You can read more on PDF.co endpoints in our API Documentation.
How to Use PDF Template with Reusable Content Blocks/Fields
This guide provides a step-by-step tutorial, complete with sample source code, on how to create a PDF from an HTML template featuring reusable content blocks or fields. By following this Python tutorial and utilizing PDF.co’s “Convert HTML template to PDF” API, you can easily incorporate reusable elements like headers and footers into your PDF documents.

PDF Converter Web API
PDF.co offers a web API called "HTML to PDF Web API" that allows users to generate PDF pages from various sources:
- HTML: Users can create PDFs directly from raw HTML code.
- URL: This API can be integrated into existing applications, enabling users to convert HTML pages from web URLs into PDF files.
- HTML Templates: Users have the capability to produce PDF files from HTML templates. These templates can include variables, reusable content, conditional logic, and custom code like barcodes. The templates use the "Mustache" and "Handlebars" frameworks to facilitate these features.
API Features
The "HTML to PDF Web API" offered by PDF.co goes beyond just customizing headers and footers. As detailed in the "PDF Template with Built-in Barcode" article, this API provides a range of additional functionalities. However, the article primarily focuses on its ability to incorporate reusable content into HTML templates, including headers and footers. It also delves into the API's capabilities to insert custom information into PDF pages, such as the document title, location of the document, current page number, print date, and total number of pages.
Endpoint Parameters
- HTML: This required parameter takes HTML code, which can be directly inputted or read from template files using Python’s built-in file reading methods.
- margins: An optional parameter that allows users to set the page margins.
- orientation: Also optional, this parameter sets the page orientation, with 'portrait' as the default setting. Users can choose between 'portrait' or 'landscape' orientations.
- paperSize: This optional parameter enables the setting of specific page sizes such as A2, A3, and A4.
- printBackground: Another optional parameter that allows users to enable or disable background printing in the PDF.
- header: Users can utilize this optional parameter to add a custom HTML header to the entire PDF file.
- footer: Similar to the header, this optional parameter allows for the addition of a custom HTML footer to the entire PDF file.
- async: An optional boolean parameter set to "false" by default, which, when enabled, allows tasks to be performed asynchronously.
- templateData: This optional parameter is used to insert values into HTML macros, such as adding a QR code’s value.
- profiles: An optional parameter designed for setting custom configurations as needed.
How to Use PDF.co Web API to Add Header
The sample Python code provided below illustrates how to use the conversion API to integrate a custom header into a PDF document. This example employs inline HTML to construct a simple HTML template, which incorporates macros for generating a barcode. This serves as an introductory demonstration on how to use the API for embedding built-in barcodes into your documents. Additionally, users have the flexibility to customize the barcode by altering the `templateData` value.
In this specific instance, the Python code adds a basic header containing the text "My Document" above the QR code in the PDF file. This example not only shows how to add text headers but also how to incorporate dynamic content like barcodes, providing a practical insight into the API's capabilities for document customization.
import os
import requests # pip install requests
# The authentication key (API Key).
# Get your own by registering at https://app.pdf.co
API_KEY = "**************************************"
# Base URL for PDF.co Web API requests
BASE_URL = "https://api.pdf.co/v1"
# Runs processing asynchronously. Returns Use JobId that the user may use with /job/check to check the state of the processing (possible
states: working, failed, aborted, and success). Must be one of: true,false.
Async = "False"
def main(args = None):
convertFromHTML()
def convertFromHTML():
"""Converts HTML template to PDF using PDF.co Web API"""
# Prepare requests params as JSON
# See documentation: https://docs.pdf.co
parameters = {}
parameters["html"] ="<div><img src=\" [[ barcode:QRCode {{variable1}}]]\" /></div> "
parameters["templateData"] = "{\"variable1\": \"12345\"}"
parameters["name"] = "result.pdf"
parameters["async"] = Async
parameters["header"]="<span style='width:100%'><spanstyle='font-size:10px;'>My Document</span>.</span>"
# Prepare URL for 'Convert from HTML' API request
url = "{}/pdf/convert/from/html".format(BASE_URL)
# Execute request and get response as JSON
response = requests.post(url, data=parameters, headers={ "x-api-key":API_KEY })
if (response.status_code == 200):
json = response.json()
print(json)
else:
print(f"Request error: {response.status_code} {response.reason}")
if (__name__ == '__main__'):
main()Step-by-Step Guide
- Importing Modules: The code begins by importing the
requestsmodule, essential for making HTTP requests in Python. - API Key and Base URL: It sets up necessary variables like
API_KeyandbaseURLto authenticate and direct requests to the PDF.co Web API. Users need to obtain their API Key by signing up or logging into the PDF.co website. - Asynchronous Setting: The variable
Asyncis declared and set totrue. This setting is used in the API call to make the request asynchronous, allowing the API to process the task in the background. - Main Method Definition: A main method is defined to orchestrate the API call by invoking the
convertFromHTMLfunction. - ConvertFromHTML Function: This function is responsible for:
- Setting API parameters such as
HTML,templateData, andheader. - Preparing the API request URL.
