How to Extract Data from PDF CVs with Different Physical Layouts using Zapier
Extracting data from PDF CVs with varying physical layouts can be a time-consuming and challenging process. However, with the powerful combination of PDF.co and Zapier, you can easily automate this task, saving time and simplifying the data extraction process.
PDF.co Document Parser is a powerful tool that can greatly simplify the process of extracting data from PDF CVs with different physical layouts. With its advanced capabilities and easy-to-use interface, PDF.co Document Parser makes it easy to automate data extraction tasks and simplify your hiring process.
In this article, we will explore how PDF.co and Zapier work together to extract data from PDF CVs with different physical layouts, enabling you to simplify your hiring process and make knowledge-based decisions with ease. So let’s get started!
We will use this sample PDF CVs with different physical layouts to demonstrate the data extraction process using PDF.co and Zapier.

Before we start the extraction process, we recommend checking out our tutorial on how to quickly create a template and extract data from a PDF document using PDF.co Document Parser. This tutorial will provide you with step-by-step guidance. Once the data is extracted, we will use a template to save the extracted data into a file, simplify the workflow, and enhance productivity.
Step 1: Create a Zap
- To begin, let’s start by logging into your Zapier account and creating a Zap.
Step 2: Select Google Drive App
- Next, locate and select the Google Drive app in your Zapier account, and choose New File in Folder as the trigger event. Alternatively, you can select a different cloud storage app if you prefer to get the file saved in a different location.
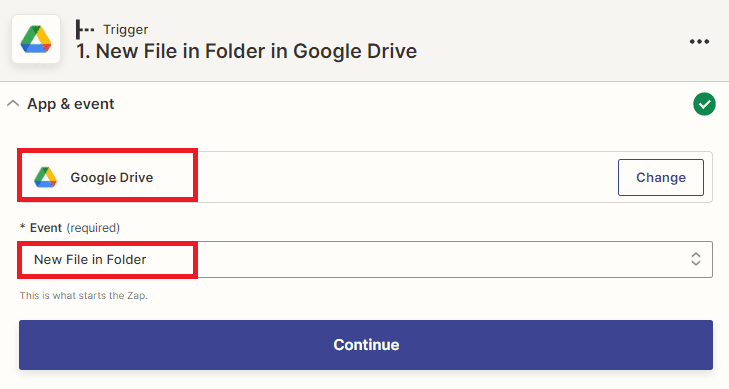
Step 3: Connect your Google Drive Account to Zapier
- Now, add a connection between your Google Drive account and Zapier to grant access to your desired Google Drive folder.
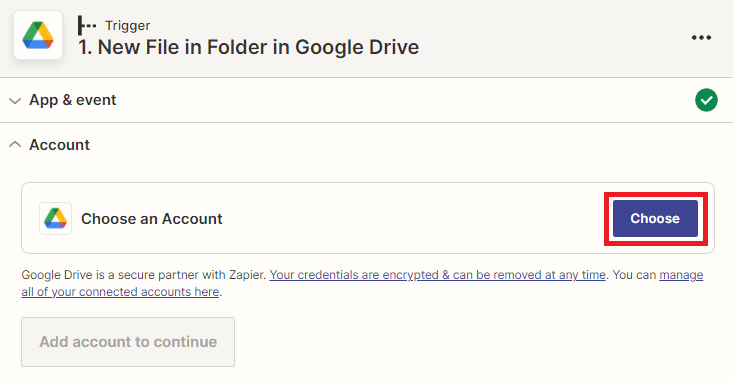
Step 4: Setup Trigger
Let’s configure the trigger.
- Start by selecting My Google Drive as the Drive to be used in the trigger configuration.
- Next, specify the specific folder from which you want to fetch the PDF file.
