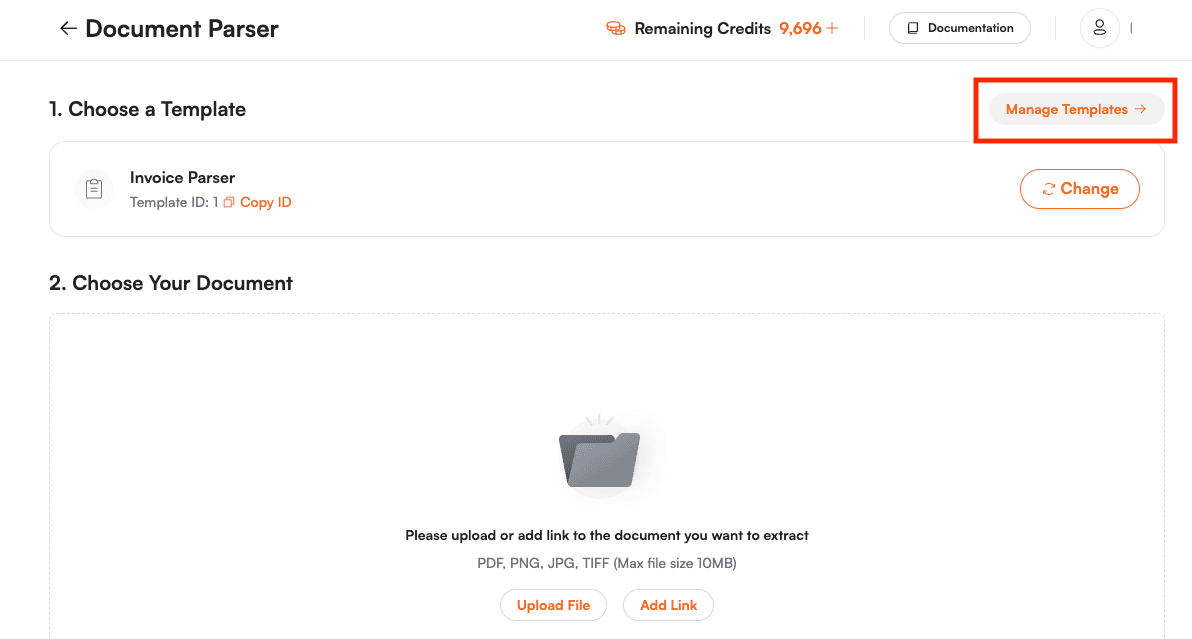
Step 2: Create New Template
Click on the Manage Templates button.
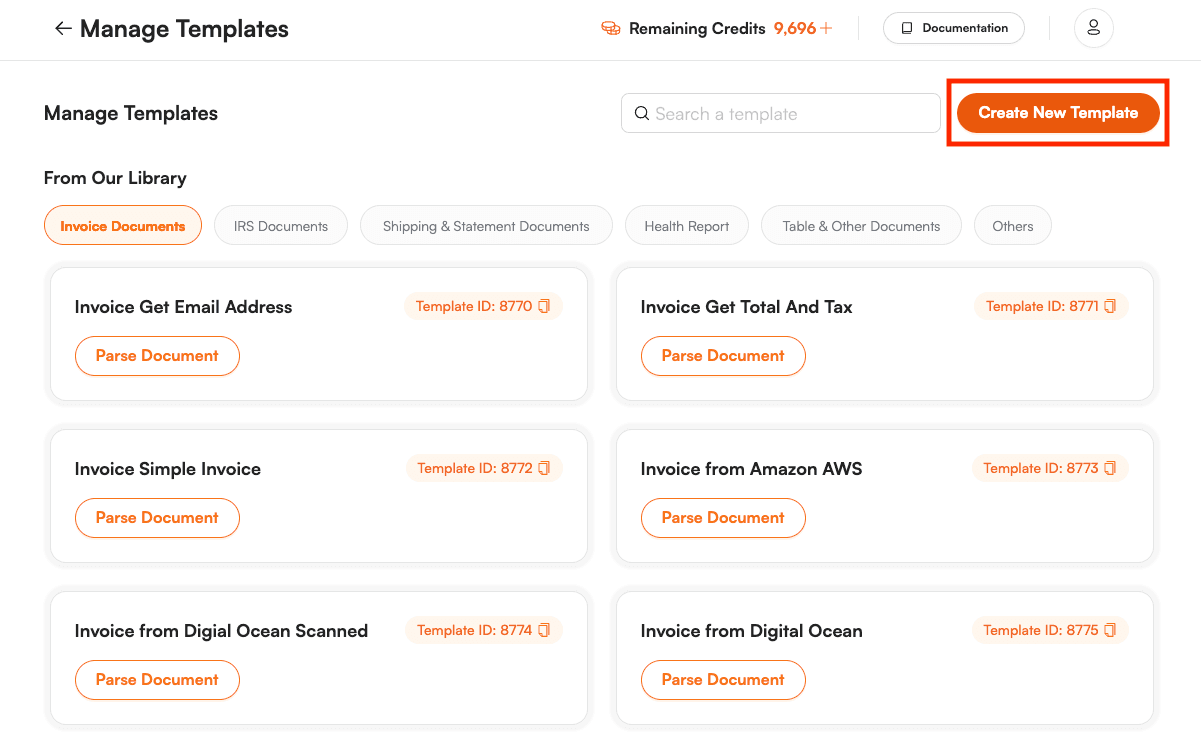
Next, click on the New Template button to create a new template.