- Making the API call and awaiting the JSON response.
- Setting API parameters such as
- Handling Responses:
- If the response status code is
200, indicating a successful request, the JSON response is printed, showing the outcome of the PDF conversion. - If there's an error (response code other than
200), the error code and its reason are displayed, providing insight for troubleshooting the issue.
- If the response status code is
Output
Following is the screenshot to demonstrate the above code’s output:
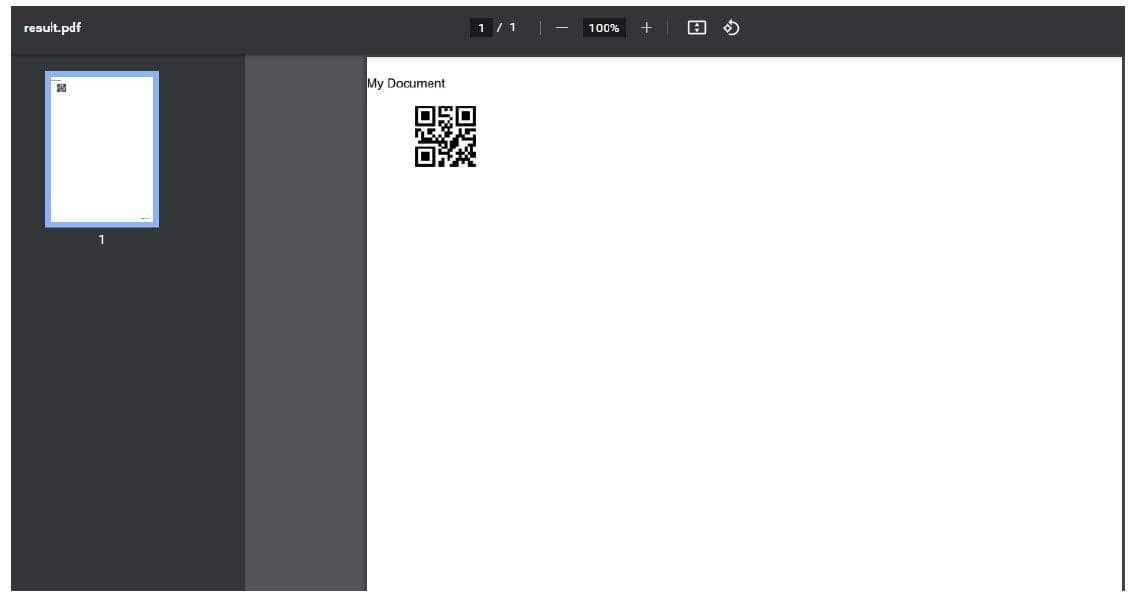
Adding Advanced Header to the PDF File
Following is the sample of an advanced header that uses multiple spans and CSS styles to create a PDF file header. Also, this code teaches how to create the subheaders on either side of the PDF page.
"<div style='width:100%'>
<span style='font-size:10px;margin-left:20px;width:50%;float:left'>LEFT SUBHEADER</span>
<span style='font-size:8px;width:30%;float:right'>RIGHT SUBHEADER</span>
</div>"Using PDF.co Web API to Add Footer
The Python sample code below demonstrates how to use the PDF.co Web API to add a custom footer to a PDF file, while also generating a QR code. This code modifies the previous example, which added a header, by replacing the header with a footer parameter.
