How to Extract Data from a PDF Using PDF.co Document Parser
Extracting specific data from PDF files can be challenging—especially when dealing with long documents or processing large volumes of files. With PDF.co Document Parser, you can automate data extraction and capture values based on keywords using a reusable template.
In this tutorial, you’ll learn how to extract data from a PDF using template fields in PDF.co Document Parser.
What You’ll Learn
- How to create a Document Parser template
- How to extract data from specific PDF areas using rectangles
- How to test and save a template
- How to run the extraction via API and return JSON output
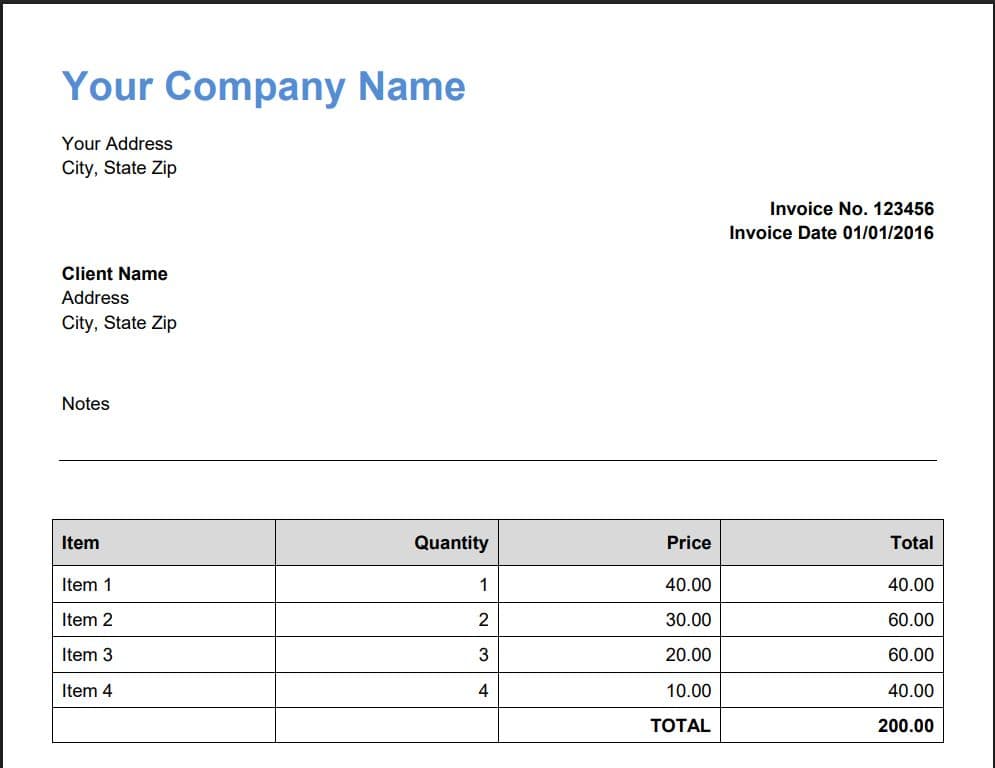
Sample PDF Document
We will use a sample PDF document and extract values based on selected keywords.
