How to Use PDF to JSON Meta in JavaScript
This tutorial and the accompanying sample code explain converting a PDF document into JSON meta using the PDF to JSON functionality of the PDF.co Web API with the JavaScript programming language. This allows you to efficiently convert any PDF document into JSON meta while preserving the document's fonts, texts, images, vectors, and formatting.
Why Use Asynchronous Processing?
Asynchronous processing is critical for handling tasks that require more time to process, such as AI-based metadata extraction. Unlike synchronous processing, which blocks other operations until the task is complete, asynchronous processing allows the application to perform other operations or continue running without delays. For endpoints like PDF to JSON Meta, which involve heavy processing using Artificial Intelligence (AI), asynchronous mode is more efficient and user-friendly. It enables:
- Non-Blocking Operations: You can continue using their applications without waiting for the process to complete.
- Improved Performance: Frees up resources and avoids timeouts for long-running tasks.
- Scalability: Better handles multiple requests simultaneously.
For more details on asynchronous processing, refer to the PDF.co Documentation: Async and Sync Modes.
Features of PDF to JSON API Endpoint
The PDF.co Web API provides tools and functionalities to convert any PDF document or scanned image to JSON. This conversion process is so efficiently used that even the formatting, the text, the vectors, and the images are preserved. The API uses the method of auto-classification of any input document to convert it to JSON. You can utilize the document classifier endpoint to automatically detect the incoming document’s class based on their keywords-based rules.
You can define certain rules to find a specific vendor who provided the document and which template to apply according to this information. The PDF to JSON Meta functionality uses Artificial Intelligence (AI) to detect text objects’ meta styles. For example, the paragraph style includes h1 to h7, p, and small, the meta type includes text, integer, decimal, and currency, and the meta subtype includes personName, companyName, and AI-based meta types. Moreover, meta end-point consumers need more credits as it runs with the AI, and the process is slowed down due to AI. Therefore, the async mode is more suitable for this endpoint.
The PDF.co Web API also provides a highly secure platform for its users. The API is secure to use as it transmits the data via an encrypted connection. You can go through the security protocols here.
Endpoint Parameters for PDF to JSON Meta
Following are the parameters of PDF to JSON Meta endpoint:
url: It is a required parameter that provides the URL to the source file. The PDF.co platform supports any publicly accessible URL, including those from Dropbox, Google Drive, and the built-in file storage of PDF.co.httpusername: It is an optional parameter. It provides an HTTP auth user name to access the source URL if required.httppassword: It is an optional parameter. It provides an HTTP auth password to access the source URL if required.pages: An optional parameter and must be a string. It helps in providing a comma-separated list of the pages required. The users can set a range for the pages by using “ -.” For example, 2, 5-7, and 2-. Moreover, the users can leave the parameter empty to indicate selecting all the pages.unwrap: It is an optional parameter that unwraps the lines and forms them into a single line in the table cells. It is done by enabling lineGrouping.rect: It is an optional parameter and must be a string. It provides coordinates for extraction. Moreover, the users can use PDF.co PDF viewer to copy coordinates easily.lang: It is an optional parameter that sets the language for OCR to use for scanned JPG, PNG, and PDF document inputs to extract text from them. The languages include eng, spa, jpn, deu, and many others.inline: It is an optional parameter. It is set to true to return data as inline or false to return the link to an output file.lineGrouping: It is an optional parameter and must be a string. It enables grouping within the table cells.async(Optional): When set totrue, the process runs asynchronously, and the response will include a job ID and a status URL to check the operation's progress. You can poll the status URL or use webhooks to get notified when the task is complete.name: It is an optional parameter and must be a string. It provides the generated output file name.expiration: It is an optional parameter that provides the expiration time for the output link.profiles: It is an optional parameter and must be a string. This parameter helps in setting additional configurations and extra options.
PDF to JSON Meta using JavaScript
The following source code explains how to convert any PDF document using the PDF to JSON Meta API. The sample code in JavaScript explains converting a PDF document or any scanned image using the API. The below code takes the sample PDF file for classification and uses Artificial Intelligence (AI) to detect the meta styles, such as paragraph styles. It then writes the found meta styles in JSON and sends them back to the you, which you can download and store on your local storage.
PDF to JSON Sample Code : Sample Code Link
Following is the sample code in javascript to explain using PDF to JSON meta endpoint
var https = require("https");
var path = require("path");
var fs = require("fs");
// The authentication key (API Key).
// Get your own by registering at https://app.pdf.co
const API_KEY = "***********************************";
// Direct URL of source PDF file.