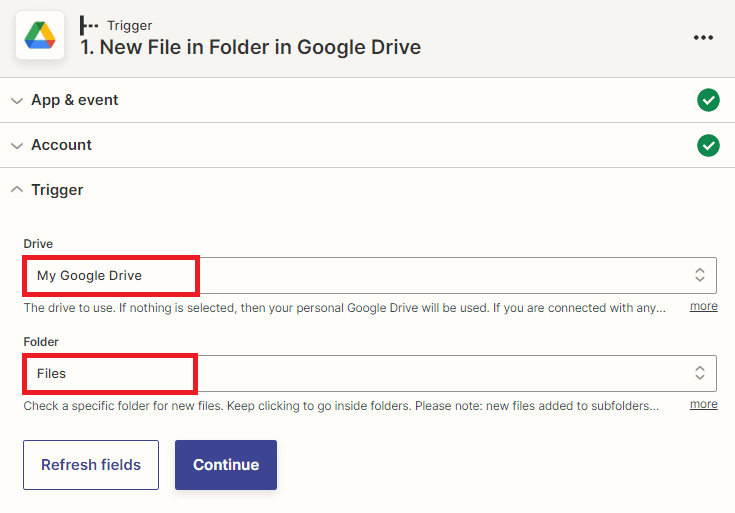
Step 5: Test Trigger
- After setting up the trigger, you can click on the test trigger button to verify if it has been set up correctly. This will trigger the configured automation and return the specific file value from Google Drive according to the trigger conditions you have defined.
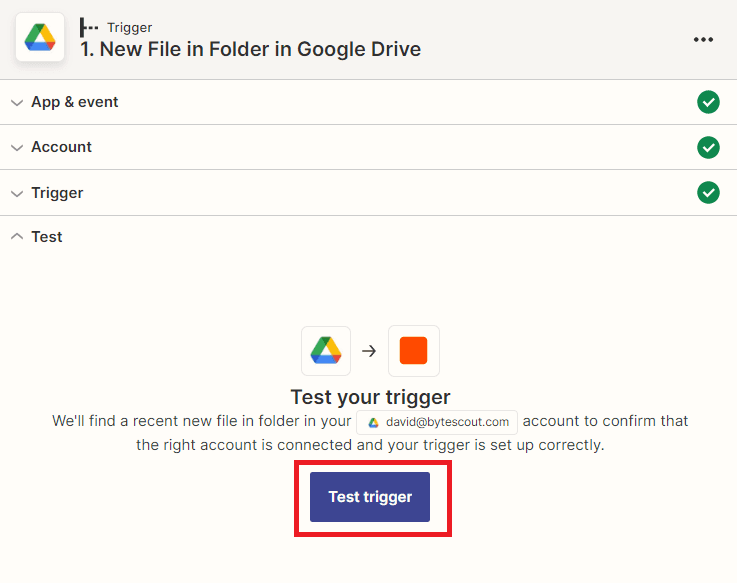
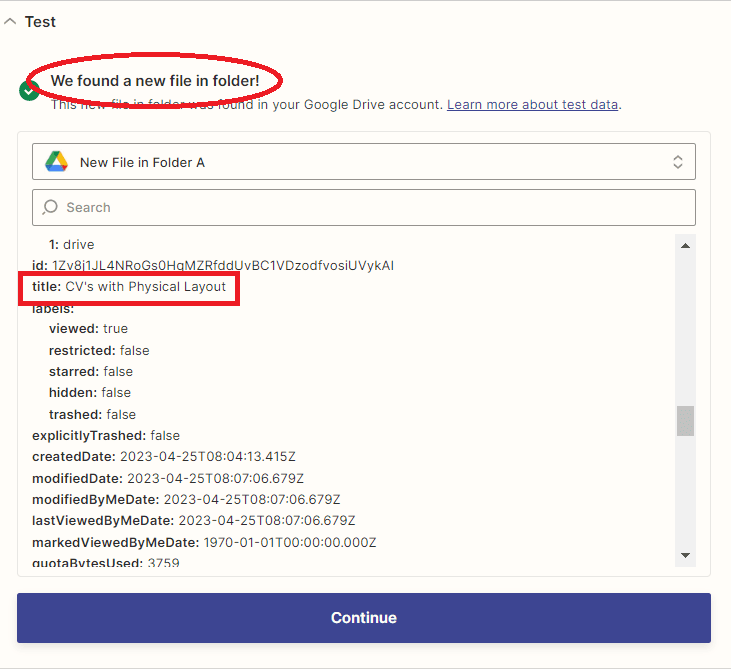
Step 6: Test Trigger Result
- Great! The test trigger was successful and returned the specific file value we need from Google Drive. Now, let’s proceed to add another app to our workflow for extracting data from PDF CVs.