Step-by-Step Guide
Open Document Parser
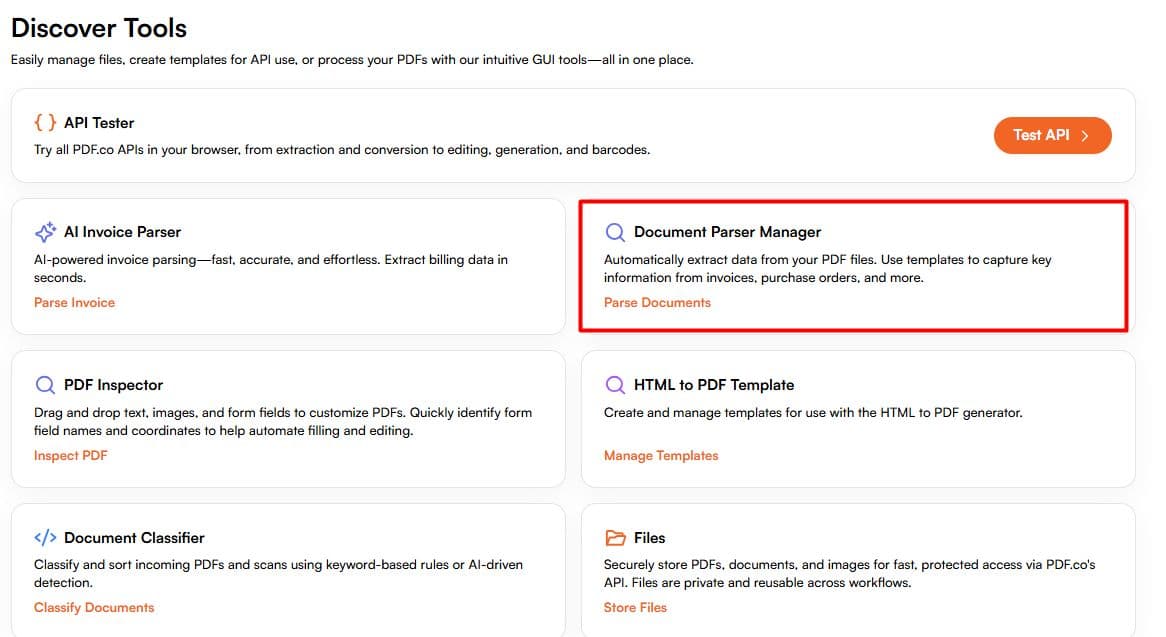
Create a New Template
- Click New Template.
- This opens the Document Parser Template Editor.
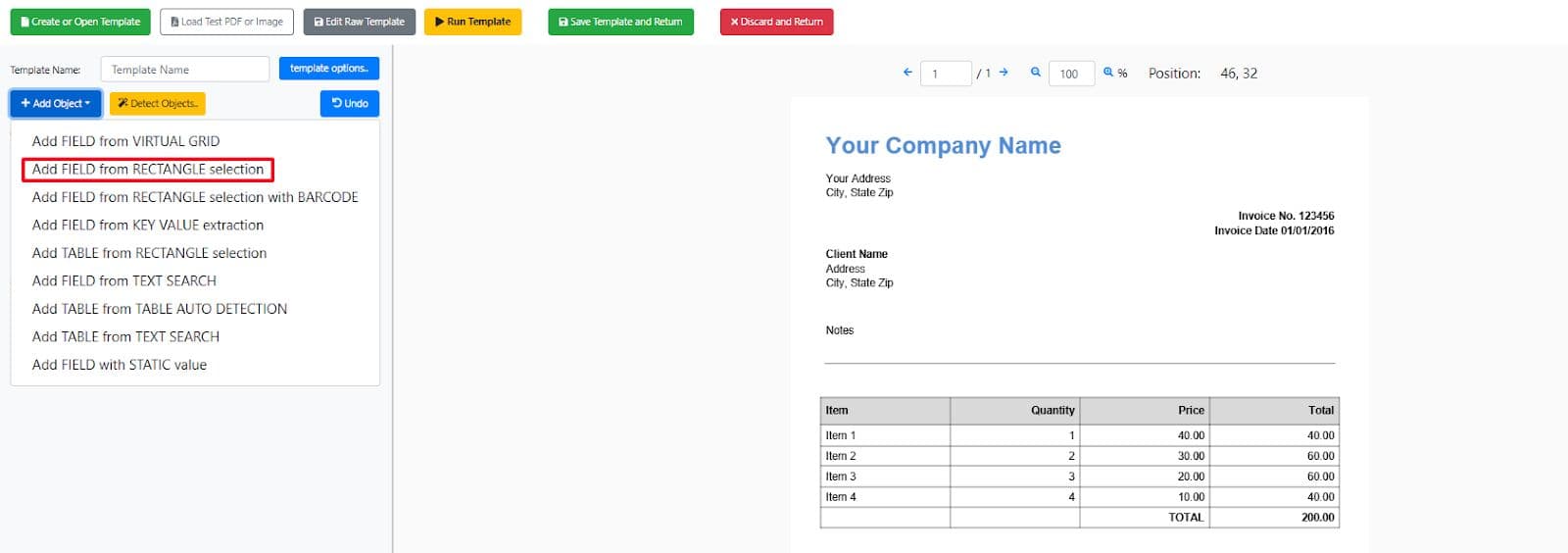
Load a Test PDF or Image
- In the Template Editor, click Load Test PDF or Image.