// You can also upload your own file into PDF.co and use it as url. Check "Upload File" samples for code snippets: https://github.com/bytescout/pdf-co-api-samples/tree/master/File%20Upload/
const SourceFileUrl = "https://bytescout-com.s3.amazonaws.com/files/demo-files/cloud-api/pdf-to-json/sample.pdf";
// Comma-separated list of page indices (or ranges) to process. Leave empty for all pages. Example: '0,2-5,7-'.
const Pages = "";
// PDF document password. Leave empty for unprotected documents.
const Password = "";
// Destination JSON file name
const DestinationFile = "./result.json";
// Prepare request to `PDF To JSON Meta` API endpoint
var queryPath = `/v1/pdf/convert/to/json-meta`;
// JSON payload for api request
var jsonPayload = JSON.stringify({
name: path.basename(DestinationFile), password: Password, pages: Pages, url: SourceFileUrl, async: true
});
var reqOptions = {
host: "api.pdf.co",
method: "POST",
path: queryPath,
headers: {
"x-api-key": API_KEY,
"Content-Type": "application/json",
"Content-Length": Buffer.byteLength(jsonPayload, 'utf8')
}
};
// Send request
var postRequest = https.request(reqOptions, (response) => {
response.on("data", (d) => {
// Parse JSON response
var data = JSON.parse(d);
if (data.error == false) {
console.log(`Job #${data.jobId} has been created!`);
// Process returned job
checkIfJobIsCompleted(data.jobId, data.url);
}
else {
// Service reported error
console.log(data.message);
}
});
}).on("error", (e) => {
// Request error
console.log(e);
});
// Write request data
postRequest.write(jsonPayload);
postRequest.end();
function checkIfJobIsCompleted(jobId, resultFileUrl) {
let queryPath = `/v1/job/check`;
// JSON payload for api request
let jsonPayload = JSON.stringify({
jobid: jobId
});
let reqOptions = {
host: "api.pdf.co",
path: queryPath,
method: "POST",
headers: {
"x-api-key": API_KEY,
"Content-Type": "application/json",
"Content-Length": Buffer.byteLength(jsonPayload, 'utf8')
}
};
// Send request
var postRequest = https.request(reqOptions, (response) => {
response.on("data", (d) => {
response.setEncoding("utf8");
// Parse JSON response
let data = JSON.parse(d);
console.log(`Checking Job #${jobId}, Status: ${data.status}, Time: ${new Date().toLocaleString()}`);
if (data.status == "working") {
// Check again after 3 seconds
setTimeout(function(){
checkIfJobIsCompleted(jobId, resultFileUrl);
}, 3000);
}
else if (data.status == "success") {
// Download JSON file
var file = fs.createWriteStream(DestinationFile);
https.get(resultFileUrl, (response2) => {
response2.pipe(file)
.on("close", () => {
console.log(`Generated JSON file saved as "${DestinationFile}" file.`);
});
});
}
else {
console.log(`Operation ended with status: "${data.status}".`);
}
})
});
// Write request data
postRequest.write(jsonPayload);
postRequest.end();
}JSON File Output
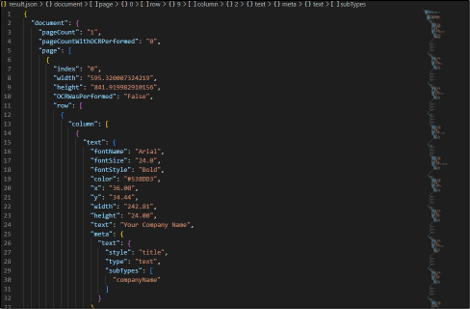
Below is the output screenshot to show a small part of the resulting JSON file:
Sample Code Walkthrough
- The code imports the required packages to make the API request, read the file, and store it on the local storage. In this scenario, the required packages are “https”, “fs”, and “path.”
- It then declares and initializes the
API_Key, which you can get by signing up or logging into your PDF.co account. As the PDF.co APIs are secure; you will need these API keys to make requests to them. - After this, it declares and initializes the API’s body payload, which in this sample code is the source file URL, destination file pages, and the file password. You can see from this example that the pages and password variable are left empty for you to play with the variables to classify the pages of the source or password-protected file. The code utilizes the PDF.co sample code containing the sample source file in this scenario. You can see and download this file. Therefore, it is not password protected.
- It declares the initializes the “
async” variable with “true” so that the request can run asynchronously. As this API runs on AI, it can be prolonged, especially for large files. Therefore, it is recommended to use async mode while calling it. - It then assembles variables for JSON payload and sends the API requests. The successful request returns the JSON that the file stream reads and stores on the local storage as the results.JSON file, i.e., the destination file.
Related Tutorials

