If your Postman is not PDF.co ready, we have an easy-to-follow guide to help you set up your PDF.co Postman Collection.
How to Extract Text from Scanned PDF using Postman and PDF.co
4 Minutes Read
Step 1: Scanned PDF File
In this tutorial, we will show you how to use the Optical Character Recognition Mode to extract text from a scanned PDF file using Postman and PDF.co.
To easily identify the kind of document you have, you can use our PDF Multitool desktop app. As you can see in the screenshot below, our PDF document only contains images.
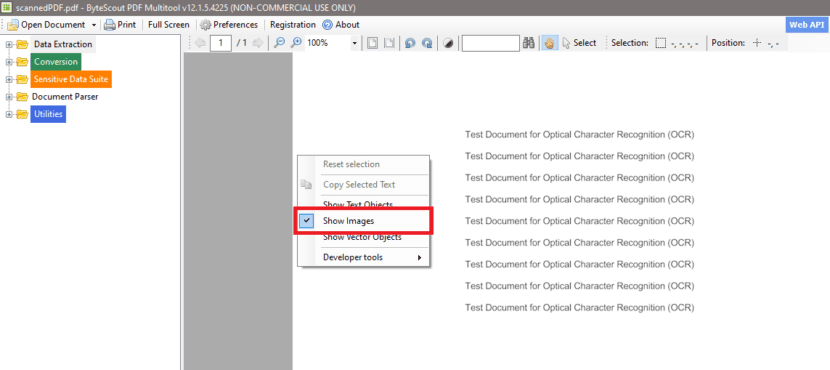
Step 2: Open PDF To Text Template
To begin, let’s open the POST /pdf/convert/to/text under the PDF to TEXT folder in the PDF.co API v.1.00 collection. This is a PDF to Text API template that you can use to try out the API right away.
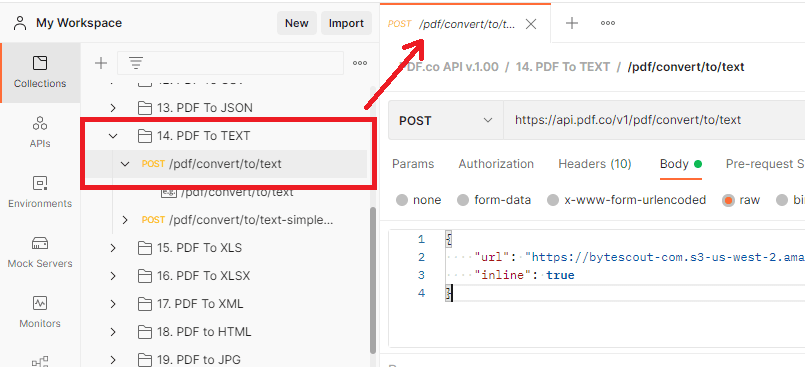
Step 3: Set Parameter Values
Let’s replace the default values with our own.
- In the url parameter, insert the scanned PDF file link.
- Let’s leave the inline parameter to true so we can see the text result within Postman.
- Add the profiles parameter and set the OCRMode to TextFromImagesOnly. This will run the OCR to extract text from images and ignores vector and text objects.
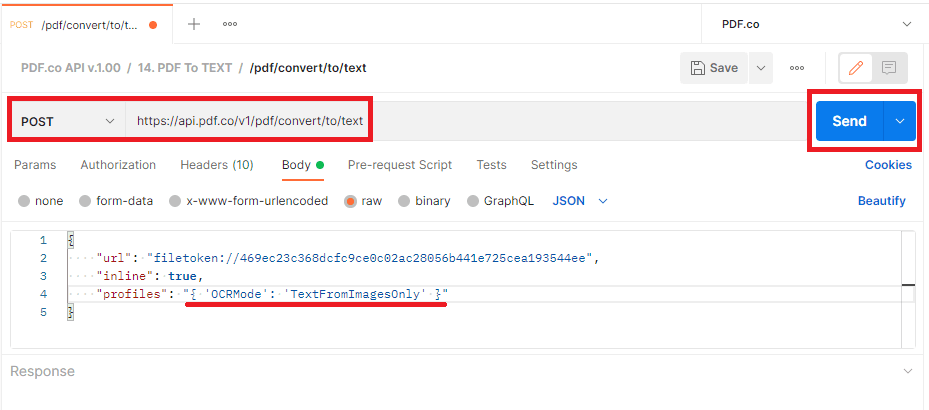
Once all values have been added, click on the Send button.
Below is the cURL code version.
curl --location --request POST 'https://api.pdf.co/v1/pdf/convert/to/text' \
--header 'Content-Type: application/json' \
--header 'x-api-key: YOUR_API_KEY' \
--data-raw '{
"url": "filetoken://469ec23c368dcfc9ce0c02ac28056b441e725cea193544ee",
"inline": true,
"profiles": "{ '\''OCRMode'\'': '\''TextFromImagesOnly'\'' }"
}'The PDF Multitool is packed with tons of tools. You can use it to convert PDF to Text. You can also find all the OCR Modes and test them with your document.
Step 4: Extracted Text From PDF
Great! We have extracted text from the scanned PDF file. You can set the inline to false to get a downloadable file instead. The URL is temporary and is set to expire after an hour by default. You have the option to increase output link expiration in our Business plan and higher.
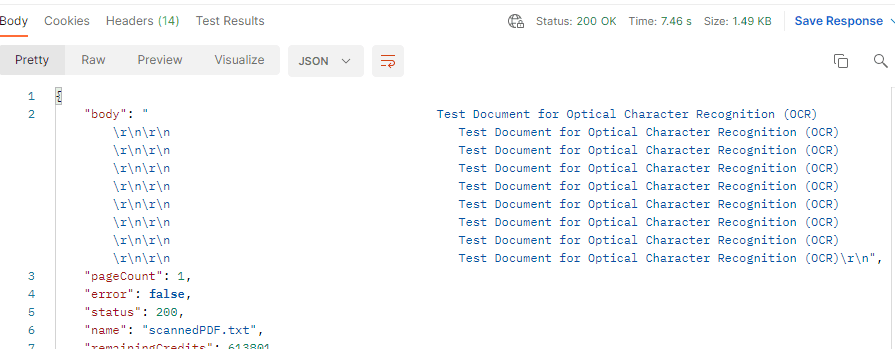
In this tutorial, you learned how to extract text from a scanned PDF using Postman and PDF.co. You also learned how to use the OCR Mode to only extract text from images. You familiarized yourself with the PDF Multitool desktop app to check the PDF objects and the different OCR Modes.
Related Tutorials