- Upload your source PDF file.
- Click Add Object
- Select Add Field under the Rectangle selection option.
Drag a Rectangle to Extract Data
- Drag the rectangle to the location on the PDF where the target keyword/data appears.
- Configure/select the keywords you want to extract.
- Run the template to preview the output.
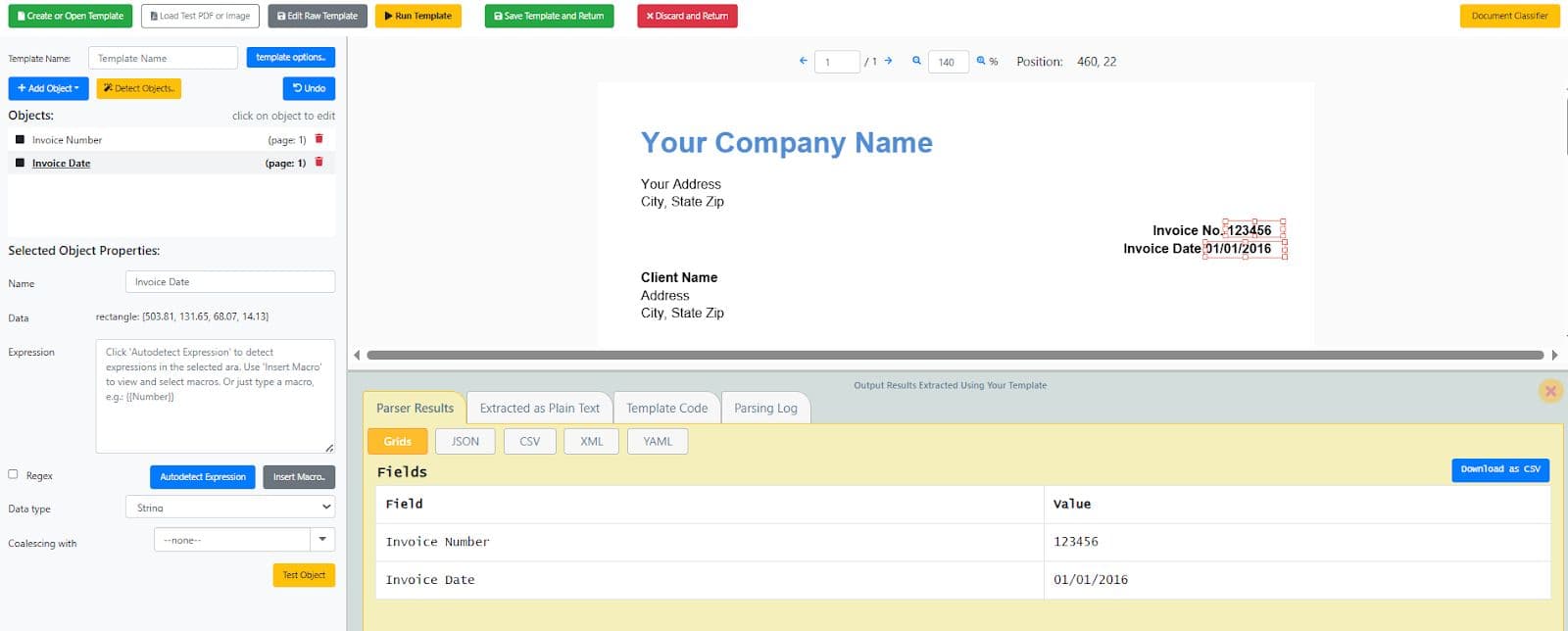
Review the Extracted Data
You will now see the extracted data in the output preview.
