Convert a Scanned PDF into a Searchable PDF in Python
Here’s a quick step-by-step tutorial where you will learn to convert PDF to searchable PDF using PDF.co Web API in Python.
In this demonstration, we will convert a scanned PDF to a searchable PDF in Python. We will use this /v1/pdf/make searchable endpoint to make the text searchable. Below are images of a sample scanned PDF and converted searchable PDF.
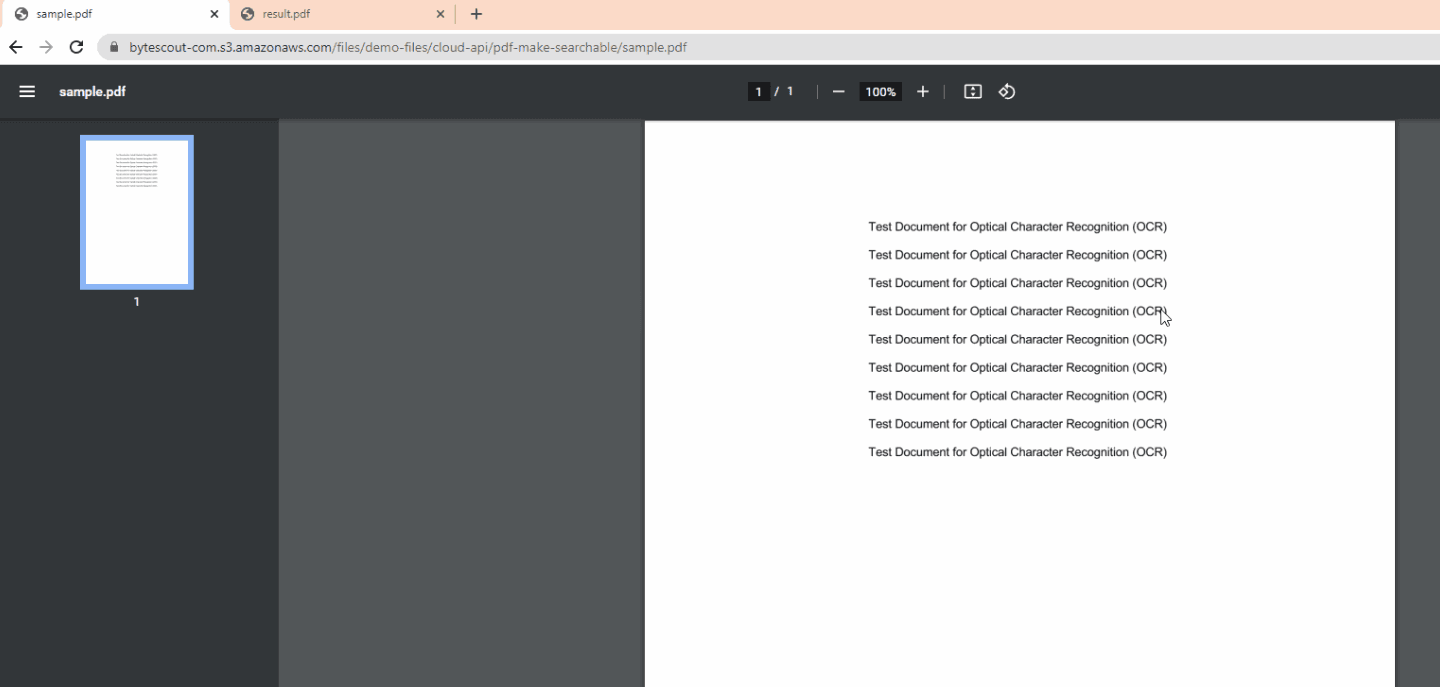
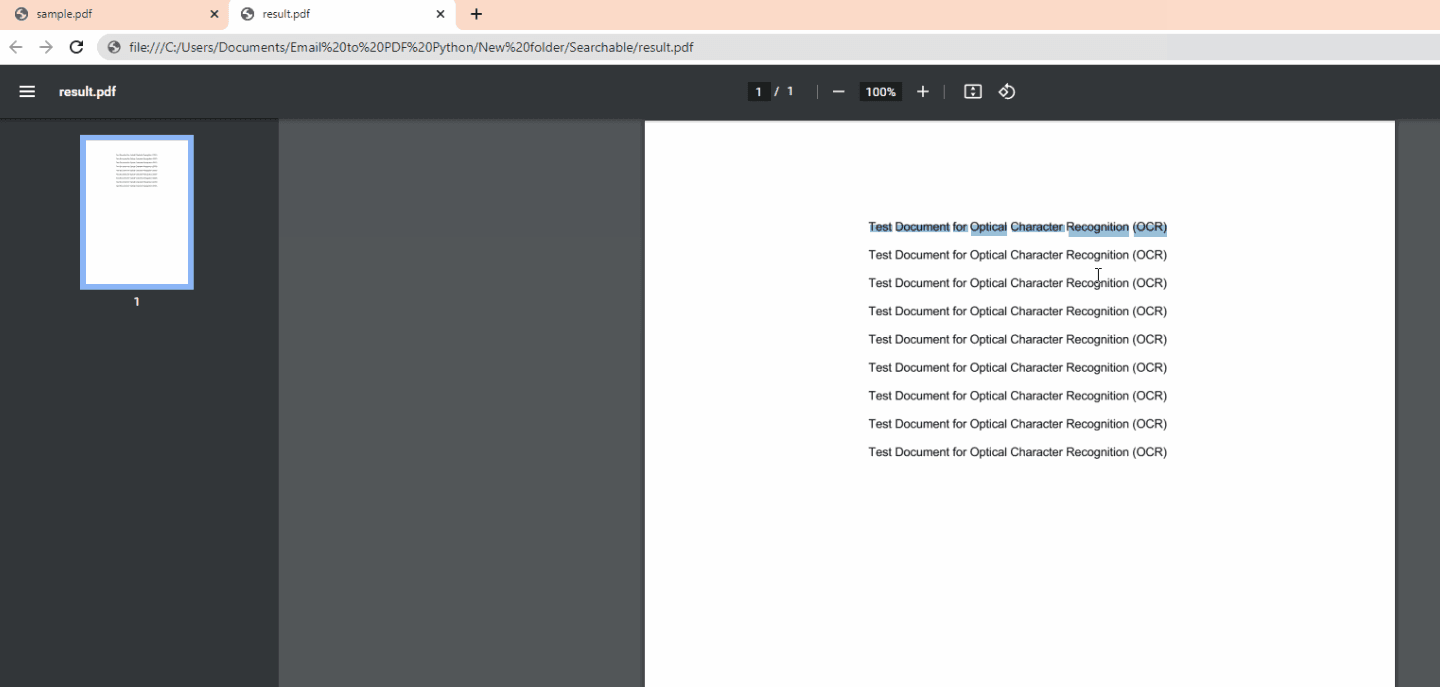
Step 1: Add Folder Files
First, let’s start by adding our sample scanned PDF to our Python program folder. You can download our sample PDF and Python sample code.
Step 2: Requests Module Installation
Next, if you don’t have the requests module yet, type in python -m pip install requests in your command line and it will install the requests module.
Step 3: Your API Key
Now, open the Python sample code and proceed to line 6. Then, add your PDF.co API key inside the double quote. You can get the API key in your PDF.co dashboard.

Step 4: Source File and PDF File Name
In lines 12 and 20, enter the source file PDF and type the PDF file name.
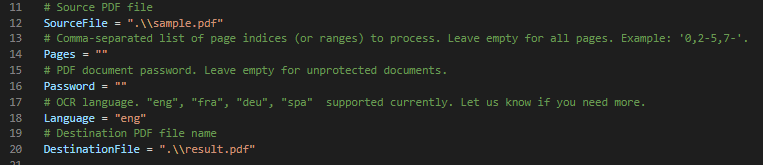
Step 5: Run Python Program
Let’s run the program and check your folder to see the result.

Step 6: PDF to Searchable PDF – Main Challenges
Converting scanned PDFs to searchable PDFs can be a challenging task due to several reasons:
Step 1: Lack of Text Recognition
Scanned PDF files are essentially images of text, and they do not contain searchable text that can be selected or copied. To make these files searchable, the text in the images must be recognized using Optical Character Recognition (OCR) software.
Step 2: Poor Image Quality
The quality of the scanned document image can impact OCR accuracy. Poor image quality, including low resolution, faded or blurry text and inconsistent lighting can make it difficult for OCR software to recognize the text accurately.
Step 3: Multiple Languages and Fonts
If the scanned PDF file contains text in multiple languages and fonts, the OCR software must be able to recognize and accurately convert each language and font type.
Step 4: Complex Document Structure
Some scanned PDF files may contain complex document structures, such as tables, columns, or graphs, which can make it challenging for OCR software to accurately recognize and convert the text.
Step 5: Time and Resource Intensive
Converting scanned PDFs to searchable PDFs can be a time-consuming and resource-intensive process, especially for large and complex documents. It may require a significant amount of computing power and processing time.
In this tutorial, you learned how to convert PDF into searchable PDF in Python using the PDF.co Web API. You learned how to use the PDF Make Text Searchable Web API to convert non-searchable to searchable PDF. You also learned how to install the requests module.
Video Guide
Related Tutorials

