How to Make a Searchable PDF in JavaScript
In this tutorial, we will learn how to make a searchable PDF using PDF.co Web API in JavaScript.
Let's explore the code. We're working with a PDF file that contains an image or a scanned page, and our goal is to create searchable text from it.
Step 1: Declare the Pages to be Processed
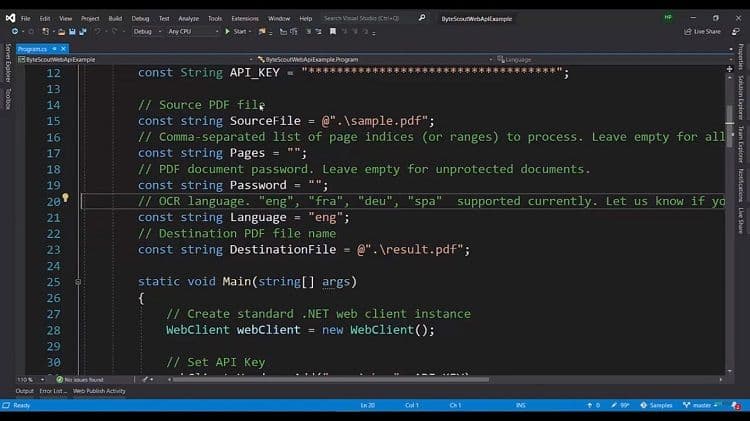
To start, we set up placeholders for API keys that will be included in the request header. We also establish a variable for the source file, which identifies the pages to be processed.
If a page is protected, a password placeholder is required. Since PDF.co supports multiple languages such as English, French, and Spanish, and our input file is in English, we will specify "ENG" for the language. Lastly, we will define the destination file name.
Step 2: Get the Placeholder URL for the PDF
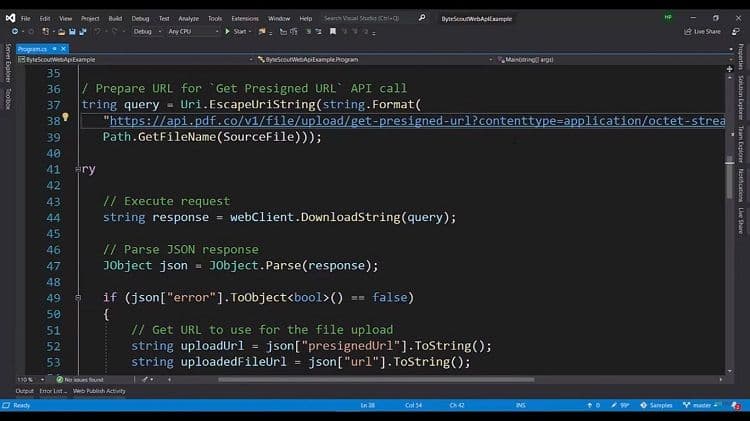
We start by creating a web client object and providing the header keys. We have the physical file, and to complete the process, we need a URL.
So we will obtain a pre-signed URL, which serves as a temporary placeholder for the PDF file we intend to upload. After acquiring the pre-signed URL, we then provide the source file.
Step 3: Process the Request
Simply put, we will input the file name and initiate the request. Upon receiving a response, we use the pre-signed URL to upload the actual file. Following the upload, we process the file to make it searchable. We generate a URL for creating the searchable PDF and include parameters such as name, password, pages, language, and the URL.
After receiving the response, we convert it to JSON, utilizing Newton's method of optimization in the background. If everything proceeds smoothly, we retrieve the resulting URL to download the file. Once the key replacement is finished, we set a breakpoint and start the program.
Step 4: Prepare the URL for the “Make Searchable PDF” API Call
When generating the URL to obtain the pre-signed URL, we input the file name and receive a response, which includes the pre-signed URL for file upload. Along with the pre-signed URL, the response may contain various objects that we do not utilize in this process. Upon successfully receiving the URL, we proceed to upload the file to the specified location.
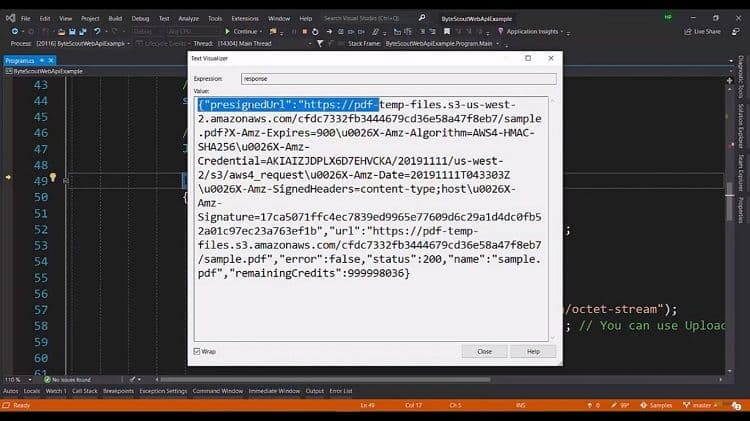
Once the setup is complete, we will then create the URL for the "Make Searchable PDF" API call.
We provided various parameters, such as the name of the output file and the password. We left the section for specifying pages blank because we intend to process all pages. We set English as the language in the URL and included the relevant pre-signed URL for the file we are processing.
Step 5: Asynchronous Option
We have an asynchronous option available for processing, which is particularly useful for large files where waiting for a synchronous response might be impractical. In asynchronous mode, we can submit the job and proceed without waiting for the immediate completion of the process.
For example, when we submit a PDF for processing, the system displays information such as the page count. In this case, the PDF has a total of one page. We then initiate the file download and monitor the console, waiting for the process to complete.
Step 6: Result
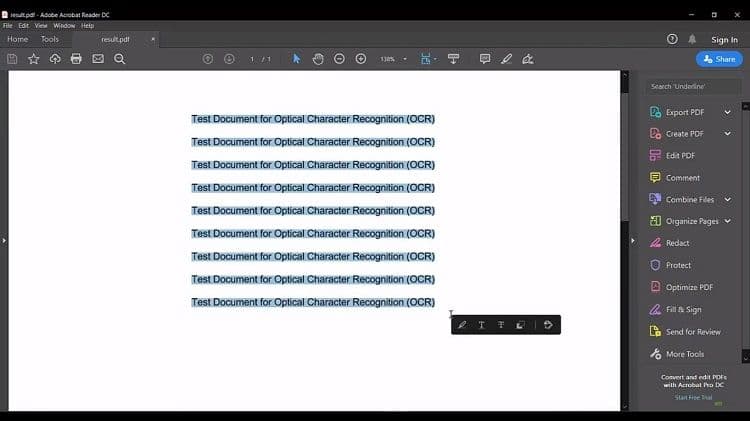
The outcome is that the file, while retaining its original layout, is now searchable, effectively transforming it from a scanned version to a text-selectable one. Users can select, copy, and paste text from the document as needed.
For those interested in learning more about this functionality and exploring further capabilities, the API documentation provides a wealth of information and guidance.
GET YOUR API KEYZAPIER PLUGINEXPLORE API DOCSRelated Tutorials
