PDF Search API - Make PDF Searchable, Convert Scanned into Text Searchable PDF
The PDF Search API transforms scanned PDF documents, which may consist entirely or partly of scanned images, into searchable text PDFs. By employing OCR technology, it overlays an unseen text layer over your documents, enabling functionalities like text searching, text indexing, and more.
Our Web API is compatible with various programming languages, including PHP, JavaScript, C#, .NET, ASP.NET, Java, Visual Basic, among others, ensuring broad applicability.
We prioritize the security of documents processed through our Web API, ensuring all data is encrypted and protected. For detailed information on our security measures, please visit our security page at https://docs.pdf.co/security.
Sign Up for FreeBenefits of PDF Search API
No Licenses Required
The PDF.co web API operates on a credit-based system, eliminating the need for licenses. Obtain credits via subscription plans or purchase credit packs. For more information on the available options, check our pricing page.
Comprehensive Language Support
The PDF.co API supports an extensive array of programming languages, offering versatility for developers. Supported languages include PHP, JavaScript, Java, C#, .NET, ASP.NET, Visual Basic, among others.
Easy Integration
Our online QR code scanner is equipped with integrated OCR technology and comes with plugins for Zapier, Make, UiPath, and BluePrism. This setup allows for effortless connections with a wide range of popular applications, courtesy of our extensive offering of over 300 API integrations.
PDF Search API Sample & Demo
We have this sample scanned PDF to be used for this demo.

The code snippets below are in different programming languages. Using those code snippets, you can convert the sample scanned PDF file above into a text-searchable PDF.
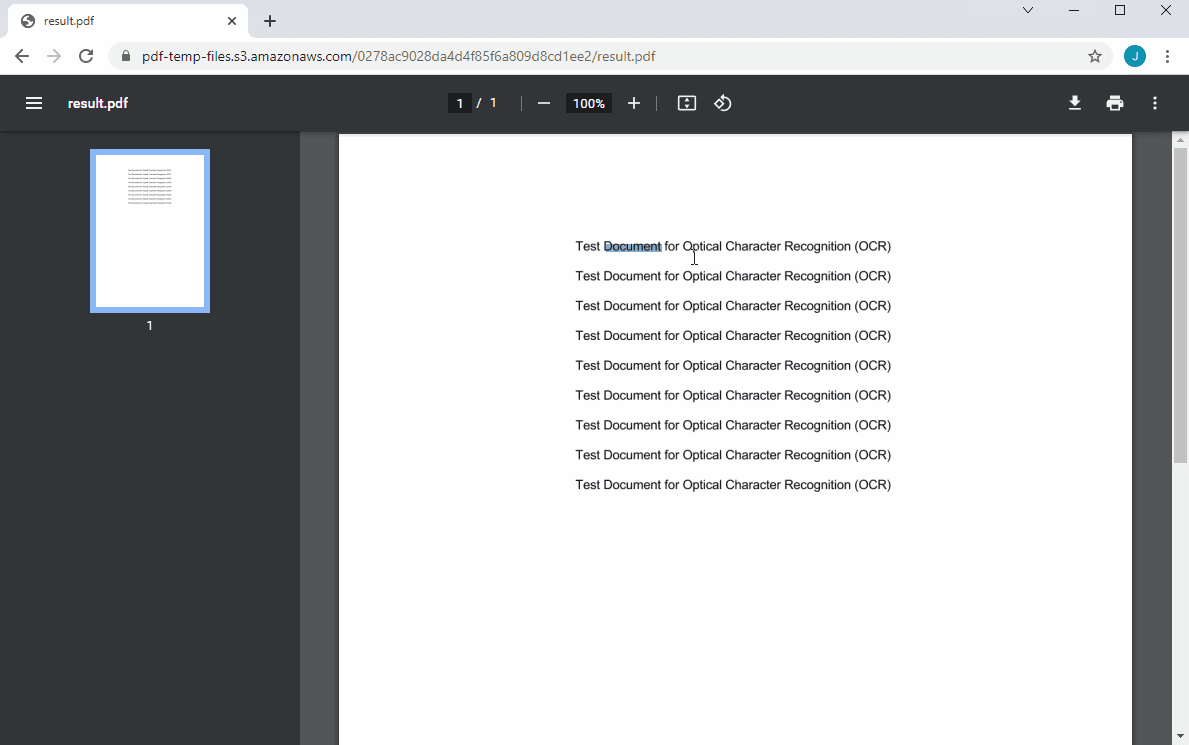
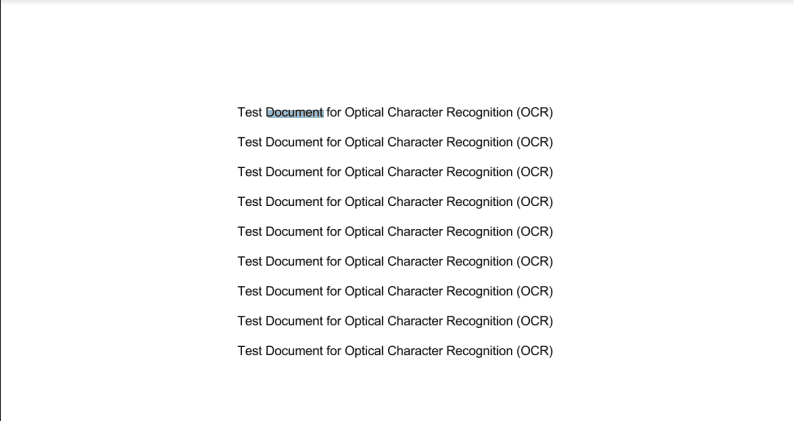
The result would look like this.
