How to Remove Script in a PDF using PDF.co Web API
To protect your privacy and keep your personal information secure, it is recommended to disable JavaScript in PDF documents. PDF files that have JavaScript embedded in them are more susceptible to unauthorized access and potential information theft. For added security, it is advisable to remove or disable JavaScript from PDF documents.
Thankfully, PDF.co Web API offers an efficient solution for removing embedded JavaScript from PDFs using asynchronous processing. This allows you to submit requests and retrieve results at your convenience, making it ideal for handling large or long-running tasks seamlessly.
PDF.co is a trusted platform with over 50,000 users and offers a low-code, REST API solution with over 3,000 integrations. In addition to JavaScript removal, PDF.co provides a range of online tools for essential PDF tasks such as splitting or merging PDFs, parsing documents, filling out PDF forms, converting HTML to PDF, extracting PDF data in various formats, PDF conversion, barcode reading, and more.
In today’s tutorial, we will demonstrate how to remove JavaScript from PDF documents using the PDF.co Web API while emphasizing the efficiency and scalability of asynchronous processing.
Getting Started
Below is our sample PDF with embedded JavaScript.
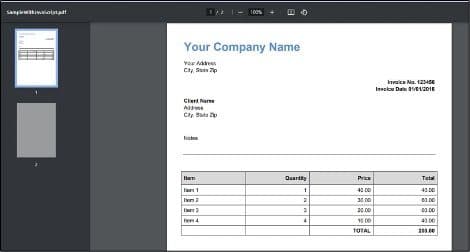
Follow these simple steps to remove embedded JavaScript from PDF documents using the PDF.co Web API:
Step 1: Log in to Your PDF.co Account
First, you need to log in to your PDF.co account. Once you are logged in, navigate to the menu and click on "API Tools."
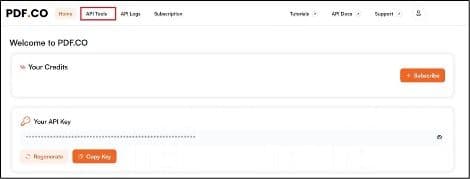
Step 2: API Tools Page
After accessing the API Tools page, locate the Request Tester section and click on it.
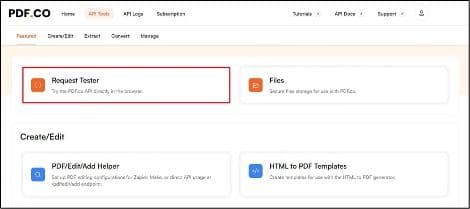
Step 3: Request Tester
To set up the Request Tester for PDF.co, follow these steps:
Step 1: Select Make PDF Unsearchable Endpoint
In the PDF.co API Endpoint field, search for and select /pdf/makeunsearchable and select it. This endpoint converts PDF files into a “text unsearchable” version by converting your PDF into a “scanned” PDF file which is effectively a flat image.
Step 2: Set Input Parameters
In the Input parameters field, you have three options:
- Provide a URL link: If your PDF is hosted online, you can enter the URL of the PDF file.
- Upload a file: If you have the PDF file saved on your device, you can upload it as the input.
- Enable asynchronous processing: Enable asynchronous processing: To process the request asynchronously, set the
"async": trueparameter in your input configuration. This ensures the task runs in the background, and you can fetch the results later. Additionally, make sure to click the checkbox right below the Input URL field to enable asynchronous processing.
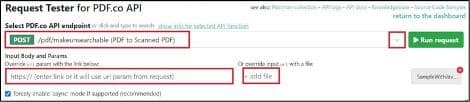
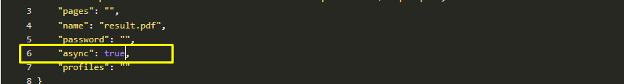
Once you have finished setting up the configuration, simply click the "Run Request" button to send your request to PDF.co.
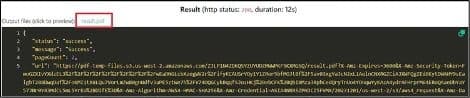
Step 4: Run Request Result
Excellent! Your request has been processed by the PDF.co API, and the resulting file has been generated. To view the output, simply click on the generated PDF file.
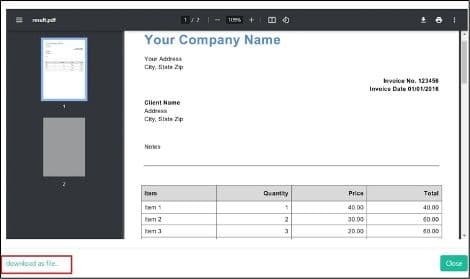
Step 5: Generate Scanned PDF
Here is the scanned PDF that we have processed successfully to remove the embedded JavaScript. To obtain the generated scanned PDF without the embedded JavaScript, simply click on the "Download as file" option.
In this tutorial, you have learned how to use the PDF.co Web API to remove JavaScript from a PDF file, effectively eliminating any embedded JavaScript that might pose a security risk. Additionally, you discovered how to convert a PDF with searchable text into one where the text is unsearchable, enhancing privacy and control over document content.
By leveraging asynchronous processing, you can perform these tasks more efficiently, particularly for large or time-intensive files, as asynchronous mode allows you to retrieve results at your convenience.
For more details on implementing asynchronous processing with the PDF.co Web API, refer to the official PDF.co Asynchronous Processing Documentation.
Related Tutorials