If the results look correct:
- Click Save Template and Return to save the template for future use.
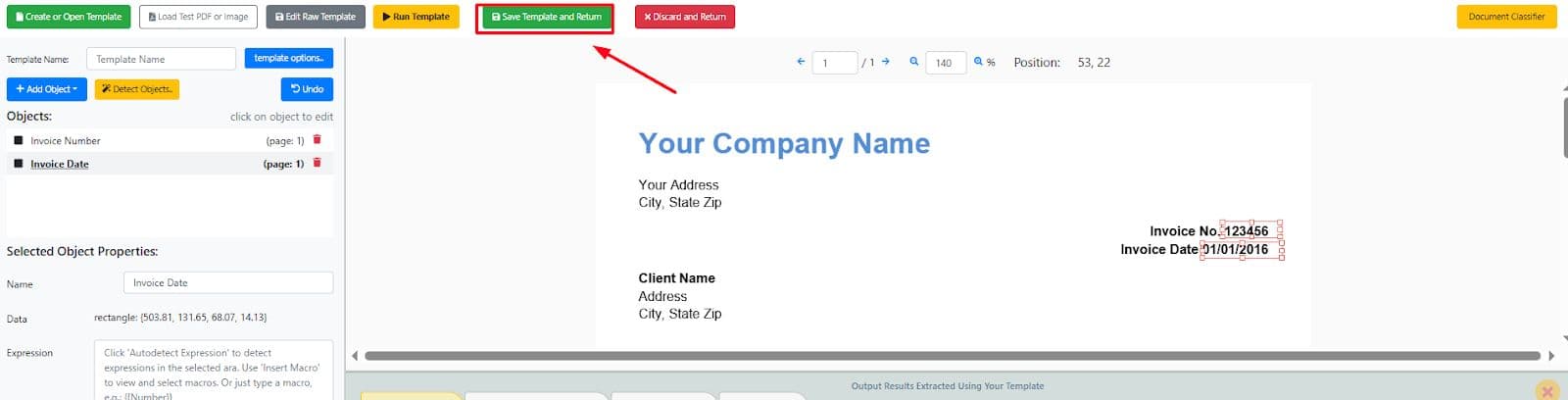
Test the Template via API
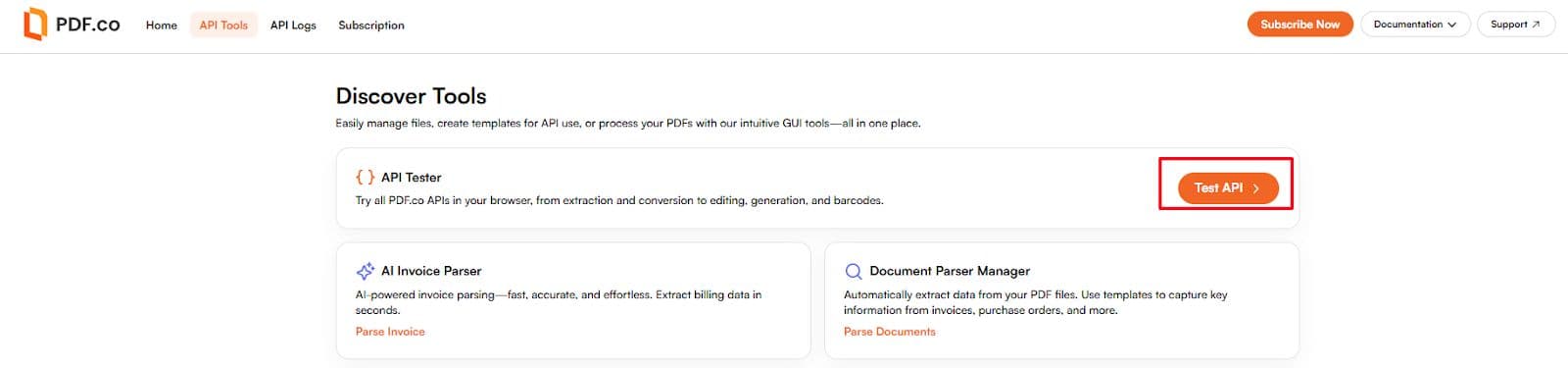
Open API Tester
From your PDF.co dashboard, click API Tester.
