Extract Text from Scanned PDF into CSV Format using PDF.CO Web API in C#
In this article, you will see how to extract text from a scanned PDF document into CSV format using PDF.CO Web API in C#.
PDF.CO Web API provides a rich set of functionalities for performing various operations on PDF documents. With PDF.CO, you can merge, split, and parse PDF documents. You can automatically fill form fields with PDF documents. Finally, you can scan the PDF documents into various formats, e.g., JSON, CSV, etc.
This article is divided into two parts. In the first part, you will see how to extract from a Native PDF document and store it in CSV format using C# and PDF.CO Web API.
In the second part, you will see how to extract text from a scanned PDF document and store it in CSV format.
Extract Text from a Native PDF and Store it in CSV
Extracting text from a scanned PDF is a straightforward process with PDF.CO Web API. In this section, you will create a C# console application that performs this task. So, let’s begin.
Creating the Program
The first step is to import the required C# libraries.
using System.Net;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;From the aforementioned libraries, you will manually need to install the “NewtonSoft” library.
To do so from the Microsoft Visual Studio IDE, go to “Tools-> NuGet Package Manager.” Search for the “Newtonsoft” library. Select the first package and click the “Install” button.
Next, you need to define C# variables that store the following information:
- The PDF.CO Web API key. You can get your API key by registering at https://app.pdf.co.
- The URL of the source PDF document that you want to search. The source PDF document for this article can be found at this link:
- The pages of the PDF document that you want to search. If you leave this field empty, all the pages of the PDF document will be scanned.
- The destination CSV document.
The following script performs the aforementioned tasks.
const String API_KEY = "*****************************";
const string SourceFile = @"https://bytescout-com.s3.amazonaws.com/files/demo-files/cloud-api/pdf-to-csv/sample.pdf";
const string Pages = "";
const string DestinationFile = @"D:\Datasets\result.csv";The next step is to define the WebClient class object. This object will be used to make calls to the PDF.CO Web API. Your PDF.CO API Key is also added to this object.
The script below creates the WebClient object and also stores the PDF.CO Web API call scans a PDF document and stores it into a CSV file.
WebClient webClient = new WebClient();
webClient.Headers.Add("x-api-key", API_KEY);
string url = "https://api.pdf.co/v1/pdf/convert/to/csv";Next, you need to create a parameter dictionary that contains parameter values that are passed to the Web API call.
The following creates a dictionary with the following parameters:
- The name of the destination file
- The URL of the source file
- The page number of the pages that you want to scan.
The following script also serializes the parameter dictionary.
// Prepare requests params as JSON
Dictionary<string, object> parameters = new Dictionary<string, object>();
parameters.Add("name", Path.GetFileName(DestinationFile));
parameters.Add("pages", Pages);
parameters.Add("url", SourceFile);
// Convert dictionary of params to JSON
string jsonPayload = JsonConvert.SerializeObject(parameters);You are now ready to make a call to the PDF.CO Web API scans the source PDF document and stores it in a CSV file.
The following script uses the UploadString() method of the WebClient object to make the API call. The code is executed inside a try/catch block.
The response from the API call is parsed as a JSON object.
If the response contains an error, the error message is displayed. Else, the URL of the destination CSV file is parsed, and the CSV file is downloaded to the local file system.
In case of an exception, the exception message is displayed on the console.
try
{
string response = webClient.UploadString(url, jsonPayload);
JObject json = JObject.Parse(response);
if (json["error"].ToObject<bool>() == false)
{
// Get URL of generated CSV file
string resultFileUrl = json["url"].ToString();
// Download CSV file
webClient.DownloadFile(resultFileUrl, DestinationFile);
Console.WriteLine("Generated CSV file saved as \"{0}\" file.", DestinationFile);
}
else
{
Console.WriteLine(json["message"].ToString());
}
}
catch (WebException e)
{
Console.WriteLine(e.ToString());
}Finally, the WebClient class object is disposed of.
webClient.Dispose();
Console.WriteLine();
Console.WriteLine("Press any key...");
Console.ReadKey();Complete Code
Here is the complete C# code that scans a native PDF document and stores it into a CSV file.