Step 3: Load Test PDF or Image
On your Document Parser Template Editor, click on the Load Test PDF or Image button to upload the source file.
Next, click on the Add Object button and select Add Field from the Rectangle selection option.
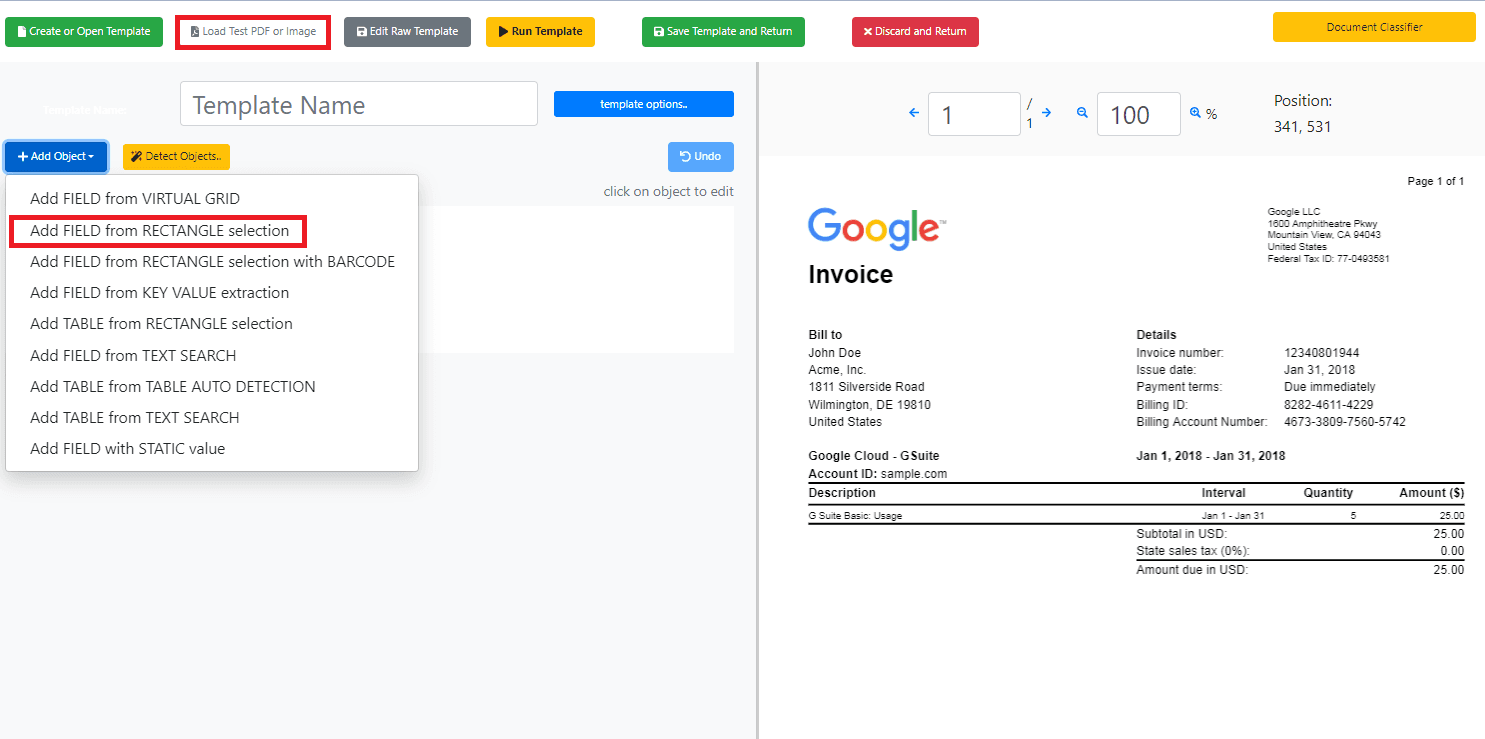
Step 4: Drag Rectangle to Extract Data
In the Document Parser Template Editor, drag the rectangle to the desired location on the PDF document where you want to extract keywords.
