How to Extract PDF Meta Data (Keywords, Author, Title) using PDF.co Web API
PDF.co PDF Info Reader is a software tool that allows you to extract data from PDF files. It is designed to read and extract information from the metadata embedded within the PDF document. The metadata typically includes information such as the document’s title, author, subject, keywords, creation date, modification date, and more.
PDF Info Reader is useful for people who need to organize or sort large numbers of PDF documents quickly. By extracting the metadata, you can easily create a searchable index of your PDF files or categorize them based on the information contained in the metadata. Additionally, the software can be integrated with other applications, such as document management systems, to streamline your workflow. For example, it can help users to organize and search through their PDF files, or to track changes made to a document over time.
We have here a sample tutorial on extracting PDF Info using PDF.co Web API. Kindly check out the easy step-by-step guide below.
Here’s the sample PDF document that we will use in this tutorial.

IN THIS TUTORIAL
Step 1: Log into PDF.co Account
- First, log into your PDF.co account and click on the Request Tester menu.
Step 2: Request Tester Tool
Let’s set up the request tester configuration.
- For the Choose PDF.co API endpoint field, search and select the /pdf/info. This endpoint will extract basic information about input PDF files, PDF file security permissions, and other information.
- For the Input parameters field, override the URL param with a link or input with a file.
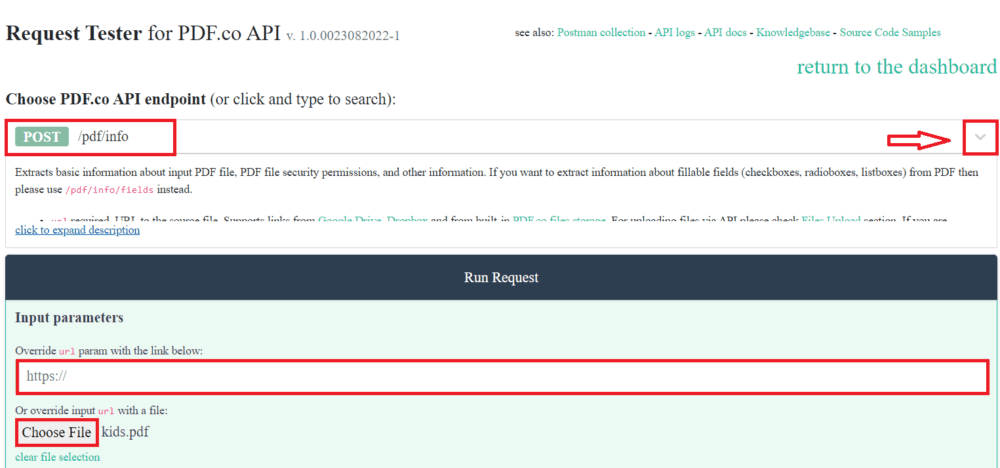
Once you are done setting up the configuration, click on the Run Request button.
Step 3: Run Request Result
- Great! The PDF.co successfully process our request, kindly click on the resulting URL to view the output or directly download the output file.

Step 4: JSON Output
- Here’s the extracted information from the PDF document in JSON format. It includes all possible metadata like keywords, author, title, and more.

This tutorial taught you how to extract PDF information using PDF.co Web API. You also learned how to use the v1/pdf/info endpoint to extract basic information about input PDF files, PDF file security permissions, and other information.
Related Tutorials