Before we proceed with the code, let us first check the /v1/pdf/makesearchable parameters and their uses.
Endpoint
- URL:
https://api.pdf.co/v1/pdf/makesearchable - Method: POST
- Parameters:
url: Required. Link to the source file.pages: Optional. Comma-separated list of page indices (or ranges) to process. IMPORTANT: the very first page starts with 0 (zero). To set a range use the dash –, for example:0, 2-5, 7-.expiration: Optional. Output link expiration in minutes. Default is 60 (i.e. 60 minutes or 1 hour). After this delay generated output file(s) (if any) will be auto-removed from PDF.co temporary files storage. Max allowed expiration period depends on your current subscription plan. To store permanent input files (e.g. re-usable images, PDF, documents), please use PDF.co built-in File Storage instead.encrypt: Optional. Enable encryption for the output file:trueorfalse.async: Optional. Runs processing asynchronously. ReturnsjobIdto use withjob/check:trueorfalse.name: Optional. Output file name.profiles: Optional. Must be a String. Set custom configuration. See profiles examples.
cURL Code Snippet
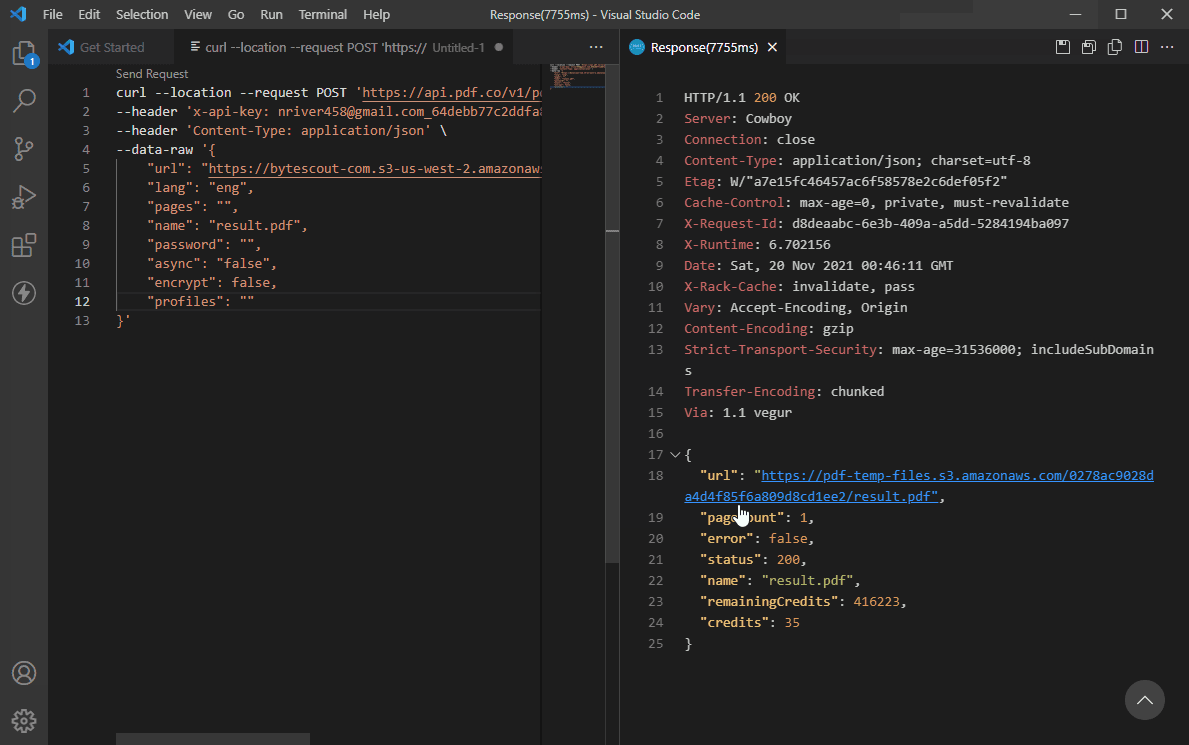
curl --location --request POST 'https://api.pdf.co/v1/pdf/makesearchable' \
--header 'x-api-key: YOUR_API_KEY' \
--header 'Content-Type: application/json' \
--data-raw '{
"url": "https://bytescout-com.s3-us-west-2.amazonaws.com/files/demo-files/cloud-api/pdf-make-searchable/sample.pdf",
"lang": "eng",
"pages": "",
"name": "result.pdf",
"password": "",
"async": "false",
"encrypt": false,
"profiles": ""
}'