If you are getting error messages like “Too many Requests” and “Access Denied” while providing the input URL, you can add a cache to enable built-in caching functionality.
How to Extract Information from PDFs using PDF.co Web API in JavaScript
12 Minutes Read
This tutorial explains how to extract valuable information from any PDF using the PDF Info functionality from PDF.co Web API with a focus on asynchronous processing. Asynchronous processing allows you to perform PDF extraction tasks without blocking other operations, improving the overall efficiency of applications, especially when handling large or multiple PDF files.
The PDF.co Web API supports both synchronous and asynchronous modes, but for optimal performance, especially when dealing with large datasets or multiple documents, asynchronous processing is recommended.
Benefits of Asynchronous Processing
Asynchronous processing enables non-blocking operations, meaning that you can send a request for PDF extraction and continue with other tasks without having to wait for the operation to complete. This leads to:
- Improved Application Performance: Asynchronous processing allows your application to handle multiple requests simultaneously, improving user experience by reducing wait times.
- Scalability: By using asynchronous operations, your application can scale more effectively, handling large numbers of requests without overloading the server or blocking other processes.
- Efficiency in Resource Management: With asynchronous tasks, resources are utilized more efficiently as the application does not have to wait for one task to complete before moving on to the next.
For more details on asynchronous processing, refer to the PDF.co Documentation on Async and Sync Mode.
Features of PDF Info Reader API Endpoint
The PDF.co Web API provides tools to extract any required information from a provided PDF document effectively. The PDF.co Info Reader API endpoint works efficiently by gathering detailed information about any PDF document. You can even extract information regarding its properties and the security permissions used by the document.
Moreover, the API allows checking information, including PDF form fields. The PDF form can include checkboxes, list boxes, text fields, radio boxes, and combo boxes. You can use this page for one-time checking of such information. Below is a detailed demo explaining these features to help you understand them thoroughly.
One of the best features of the PDF.co Web API is that it provides high security for its users. The API maintains security by transmitting your documents and data files via encrypted connections. You can learn more about the PDF.co API security here.
Endpoint Parameters
Following is a comprehensive explanation of the available parameters of the PDF Info Reader API.
url: It is a required parameter that contains the link to the source file. It provides the URL of the input PDF document from which you want to extract information. The PDF.co platform supports any publicly accessible URL, including those from Dropbox, Google Drive, and the built-in file storage of PDF.co. You can encrypt or decrypt any input or output data file using the user-controlled data encryption functionality.
httpusername: It is an optional parameter that takes the http auth user name if it is necessary to access the source URL.httppassword: It is an optional parameter that takes the http auth password if it is required to access the source file.async: When set totrue, the process runs asynchronously, and the response will include a job ID and a status URL to check the operation's progress. You can poll the status URL or use webhooks to get notified when the task is complete..profiles: It is an optional parameter that must be a string. You can set additional customized configurations for file tuning and extra options using this parameter.
How to Extract PDF using API in JavaScript
The following source code shows you how to extract information from a sample PDF document using the PDF.co Info Reader API. The sample code in Javascript shows how to gather relevant information from a PDF sample document. You can upload your respective documents or provide a link to them in the URL parameter to collect valuable data. You can have information such as text fields, page count, permissions, checkboxes, and more.
The code contains a sample PDF form as an example here. You must provide a generated API key by logging into the PDF.co platform login and the pdf file URL in the API request for the API to work. Moreover, the PDF.co API returns the resulting output of the provided file URL from which you can separate required information such as the author, page number, password, permissions, bookmarks, and information regarding the PDF content.
Sample Code Snippet for PDF Extraction
Following is an example code to extract information from a PDF form using PDF.co Web API:
Code Sample: Here
Source File
Below is the screenshot of the source file used for this example.

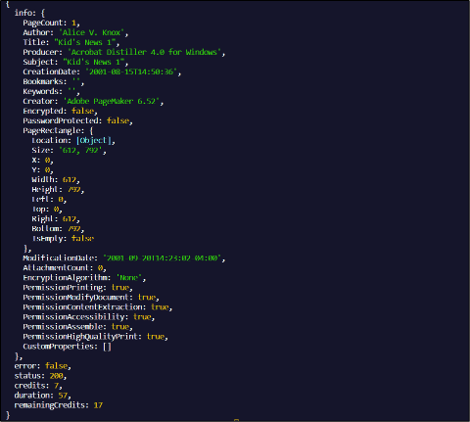
Output of Extracted PDF
Below is the screenshot of the output provided after the execution of the above sample code.
Sample Code Walkthrough
Following is a sample guide to explain the working of sample code for extracting information using the Info Reader API endpoint:
- You must import the necessary packages to send API requests. The
requireparameter represents all the crucial modules. In this scenario, the essential package used for making HTTP requests isaxios, a promise-based HTTP client for the browser and Node.js. Unlike therequestmodule, which is used for making HTTP calls in older versions,axiosis now preferred for its simplicity and better support for asynchronous operations. Thepathpackage is still required if file path manipulation is needed in the application. - After logging in to the PDF.co website, you can obtain your API key to access the Web API. You can't send a direct request, so you will need to use this specific API key as an access token in the header for authentication.
- Since you might have to use the code several times, the best approach is to use the API key in variable declaration. This approach allows you to change the variable and edit the complete code file without changing anything in the actual code.
- The next step is to declare and initialize the source file and query path variables for the document to extract critical information from it. The query path contains the information of the relevant API endpoint you want to utilize in the scenario.
- You have to provide the relevant information in the JSON payload. For example, the field names, page numbers, and the information to be added. Here the code provides only the source URL.
- You should set the
asyncparameter totrueto enable asynchronous processing, ensuring smoother and more efficient operation. - You must declare a variable to provide API options such as API endpoint URL, method, and headers. The code contains “reqOptions” for initializing such information in this example.
- The next step is to send the POST request to the API endpoint and monitor the asynchronous job's status. Once the job is processed, a successful response with status 200 will return the required output. If the request is unsuccessful, you can modify the code and re-execute the job, checking the status until completion.
Related Tutorials