using System.Net;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;
namespace PDFCOWebApiExample
{
public class Program
{
const String API_KEY = "****************************";
const string SourceFile = @"https://bytescout-com.s3.amazonaws.com/files/demo-files/cloud-api/pdf-to-csv/sample.pdf";
const string Pages = "";
const string DestinationFile = @"D:\Datasets\result.csv";
static void Main(string[] args)
{
WebClient webClient = new WebClient();
webClient.Headers.Add("x-api-key", API_KEY);
string url = "https://api.pdf.co/v1/pdf/convert/to/csv";
// Prepare requests params as JSON
Dictionary<string, object> parameters = new Dictionary<string, object>();
parameters.Add("name", Path.GetFileName(DestinationFile));
parameters.Add("pages", Pages);
parameters.Add("url", SourceFile);
// Convert dictionary of params to JSON
string jsonPayload = JsonConvert.SerializeObject(parameters);
try
{
string response = webClient.UploadString(url, jsonPayload);
JObject json = JObject.Parse(response);
if (json["error"].ToObject<bool>() == false)
{
// Get URL of generated CSV file
string resultFileUrl = json["url"].ToString();
// Download CSV file
webClient.DownloadFile(resultFileUrl, DestinationFile);
Console.WriteLine("Generated CSV file saved as \"{0}\" file.", DestinationFile);
}
else
{
Console.WriteLine(json["message"].ToString());
}
}
catch (WebException e)
{
Console.WriteLine(e.ToString());
}
webClient.Dispose();
Console.WriteLine();
Console.WriteLine("Press any key...");
Console.ReadKey();
}
}
}
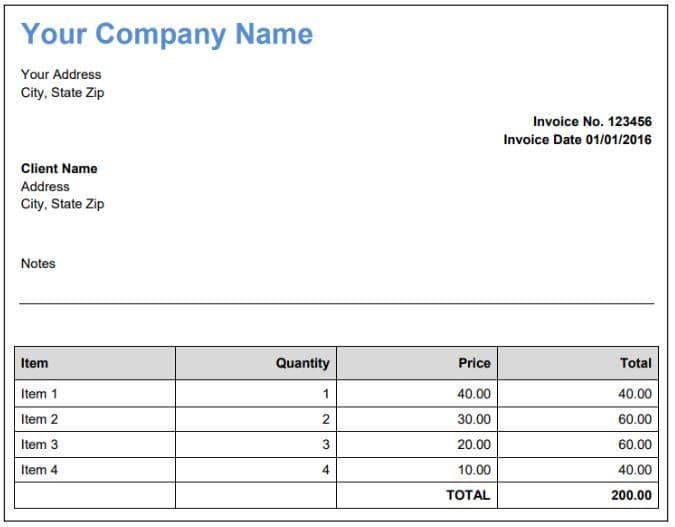
Input PDF Document
Our input PDF document looks like this. You can see it contains some free text and a table.
Output CSV File
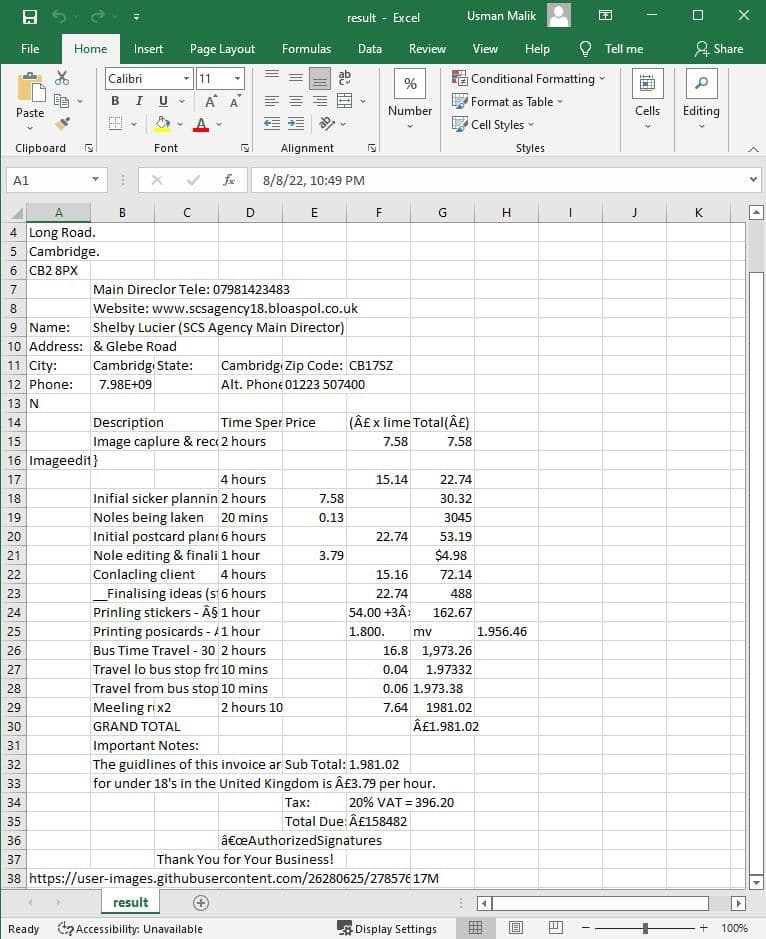
The output CSV file is generated by the PDF.CO Web API looks like the one below. You can see that the document structure in CSV is retained.
