Calling PDF.co Web APIs in a Python Application
PDF.co provides a set of tools to perform different types of PDF handling and manipulation tasks such as PDF merging and splitting, searching and deleting texts within a PDF, converting a PDF to different formats, and vice versa.
You can integrate PDF.co tools into various API development platforms such as Zapier, Make, etc. PDF.co also provides a Web API interface that you call to perform different functionalities within a specific programming language such as Java, C#, Python, etc.
To see the details of all the Web API functionalities provided by PDF.co, check out the official documentation.

Converting Non-Searchable PDF to a Searchable PDF
The following script imports the Python libraries needed to call the PDF.co Web APIs, into your Python application.
import os
import requestsTo make a call to PDF.co Web API that converts a non-searchable PDF to a searchable PDF, you need to set the values for the following parameters.
API_KEY: You can get it when you create an account with PDF.coBASE_URL: This is the base URL for the PDF.co Web API. All API functionalities exist at this base location.SourceFileURL: This is the URL to the non-searchable input PDF file that you want to convert to a searchable PDF. In our case the sample source file looks like this:

If you hover the mouse over the text and try to select it, you will see that the text is neither selectable nor searchable.
4. Pages (optional): Specify the pages of your PDF document that you want to convert. Leaving this field empty means all pages should be converted
5. Language (optional): The language of the input PDF document
6. DestinationFile: Name of the output searchable PDF document
API_KEY = "***********************************************"
BASE_URL = "https://api.pdf.co/v1"
SourceFileURL = "https://bytescout-com.s3.amazonaws.com/files/demo-files/cloud-api/pdf-make-searchable/sample.pdf"
Pages = ""
Password = ""
Language = "eng"
DestinationFile = ".\\result.pdf"The next step is to create a parameter dictionary that contains the parameters that you specified in the previous step.
parameters = {}
parameters["name"] = os.path.basename(DestinationFile)
parameters["password"] = Password
parameters["pages"] = Pages
parameters["lang"] = Language
parameters["url"] = SourceFileURLAfter specifying the parameter dictionary, you have to specify the URL for the API call that you want to make. In the case of converting a non-searchable PDF document to a PDF document, you need to make the following API call.
url = "{}/pdf/makesearchable".format(BASE_URL)Finally, to actually make the call, you can pass the URL for the API call, the parameters that you defined, and your API key as parameters to the post() method of the request module. Look at the following script for reference:
response = requests.post(url, data=parameters, headers={ "x-api-key": API_KEY })The post method returns the response object which contains information about the converted searchable PDF document in JSON (Javascript Object Notation). If the response.status_code is 200, it means that the operation has been successful. In that case, you can simply fetch the “URL” attribute from the JSON object, which returns the URL of the converted searchable PDF document. The following script prints the URL of the converted document.
searchable_pdf_url = ""
if (response.status_code == 200):
json = response.json()
if json["error"] == False:
# Get URL of result file
searchable_pdf_url = json["url"]
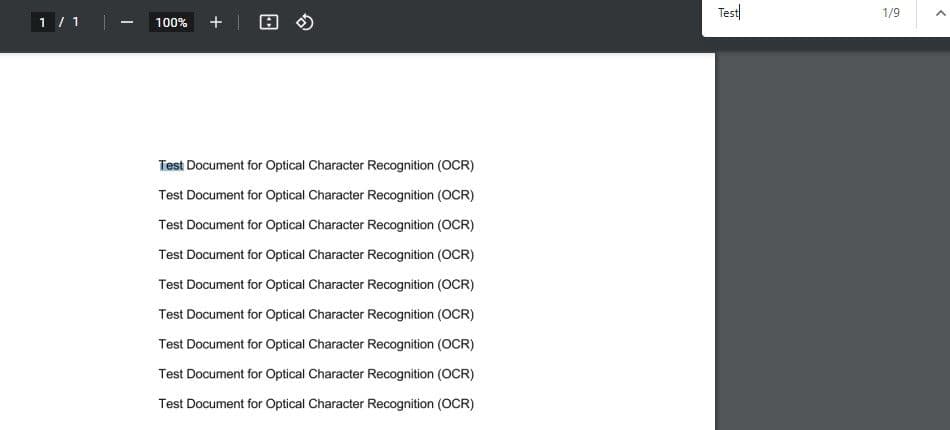
print(searchable_pdf_url)If you go to the URL of the converted PDF document and try to search for the text, you will find that the text is now selectable as well as searchable.
Searching and Deleting Text within a PDF Document
The process of making Python API calls to the PDF.co Web API is very similar for different types of calls.
In this section, you will see how to search text within a PDF document and delete it using a PDF.co Web API call in the Python programming language.
The first step as you have seen in the previous section is to import the required Python libraries and set parameter values:
import os
import requests
API_KEY = "***********************************************"
BASE_URL = "https://api.pdf.co/v1"
SourceFileURL = "https://bytescout-com.s3.amazonaws.com/files/demo-files/cloud-api/pdf-split/sample.pdf"
Pages = ""
Password = ""
Language = "eng"
DestinationFile = ".\\result2.pdf"The details of these parameters have already been mentioned in the previous section.
The next step is to define the parameters dictionary for the API call as follows.
parameters = {}
parameters["name"] = os.path.basename(DestinationFile)
parameters["password"] = Password
parameters["url"] = SourceFileURL
parameters["searchString"] = "conspicuous"You have already seen most of the above parameters in the previous section. Here one parameter value i.e. “searchString” is new. This parameter specifies the text that you want to search and delete. The word that you will be deleting is “conspicuous” which lies in the first line of our sample document as shown below:

The next step is to specify the URL for the actual call that deletes text from your PDF document.
url = "{}/pdf/edit/delete-text".format(BASE_URL)Finally, you can make a call to the PDF.co API via the post() method of the requests module. As you saw earlier, you have to pass the call for the URL, the parameter dictionary, and the API key as parameters to the post() method.
response = requests.post(url, data=parameters, headers={ "x-api-key": API_KEY })The post() method returns a response object which contains JSON data that you can use to fetch the URL of the modified PDF document with deleted text.
deleted_text_pdf_url = ""
if (response.status_code == 200):
json = response.json()
if json["error"] == False:
# Get URL of result file
deleted_text_pdf_url = json["url"]
print(deleted_text_pdf_url)If you go to the URL of the converted document, you will see that the text “conspicuous” is removed as shown in the following image:

Splitting a PDF Document into Multiple Pages
The process of splitting a PDF document into multiple pages via PDF.co Web API call is similar to the previous two tasks you performed in this article.
You first have to import the required Python libraries and set some parameters as shown in the script below. You have seen the details of these parameter values in the first section. The most noteworthy parameter, in this case, is the Pages parameter. Here we specify that we split our input document into four pages.
import os
import requests
API_KEY = "***********************************************"
BASE_URL = "https://api.pdf.co/v1"
SourceFileURL = "https://bytescout-com.s3.amazonaws.com/files/demo-files/cloud-api/pdf-split/sample.pdf"
Pages = "1,2,3,4"
Password = ""The next step is to create a parameter dictionary containing the parameter values that you specified in the previous.
parameters = {}
parameters["pages"] = Pages
parameters["url"] = SourceFileURLAs you saw in the previous two sections, you have to specify the URL for the call to the PDF.co Web API. Here is the URL link that calls the PDF.co Web API splits a document into multiple documents.
url = "{}/pdf/split".format(BASE_URL)The script below makes a request to the PDF.co Web API using the post() method of the Python requests module.
response = requests.post(url, data=parameters, headers={ "x-api-key": API_KEY })From the response object returned by the post() method, you can get the list of URLs corresponding to each of the split pages in the output. Clicking on the first link takes you to the first page, clicking the second link takes you to the 2nd page, and so on.
PDF.co provides a Web API that you can call to perform any operation supported by the PDF.co platform on your PDF document. In this article, you saw how the Python programming language can be used to make calls to the PDF.co Web API to perform different operations. You saw how to convert a non-searchable PDF document to a searchable PDF document. You also saw how to search and delete text from a PDF document, and finally, you studied how to split a PDF document into multiple pages.
Related Tutorials