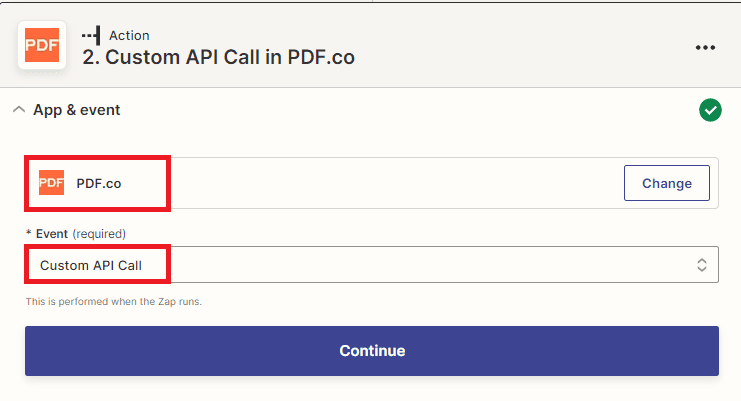
Step 7: Add PDF.co App
- In this step, we will add the PDF.co app and locate the Custom API Call option to utilize the PDF.co Document Parser endpoint for extracting data from PDF CVs.
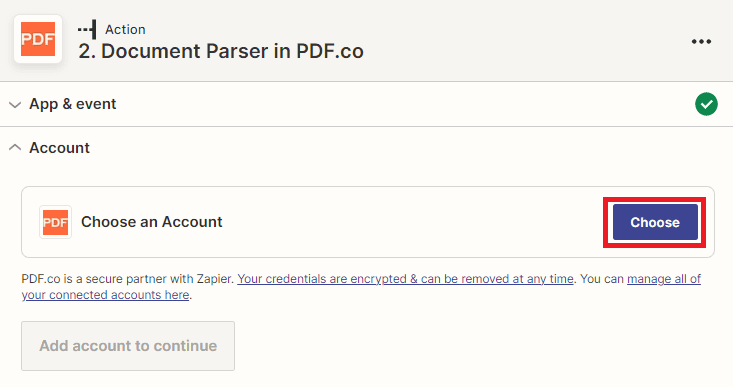
Step 8: Connect PDF.co Account to Zapier
- To connect your PDF.co account to Zapier, you will need to add your API Key. You can obtain the API Key from your PDF.co dashboard or by signing up.
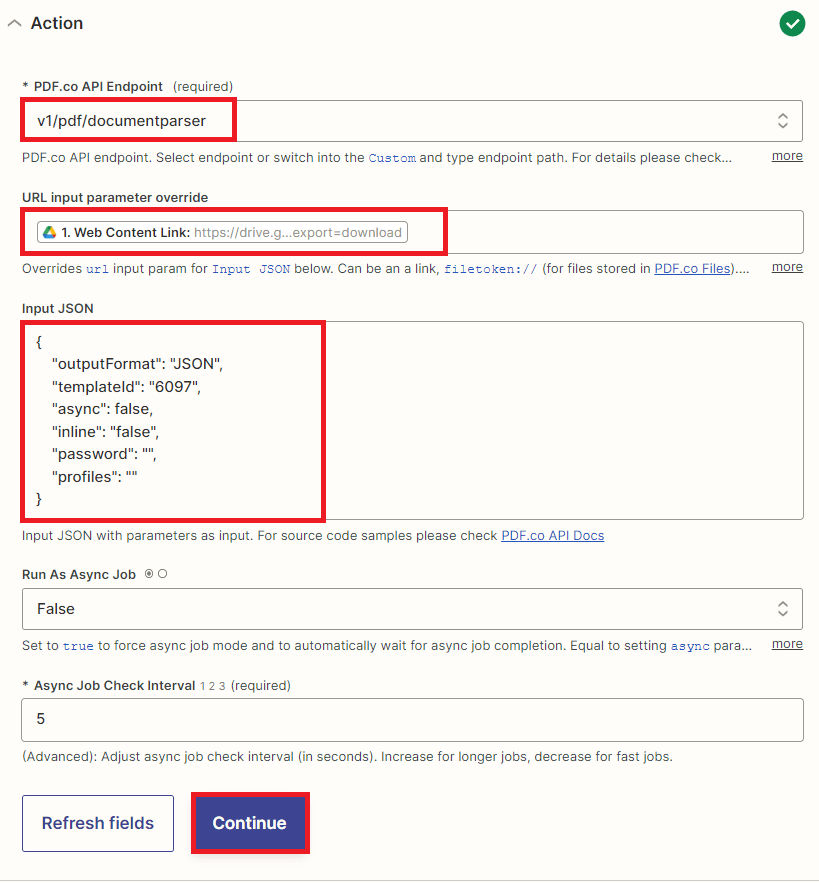
Step 9: Setup Action
Let’s set up the action for extracting data from PDF documents using the PDF.co Document Parser endpoint.
