How to Extract Tables from PDF Files as Table Itself using PDF.co Web API
PDF.co PDF Extractor is a tool offered by PDF.co that makes it easy to get information from PDF files. It uses advanced technology like AI and Machine Learning to automatically extract data, which saves time and ensures accuracy.
With PDF.co PDF Extractor, you can extract various types of data from PDFs, such as text, images, tables, and barcodes. It can even extract information from scanned PDFs using OCR, which reads and understands text from scanned images. This tool simplifies the process of extracting data from PDFs and helps you access the information you need quickly and reliably.
We will now demonstrate how to extract tables from PDF files as the actual table using the PDF.co Web API. Please follow the simple step-by-step tutorial provided below.
Getting Started
We will utilize a sample PDF invoice and extract the table from it in its original table format.
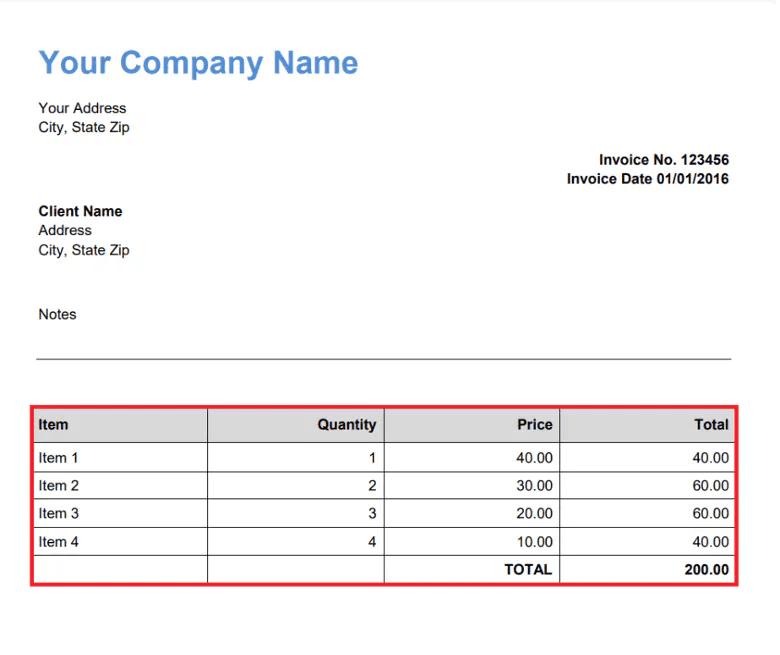
Here's a simplified step-by-step guide to extracting a table from a PDF file:
Log in to Your PDF.co Account
To begin, please log in to your PDF.co account. Once you are logged in, navigate to the menu and click on "API Tools."
API Tools Page
Once you're on the API Tools page, find and click on the Request Tester section.
Request Tester
Let's configure the Request Tester for PDF.co.
Select Convert to CSV Endpoint
In the PDF.co API Endpoint field, search for and select /pdf/convert/to/csv. This endpoint will extract PDF and scanned images into CSV format, including the layout, columns, rows, and tables.
Set Input Parameters
In the Input parameters field, you can either provide a URL link or upload a file as your input.
Add JSON Code
Now, let's add the JSON code to define the coordinates for table extraction and the rectangular area value of the table. You can obtain the rectangular area value easily using the PDF Edit Add Helper tool.
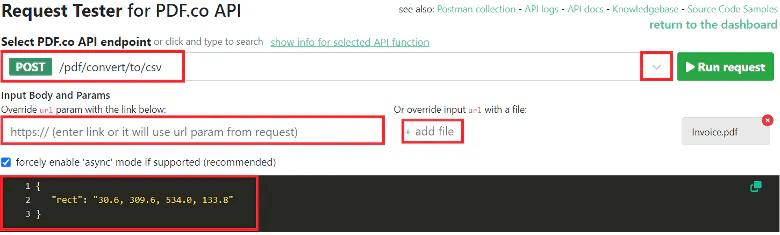
Once you have finished setting up the configuration, simply click the "Run Request" button to send your request to PDF.co.
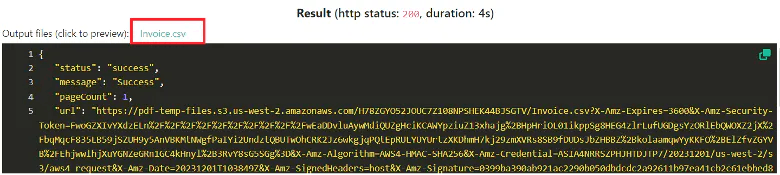
Run Request Result
Great! The PDF.co API has successfully processed your request and provided the generated file. You can simply click on the generated file to view the output.
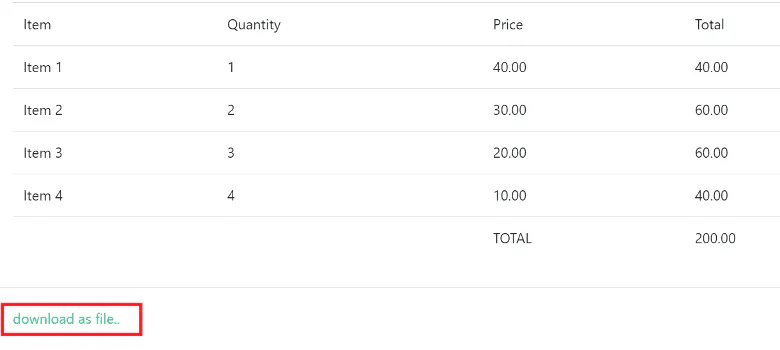
Extracted Table Output
Below is the table extracted from a PDF document using PDF.co Web API. Simply click on the "Download as file" option to obtain the generated table in CSV format.
In this tutorial, you learned how to use the PDF.co Web API to extract tables from PDF files. By using the PDF to CSV API endpoint, you can easily get the tables as CSV files.
To help you find the tables in the PDF, you also learned about the PDF Edit Add Helper tool. This tool helps you identify the exact area where the table is located in the PDF.
By following the steps in this tutorial, you can extract tables from PDFs and work with the data in a structured format using the PDF.co Web API.
Related Tutorials