Extract Text from a Scanned PDF and Store it in CSV
Extracting text from a native digitized PDF document is easier. On the other hand, extracting text from a scanned PDF document is extremely difficult.
However, with PDF.CO Web API, you can extract text from a scanned PDF document with very high accuracy. And this is what you will see in this section.
You will extract text from a scanned PDF document uploaded from your file system and store the text in a CSV file.
The process is very similar to what you have already seen. So, let’s begin without ado.
Creating the Program
The following script imports the required libraries.
using System.Net;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;The following script stores the API key, the source file path, the number of pages, and the destination file name in C# variables.
const String API_KEY = "***************************";
const string SourceFile = @"D:\Datasets\scanned_invoice.pdf";
const string Pages = "";
const string DestinationFile = @"D:\Datasets\result.csv";Next, you need to create a WebClient object which stores the PDF.CO Web API key, as shown in the following script.
WebClient webClient = new WebClient();
webClient.Headers.Add("x-api-key", API_KEY);You will need to upload your PDF file to some cloud before you can extract text from it. As an example, the following script fetches the URL path from the PDF.CO cloud where your PDF file will be uploaded.
string query = Uri.EscapeUriString(string.Format(
"https://api.pdf.co/v1/file/upload/get-presigned-url?contenttype=application/octet-stream&name={0}", Path.GetFileName(SourceFile)));The script below uploads your input PDF file.
try
{
string response = webClient.DownloadString(query);
JObject json = JObject.Parse(response);
if (json["error"].ToObject<bool>() == false)
{
// Get URL to use for the file upload
string uploadUrl = json["presignedUrl"].ToString();
string uploadedFileUrl = json["url"].ToString();
// 2. UPLOAD THE FILE TO CLOUD.
webClient.Headers.Add("content-type", "application/octet-stream");
webClient.UploadFile(uploadUrl, "PUT", SourceFile); // You can use UploadData() instead if your file is byte[] or Stream
webClient.Headers.Remove("content-type");
The rest of the script is similar to what you have already seen. You define a variable that stores the PDF.CO Web API call for converting PDF to CSV.
A parameter dictionary is then defined, which stores the parameters for the PDF.CO Web API call. The dictionary is also serialized.
// 3. Convert PDF to CSV
string url = "https://api.pdf.co/v1/pdf/convert/to/csv";
Dictionary<string, object> parameters = new Dictionary<string, object>();
parameters.Add("name", Path.GetFileName(DestinationFile));
parameters.Add("pages", Pages);
parameters.Add("url", uploadedFileUrl);
// Convert dictionary of params to JSON
string jsonPayload = JsonConvert.SerializeObject(parameters);
Finally, inside the try/catch block, the WebClient class object makes an API call. The response from the API is parsed as a JSON object. If the response doesn’t contain any error, the URL of the converted CSV file is parsed, and the CSV file is downloaded to the local file system.
Look at the script below for reference.
try
{
response = webClient.UploadString(url, jsonPayload);
json = JObject.Parse(response);
if (json["error"].ToObject<bool>() == false)
{
// Get URL of generated CSV file
string resultFileUrl = json["url"].ToString();
// Download CSV file
webClient.DownloadFile(resultFileUrl, DestinationFile);
Console.WriteLine("Generated CSV file saved as \"{0}\" file.", DestinationFile);
}
else
{
Console.WriteLine(json["message"].ToString());
}
}
catch (WebException e)
{
Console.WriteLine(e.ToString());
}
}
else
{
Console.WriteLine(json["message"].ToString());
}
}
catch (WebException e)
{
Console.WriteLine(e.ToString());
}Finally, the WebClient is disposed of.
webClient.Dispose();
Console.WriteLine();
Console.WriteLine("Press any key...");
Console.ReadKey();Complete Code to Extract Text from Scanned PDF
using System.Net;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;
namespace ByteScoutWebApiExample
{
class Program
{
const String API_KEY = "***************************";
const string SourceFile = @"D:\Datasets\scanned_invoice.pdf"
const string Pages = "";
const string DestinationFile = @"D:\Datasets\result.csv";
static void Main(string[] args)
{
WebClient webClient = new WebClient();
webClient.Headers.Add("x-api-key", API_KEY);
string query = Uri.EscapeUriString(string.Format(
"https://api.pdf.co/v1/file/upload/get-presigned-url?contenttype=application/octet-stream&name={0}",
Path.GetFileName(SourceFile)));
try
{
string response = webClient.DownloadString(query);
JObject json = JObject.Parse(response);
if (json["error"].ToObject<bool>() == false)
{
// Get URL to use for the file upload
string uploadUrl = json["presignedUrl"].ToString();
string uploadedFileUrl = json["url"].ToString();
// 2. UPLOAD THE FILE TO CLOUD.