import os
import requests # pip install requests
# The authentication key (API Key).
# Get your own by registering at https://app.pdf.co
API_KEY = "**************************************"
# Base URL for PDF.co Web API requests
BASE_URL = "https://api.pdf.co/v1"
# Runs processing asynchronously.
Async = "False"
def main(args = None):
convertFromHTML()
def convertFromHTML():
"""Converts HTML template to PDF using PDF.co Web API"""
# Prepare requests params as JSON
# See documentation: https://docs.pdf.co
parameters = {}
parameters["html"] ="<div><img src=\" [[ barcode:QRCode {{variable1}}]]\" /></div> "
parameters["templateData"] = "{\"variable1\": \"12345\"}"
parameters["name"] = "result.pdf"
parameters["async"] = Async
parameters["footer"]="<span
style='width:100%;text-align:right;float:right'><spanstyle='font-size:10px;'>My Document</span>.</span>"
parameters["footer"]= "<div style='width:100%;text-align:right'><span
style='font-size:10px;margin-right:20px'>Page <spanclass='pageNumber'></span> of <span class='totalPages'></span>.</span></div>"
# Prepare URL for 'Convert from HTML' API request
url = "{}/pdf/convert/from/html".format(BASE_URL)
# Execute request and get response as JSON
response = requests.post(url, data=parameters, headers={ "x-api-key":API_KEY })
if (response.status_code == 200):
json = response.json()
print(json)
else:
print(f"Request error: {response.status_code} {response.reason}")
if (__name__ == '__main__'):
main()Output
Below is the screenshot to demonstrate the above code’s output:

The API added the current date at the top in the absence of any predefined header.
Additional Customization
Users can leverage specific in-built classes provided by the PDF conversion API to dynamically inject custom values into fields within their PDF documents. Here's a breakdown of these classes and their functionalities:
- date: This class is used to insert the current date into the PDF.
- title: This class allows the document's title to be printed within the HTML content of the PDF.
- url: This class is designed to print the output URL or the location of the document.
- pageNumber: This class inserts the current page number of the PDF.
- totalPages: Similarly, this class prints the total number of pages in the PDF file.
Combined Source Code
Below is the source code containing the advanced version of both header and footer. This code generates the PDF file with the QR code, header, and footer. The footer section uses the built-in “pageNumber” and “totalPages” classes to print “page ‘k’ of ‘kk’ pages,” such as page 2 of 4. Similarly, the header section uses more CSS styles to customize the above subheaders.
Feel free to comment or uncomment the code lines below to add the date, URL, or page number of the PDF file.
import os
import requests # pip install requests
# The authentication key (API Key).
# Get your own by registering at https://app.pdf.co
API_KEY = "**************************************"
# Base URL for PDF.co Web API requests
BASE_URL = "https://api.pdf.co/v1"
# Runs processing asynchronously. Returns Use JobId that the user may use with /job/check to check the state of the processing (possible states: working, failed, aborted, and success). Must be one of: true,false.
Async = "False"
def main(args = None):
convertFromHTML()
def convertFromHTML():
"""Converts HTML template to PDF using PDF.co Web API"""
# Prepare requests params as JSON
# See documentation: https://docs.pdf.co
parameters = {}
parameters["html"] ="<div><img src=\" [[ barcode:QRCode {{variable1}}]]\" /></div> "
parameters["templateData"] = "{\"variable1\": \"12345\"}"
parameters["name"] = "result.pdf"
parameters["async"] = Async
parameters["header"]="<span style='width:100%'><span style='font-size:10px;'>My Document</span>.</span>"
# parameters["header"]= "<div style='width:100%;'><span style='font-size:10px;margin-left:20px;width:50%;float:left;color:red'>LEFT SUBHEADER</span>
<span style='font-size:8px;width:30%;float:right'>RIGHT SUBHEADER</span></div>",
# parameters["header"]="<span style='width:100%'><span style='font-size:10px;' class='url'></span>.</span>"
parameters["footer"]= "<div style='width:100%;text-align:right'><span style='font-size:10px;margin-right:20px'>Page</span>
<span class='pageNumber'></span>
<span class='totalPages'></span>.</span></div>"
# Prepare URL for 'Convert from HTML' API request
url = "{}/pdf/convert/from/html".format(BASE_URL)
# Execute request and get response as JSON
response = requests.post(url, data=parameters, headers={ "x-api-key":API_KEY })
if (response.status_code == 200):
json = response.json()
print(json)
else:
print(f"Request error: {response.status_code} {response.reason}")
if (__name__ == '__main__'):
main()Related Tutorials
