Extract Text from Scanned PDF in PHP using PDF.co Web API
PDF.co is an API and automation platform for PDF, Barcodes, Data Extraction, and Data Transformations. It also presents online tools for conducting fundamental PDF-related functionalities such as splitting/merging PDF, document parsing, filling PDF forms, searching/replacing text, PDF data extraction to various formats, barcode reader, etc.
In this article, we’ll observe how to extract text from PDF in PHP, in particular, scanned PDF. The code will be written in PHP and HTML. PDF.co will be used to perform conversations.
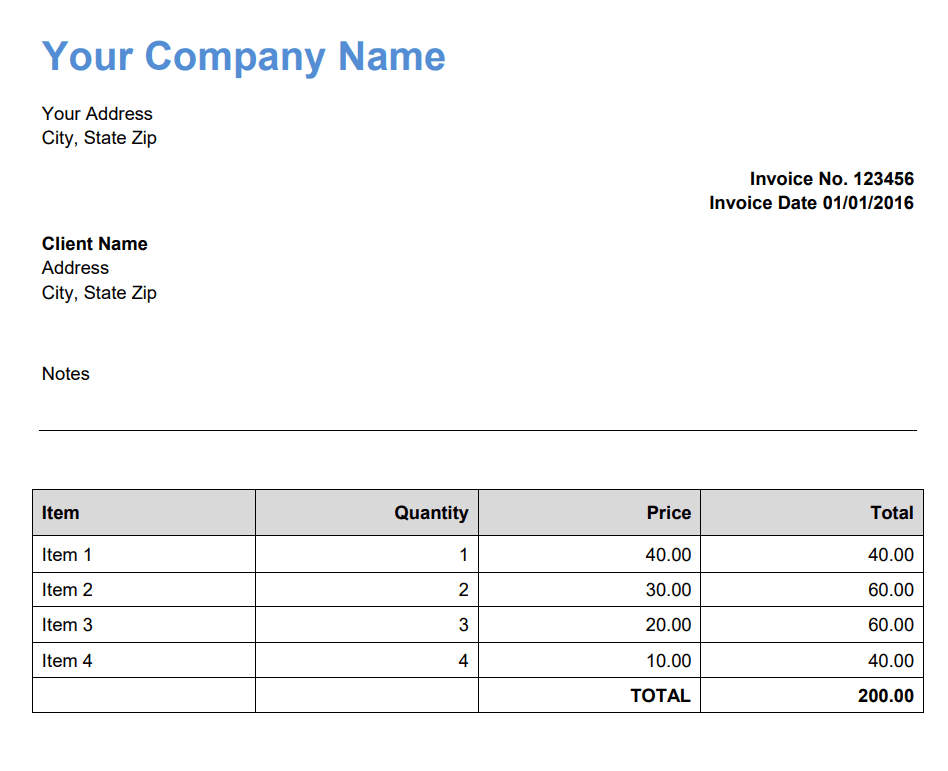
We will use this scanned sample in our tutorial about PDF parsing in PHP.
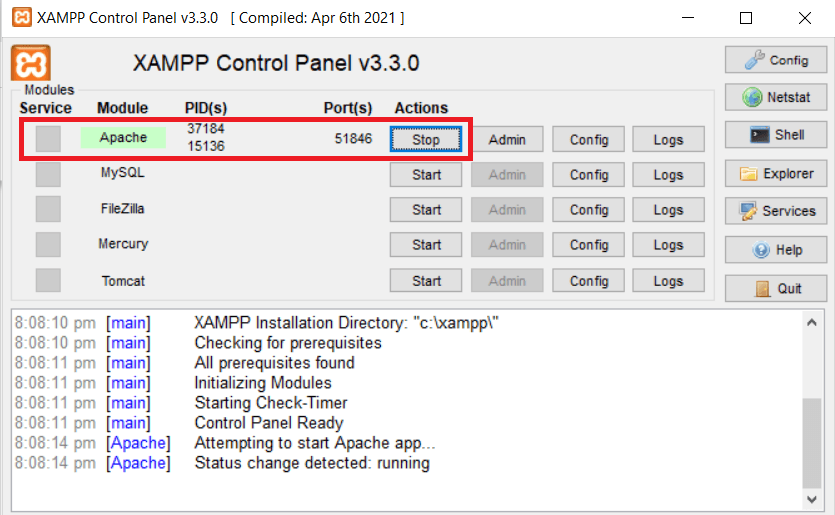
Step 1: Start Apache Server
First, let’s start the Apache server so we can run our program.
Step 2: Add Source Code
Next, add the HTML and PHP sample code in the Visual Studio Code editor. You can also use your favorite editor in PHP. This source code is available at PDF.co API Docs.
Step 3: Save Files into the Program Folder
Then, save the HTML and PHP sample code in your program folder. We highly recommend saving the files in a folder inside the \www or the \htdocs directory.
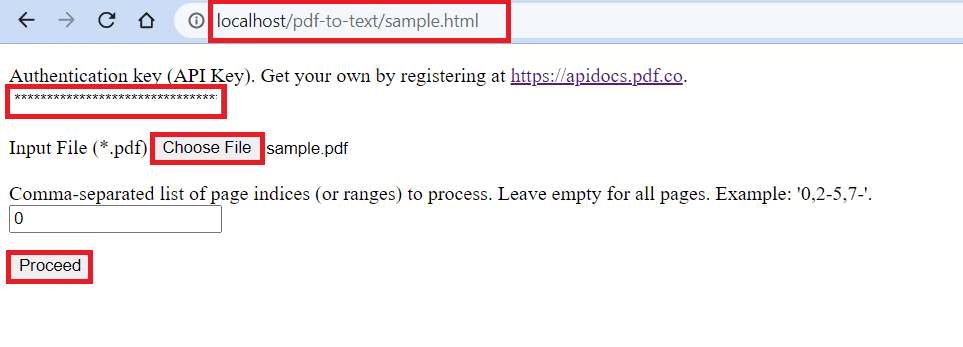
Step 4: Run Program
Now, let’s run our program and extract text from the scanned PDF.
- In the browser address bar, type in
localhost/folder-name/sample.html. The /folder-name/ is a folder in the /www directory where you stored the files if you are using WampServer. - In the API Key field, enter your PDF.co API Key. You can get it in your PDF.co dashboard.
- Then, input the scanned PDF file.
- Leave the page number field empty so it extracts all the PDF pages
- Click on the Proceed button to send a request.
Step 5: Conversion Result
Once the conversion is complete, click on the resulting URL to view the output.

Step 6: PDF to Text Output
Here’s the converted PDF to Text output.

Useful Resources
In this tutorial about PDF reading in PHP, you learned how to extract or copy text from scanned PDF in PHP using PDF.co Web API. You also learned how to set up the source code samples to get you up and running right away.
Video Guide
Related Tutorials