- First, input the PDF.co Document Parser endpoint to allow you to make an API call to the PDF.co service for extracting data from PDF documents.
- Next, select the Web Content Link to allow you to provide the link to the PDF document stored in Google Drive where you want to extract data.
- Then, enter the JSON code containing the Output Format, and specify the desired output format (e.g., JSON, XML, CSV) in the JSON code. Additionally, include the template ID that contains the defined extraction rules for extracting data from PDF CVs. You can create a template ID and extract data with the Document Parser. Then, set Inline to false if you want the extracted data to be returned as a URL, or set it to true directly in the response.
Step 10: Test Action
- Once you have completed setting up the action, it’s time to test the data extraction process and save it as a file.
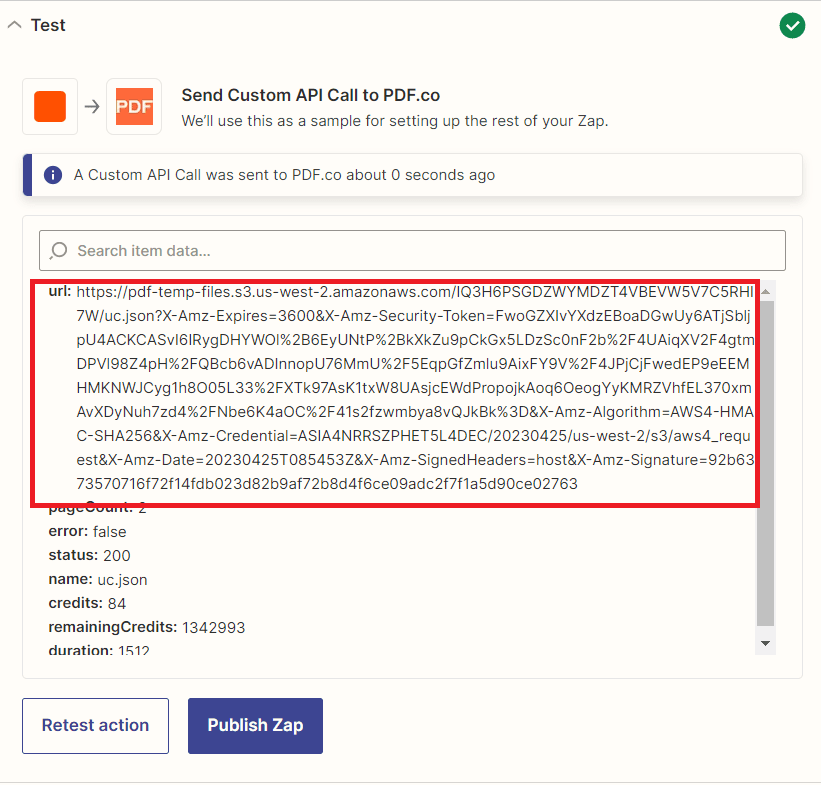
Step 11: Test Action Result
- Congratulations! The test of extracting data from PDF CVs using the PDF.co Document Parser endpoint was successful and the extracted data is available in JSON format. You can also choose other output formats such as XML and CSV based on your requirements. You may now copy the output URL and paste it into your browser to view the output and save it as a file.