webClient.Headers.Add("content-type", "application/octet-stream");
webClient.UploadFile(uploadUrl, "PUT", SourceFile); // You can use UploadData() instead if your file is byte[] or Stream
webClient.Headers.Remove("content-type");
// 3. Convert PDF to CSV
string url = "https://api.pdf.co/v1/pdf/convert/to/csv";
Dictionary<string, object> parameters = new Dictionary<string, object>();
parameters.Add("name", Path.GetFileName(DestinationFile));
parameters.Add("pages", Pages);
parameters.Add("url", uploadedFileUrl);
// Convert dictionary of params to JSON
string jsonPayload = JsonConvert.SerializeObject(parameters);
try
{
response = webClient.UploadString(url, jsonPayload);
json = JObject.Parse(response);
if (json["error"].ToObject<bool>() == false)
{
// Get URL of generated CSV file
string resultFileUrl = json["url"].ToString();
// Download CSV file
webClient.DownloadFile(resultFileUrl, DestinationFile);
Console.WriteLine("Generated CSV file saved as \"{0}\" file.">, DestinationFile); }
else
{
Console.WriteLine(json["message"].ToString());
}
}
catch (WebException e)
{
Console.WriteLine(e.ToString());
}
}
else
{
Console.WriteLine(json["message"].ToString());
}
}
catch (WebException e)
{
Console.WriteLine(e.ToString());
}
webClient.Dispose();
Console.WriteLine();
Console.WriteLine("Press any key...");
Console.ReadKey();
}
}
}Input Scanned PDF Document
The input scanned PDF document looks like the one below. Basically, it is a scanned receipt.
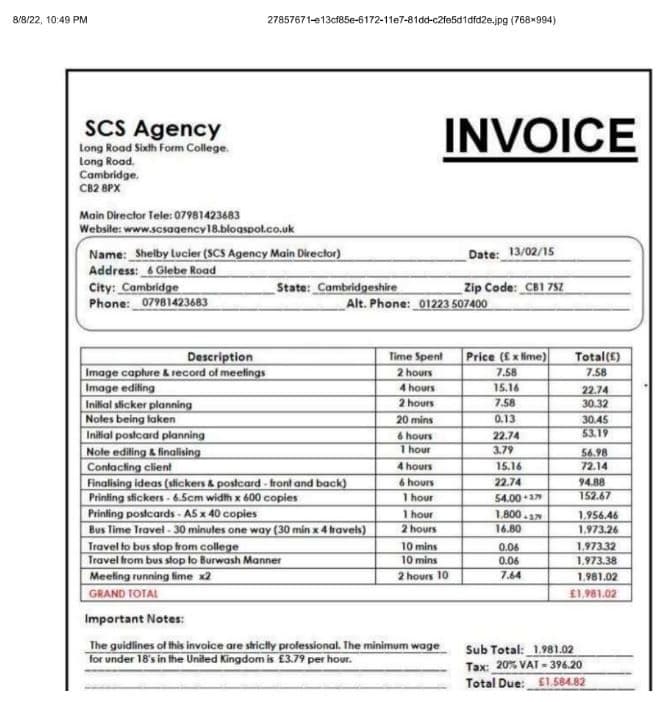
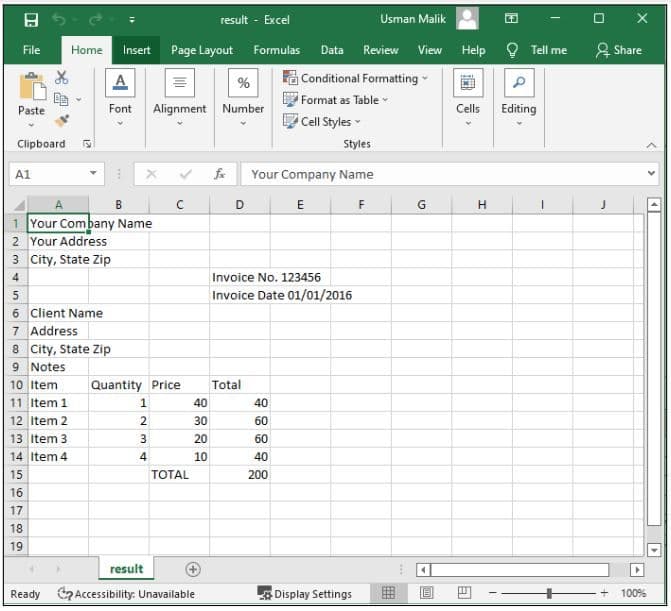
Output
The output CSV file looks like this: