Extract Hyperlinks from a PDF Using Python and PDF.co Web API
In this guide, we will demonstrate how to extract hyperlinks from a PDF file using Python and the PDF.co Web API. We will work with a sample PDF document to retrieve the hyperlinks.

Step 1: Install Pip Request
To begin, we need to install the requests module, which will help us make HTTP requests to the PDF.co API. In your command line or terminal, type the following command and hit Enter to install the requests library: python -m pip install requests
Step 2: Source Code Samples
Next, copy the Python sample code from this link. Then, paste the code into your editor (e.g., Visual Studio Code, PyCharm, or any editor of your choice).
Step 3: Configure the Python Code
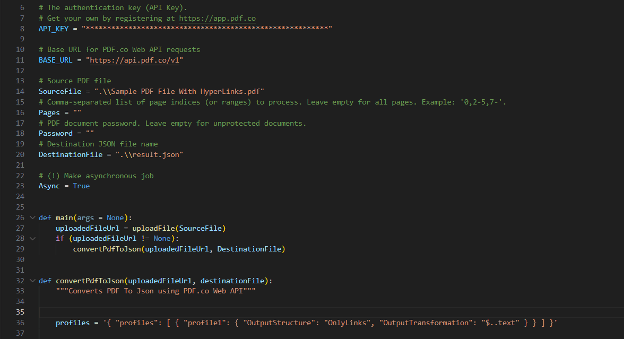
Now, let's set up the Python code with your specific configurations:
- API Key: Insert your API Key in the designated area within the code. You can find your API Key on your PDF.co Dashboard.
- Source File:Specify the name of the PDF file from which you want to extract hyperlinks.
- Output File Name: Enter the desired name for the output JSON file.
- Profiles: We will use an advanced conversion profile with the following settings:
{ "OutputStructure": "OnlyLinks", "OutputTransformation": "$..text" }.This configuration will extract all hyperlinks present in the PDF.
For this demonstration, we will use Asynchronous mode for conversion. This will allow us to process the conversion in the background, making the program more efficient.
Step 4: Save the Python Program
Once you have configured the code settings, save the Python program in your preferred directory.
Step 5: Execute the Program
After saving the program, execute the Python script. If everything is set up correctly, the program will successfully extract the hyperlinks from your PDF document. Once the execution is complete, navigate to your Python folder to find the generated JSON file.

Step 6: View JSON Result
Finally, open the output JSON file in your preferred JSON viewer. You will see the extracted hyperlinks neatly formatted in JSON.
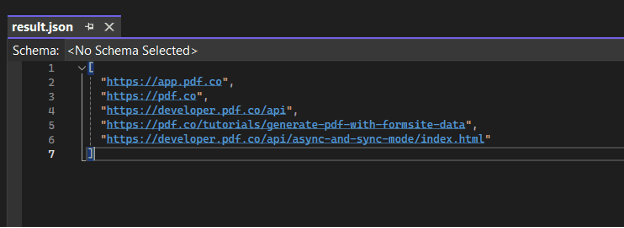
In this article, you learned how to extract hyperlinks from a PDF in Python with PDF.co Web API.
Related Tutorials