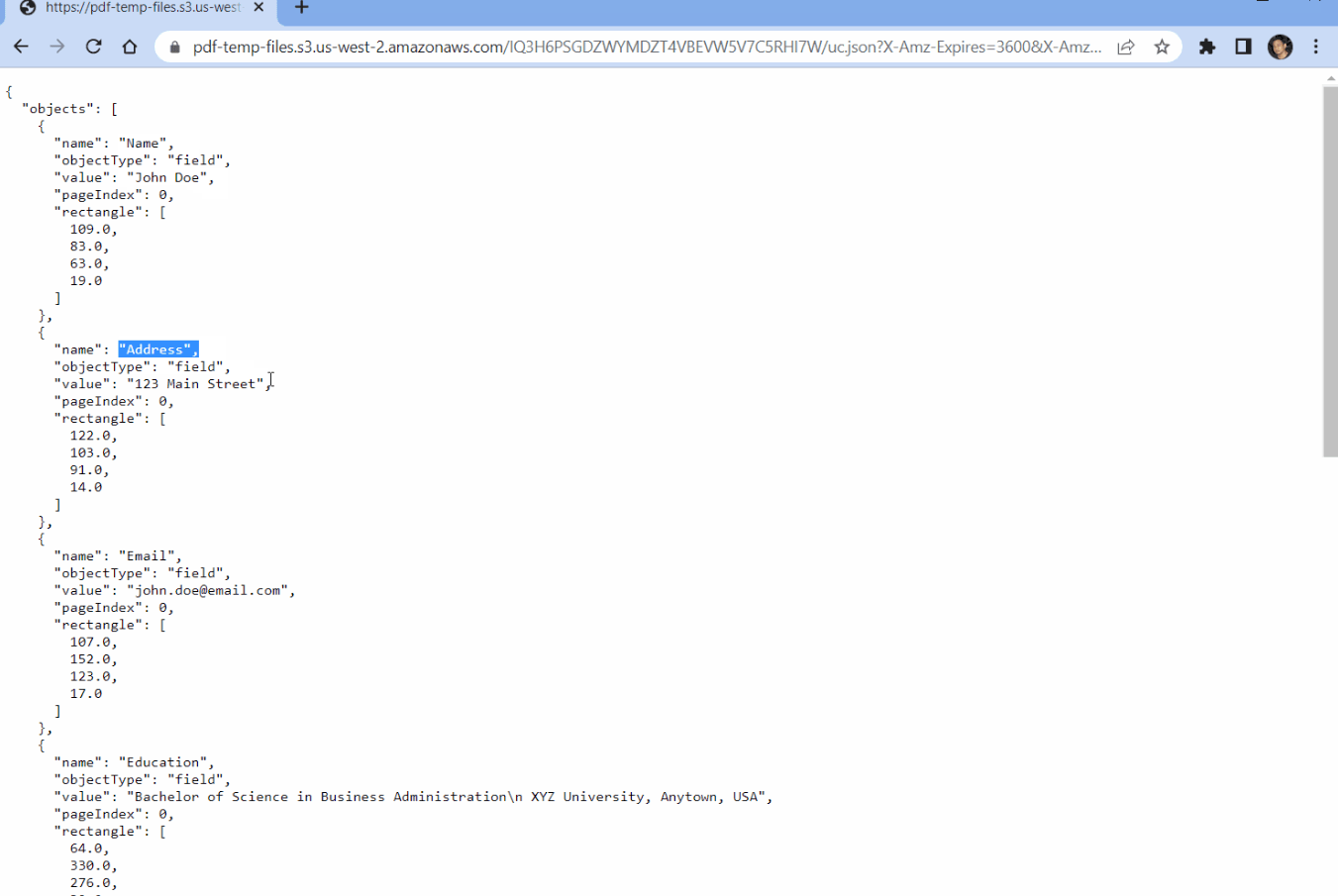
Step 12: Output
- Below is the extracted data from PDF CVs in JSON format.
In this tutorial, you have learned how to extract data from PDF CVs with different physical layouts using PDF.co and Zapier. Additionally, you have learned how to utilize the PDF.co Document Parser API to extract data from PDF documents.
Video Guide
Related Tutorials