After selecting the keywords, run the template to see the results.
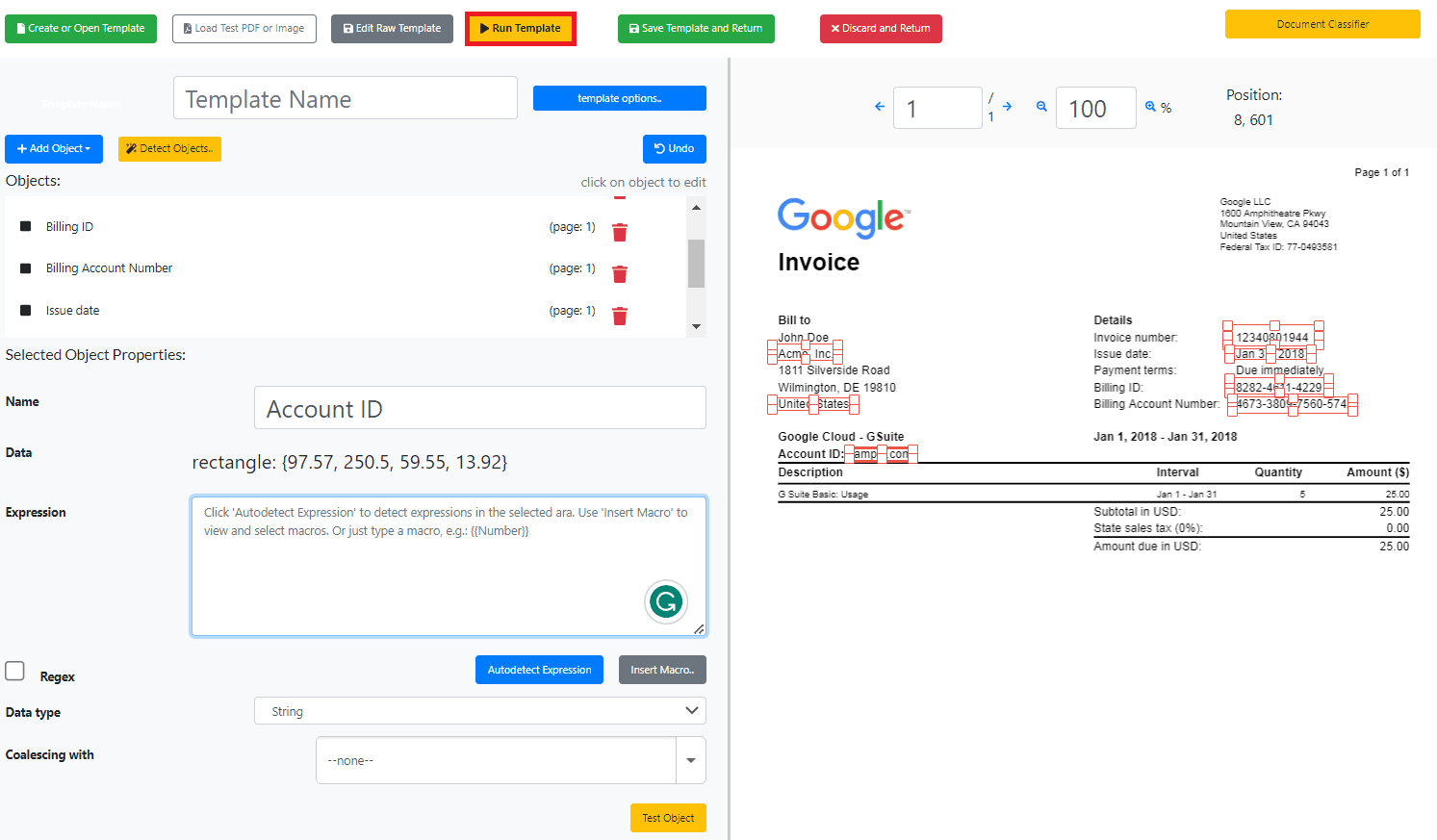
Step 5: Extracted Keywords Data
Here are the extracted keywords from the PDF document.
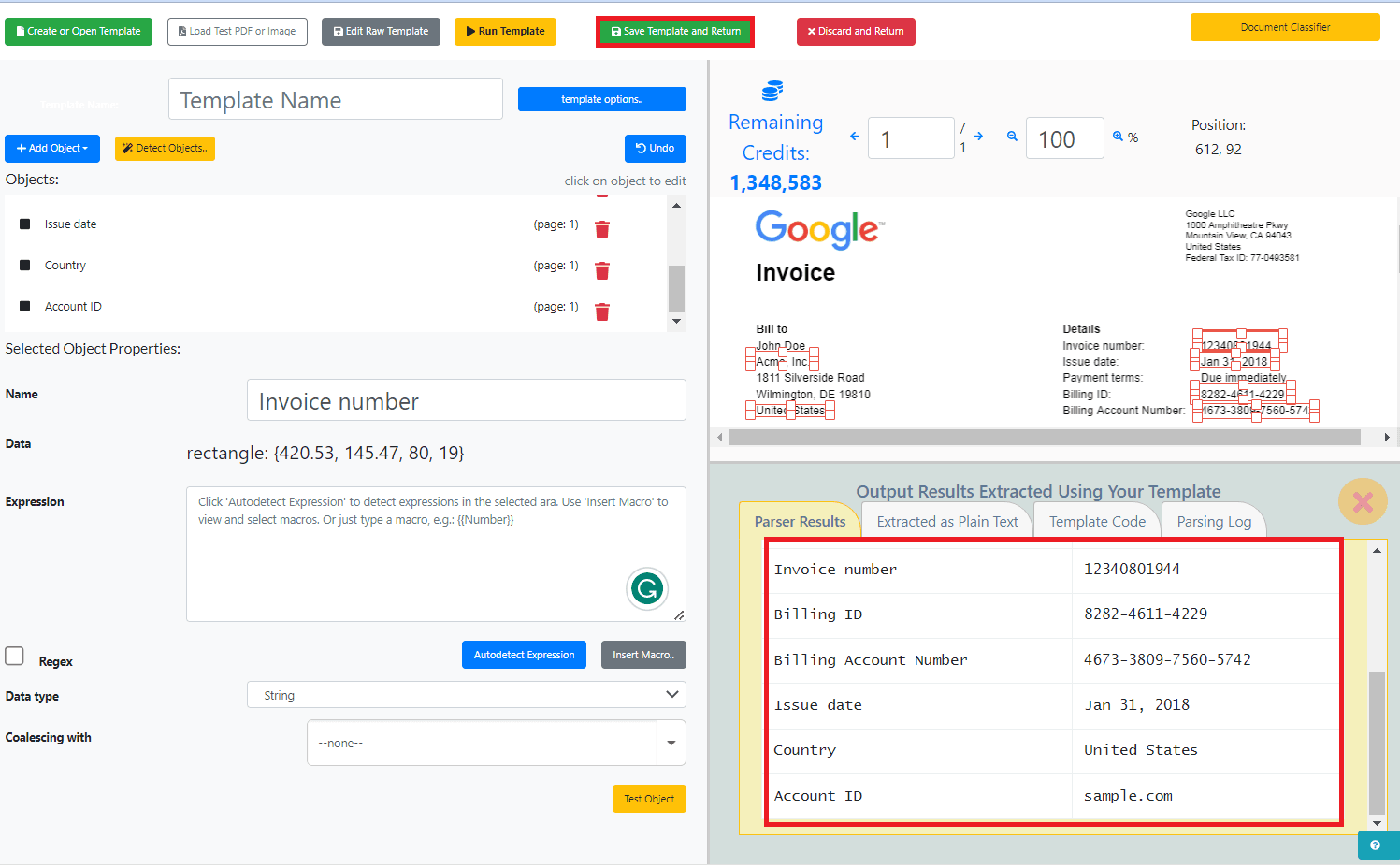
If you are satisfied with the output, click on the Save Template and Return button to save the template for future use.

Step 7: Setup Request Tester Tool
- In the PDF.co API Endpoint field, select the Document Parser endpoint. Choose the desired output format, such as JSON, XML, or CSV.
- Add your source PDF, either by providing a link or uploading a file.
- Include the TemplateID in the JSON code that contains the extracted keywords.
- Set Inline to true if you want the results to be included inside the response, or false if you want a link to the output file generated.
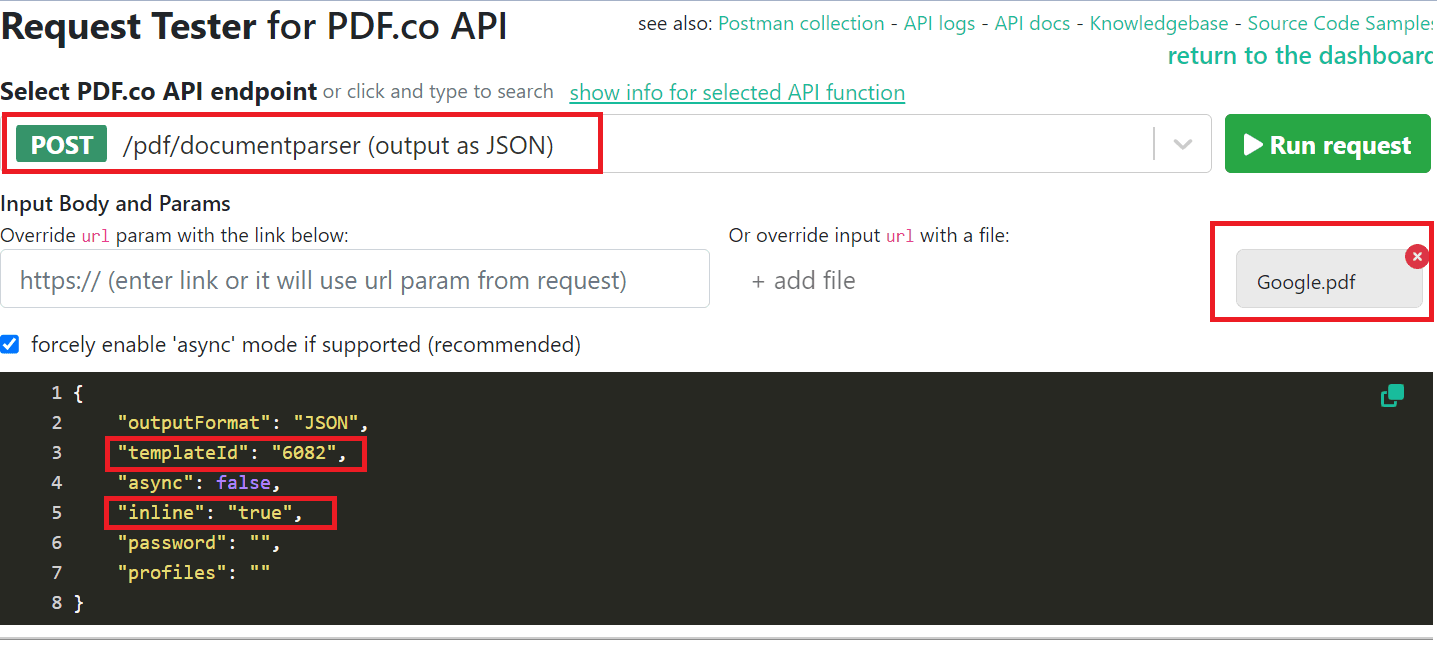
Once you have set up the parameters as desired, click on the Run Request button to send a request to PDF.co.
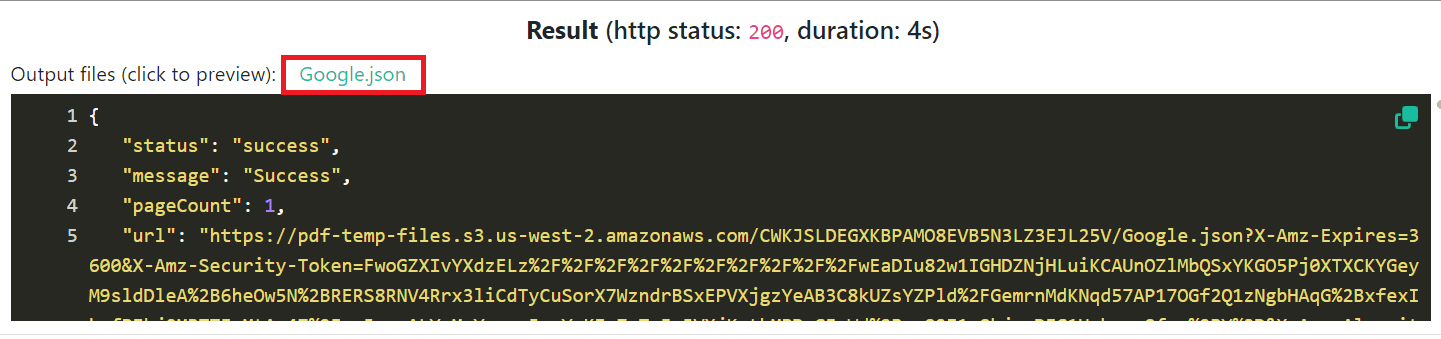
Step 8: Run Request Result
Great! The request runs successfully and returns a JSON file containing the extracted keywords data. Click on the JSON file to view the output and download it as a file for further use.
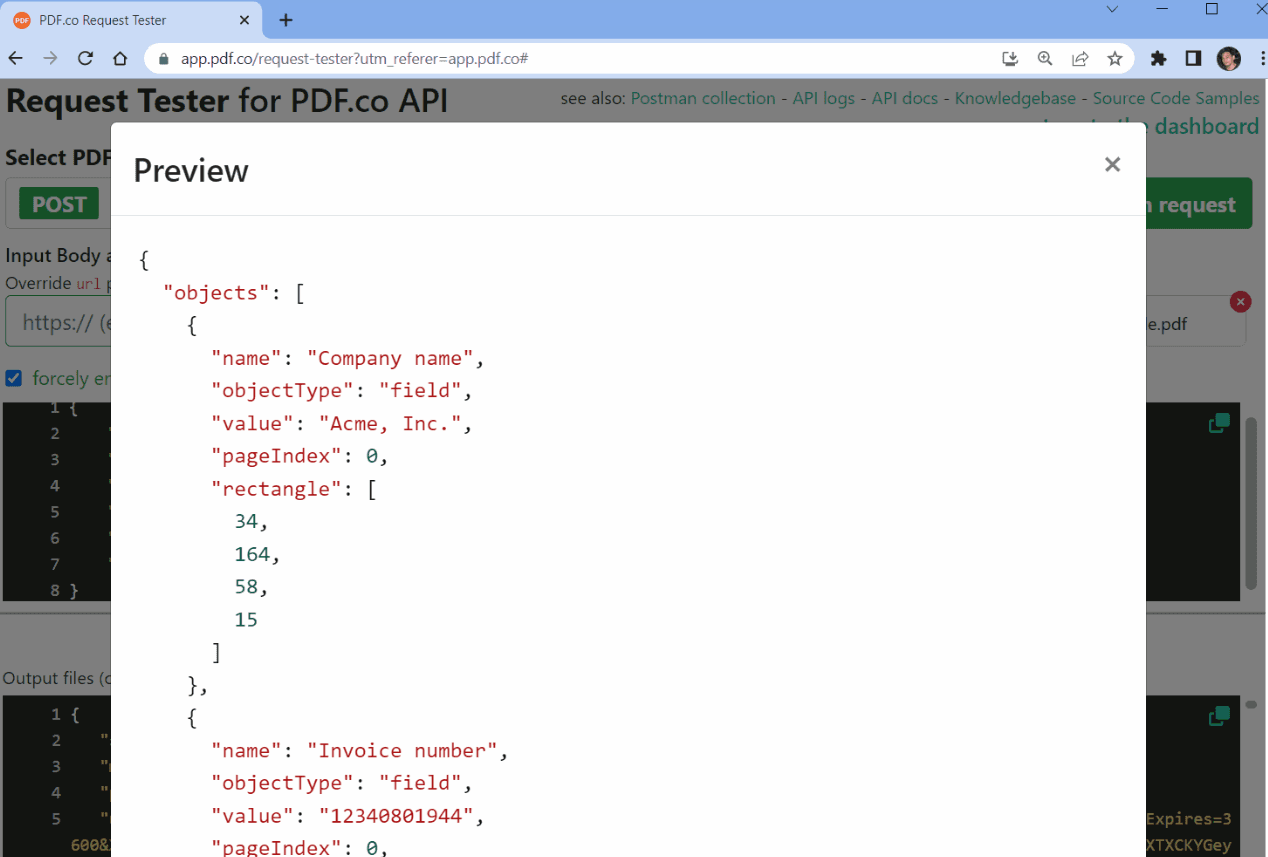
Step 9: JSON Output
Here’s the extracted keywords data from the PDF document in JSON format.
In this tutorial, you learned how to extract data from a PDF document based on Keywords using PDF.co Document Parser.
Related Tutorials