Set Up the API Request Tester
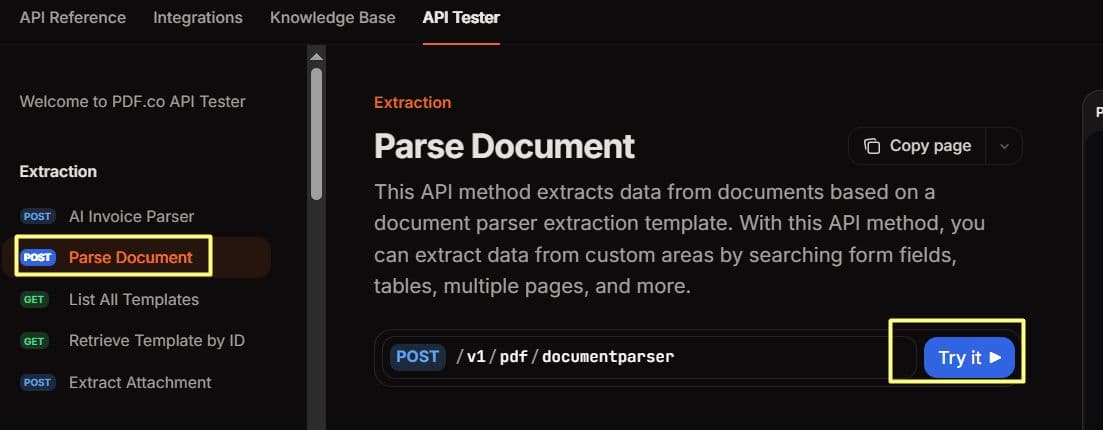
- In the left-hand menu, select the Document Parser endpoint
- Click Try it
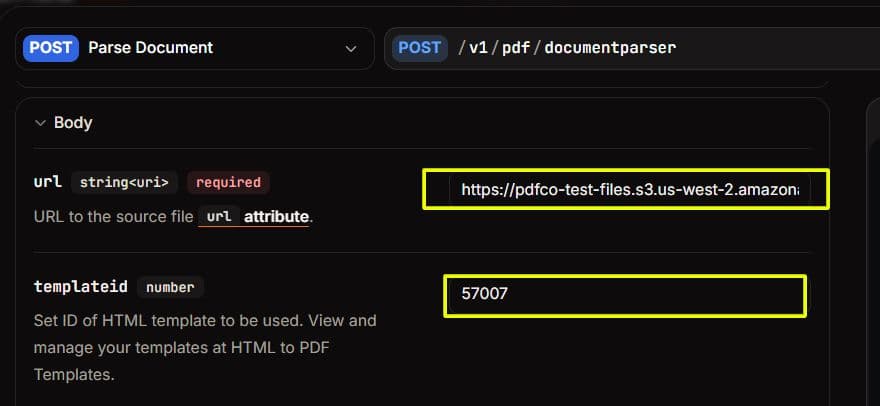
- Enter:
- The input file URL (must be publicly accessible)
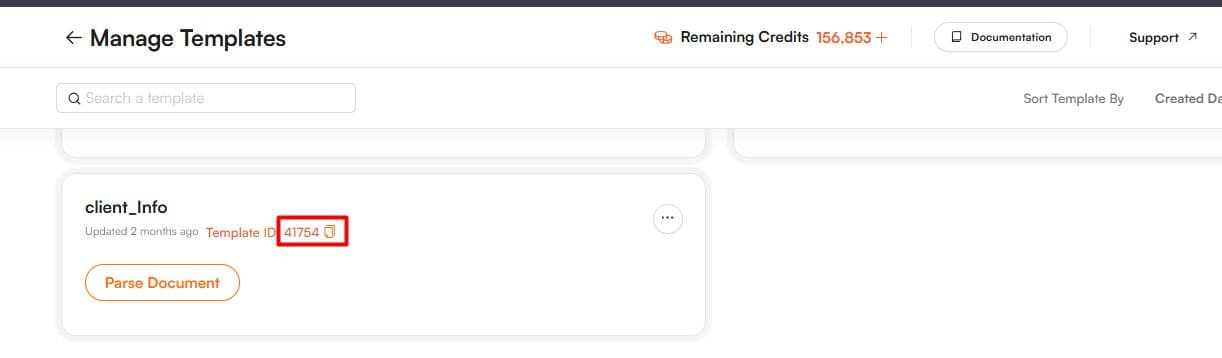
- Your template ID
- Run the request
Run the Request and View Results
Once executed successfully, the API response will return extracted keyword data.
The output JSON will appear on the right side of the tester panel.
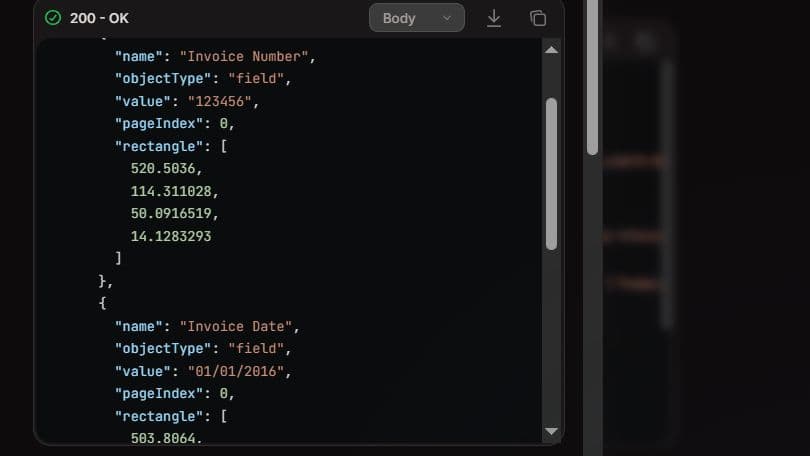
Example JSON Output
You will receive structured extracted keyword-based results in JSON format, based on your saved template.
{
"body": {
"objects": [
{
"name": "Invoice Number",
"objectType": "field",
"value": "123456",
"pageIndex": 0,
"rectangle": [
520.5036,
114.311028,
50.0916519,
14.1283293
]
},
{
"name": "Invoice Date",
"objectType": "field",
"value": "01/01/2016",
"pageIndex": 0,
"rectangle": [
503.8064,
131.650345,
68.0732651,
14.1283293
]
}
],
"elapsed": 0.0157471,
"templateName": "Test_Template",
"templateVersion": "4",
"timestamp": "2026-01-18T11:43:33"
},
"pageCount": 1,
"error": false,
"status": 200,
"name": "view.json",
"credits": 42,
"remainingCredits": 156721,
"duration": 4635
}Related Tutorials

