Extract Text from PDF Invoice in Python using PDF.co Web API
In this tutorial, we will show you how to extract invoice data from PDF using Python using the PDF.co PDF to Text Web API. Below are images of our sample PDF and its text output.
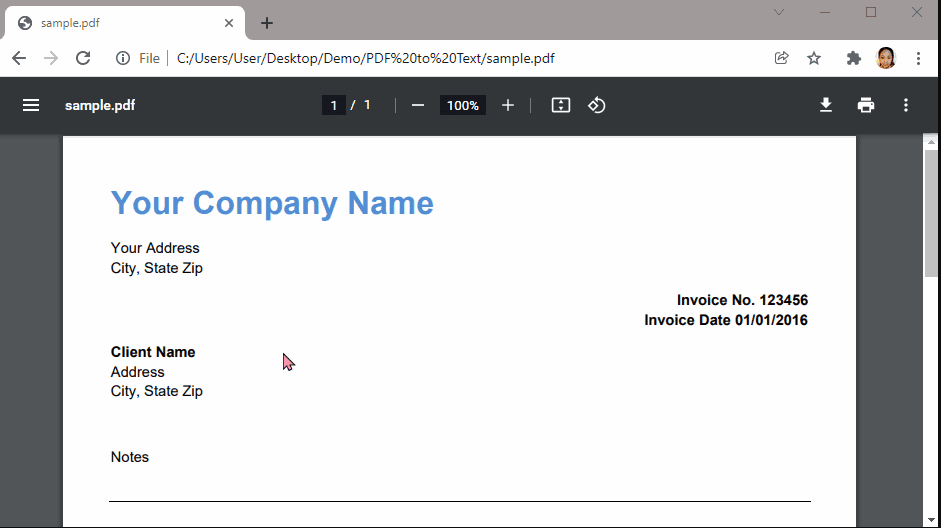
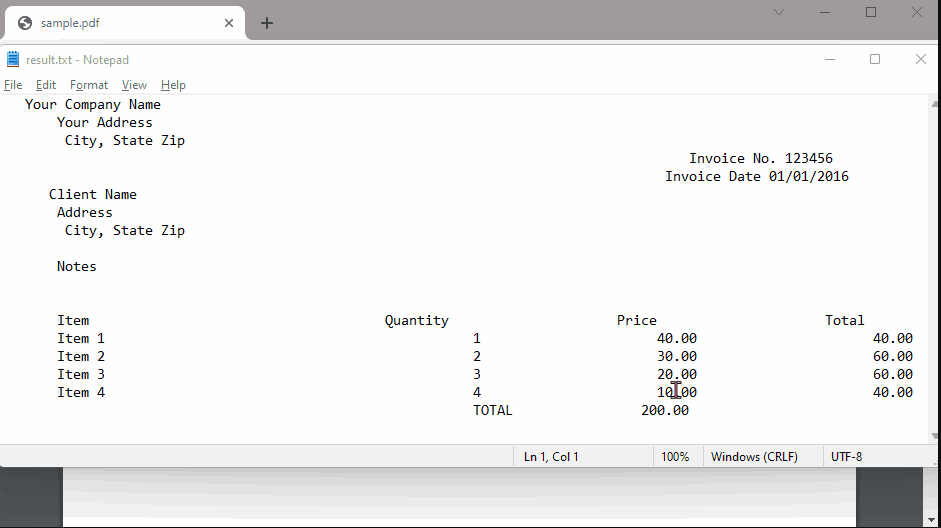
IN THIS TUTORIAL
Step 1: Download Files
We highly recommend that you copy or download the Python code and the sample PDF so you can follow along.
Step 2: Install Requests Module
That’s how we extract invoice data from PDF using Python. We will use the requests module in this sample Python program. You can install it in your machine by running this in the command line (cmd.exe) python -m pip install requests.

Step 3: Add API Key
Let’s open the Python code and add our PDF.co API Key in line 6. You can get your API key in your PDF.co dashboard.

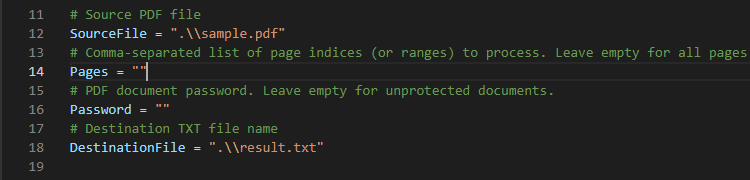
Step 4: Add Source File
In line 12, add your source PDF file path. You can add your desired output filename in line 18. You can learn more about PDF to Text Web API endpoints at our API Documentation.
Step 5: Run Program
Let’s now run our program and view the result in the folder.
In this tutorial, you learned how to extract invoice data from PDF using Python. You learned where to get your PDF.co API Key and add it to the program. You also learned how to easily extract text from PDF using the PDF to Text Web API.
Related Tutorials

