How to Extract Text from Scanned PDF using Make
3 Minutes Read
We prepared this step-by-step tutorial with screenshots to teach you how to extract text from scanned PDF using Make.

Start by going to the Make Scenarios Interface. Click Create a New Scenario.
Step 1: Create a Google Drive module
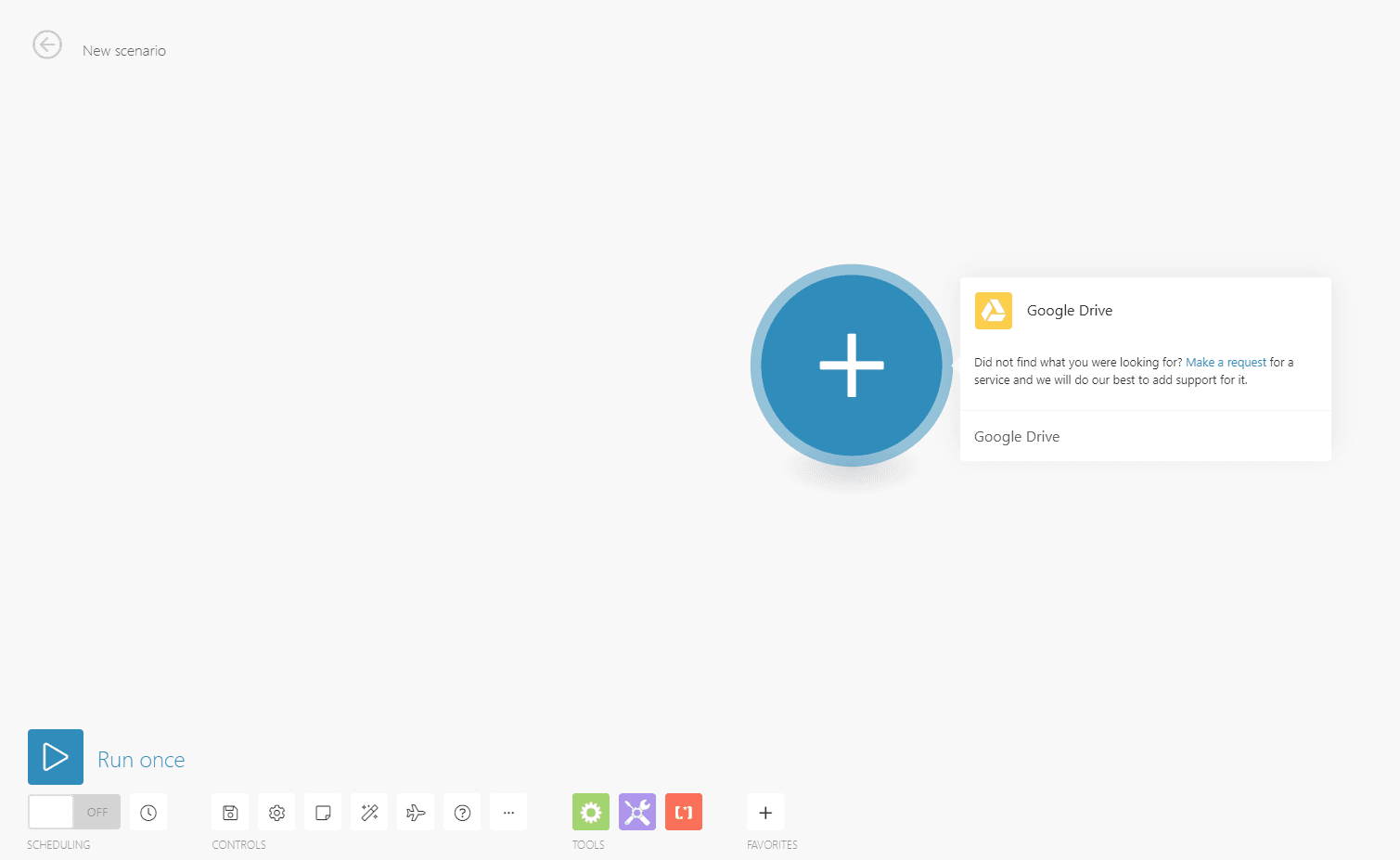
Step 2: Choose Download a file
NOTE: For this tutorial, we’re using Google Drive as our cloud storage. You may use other cloud storage that has a similar option as this.
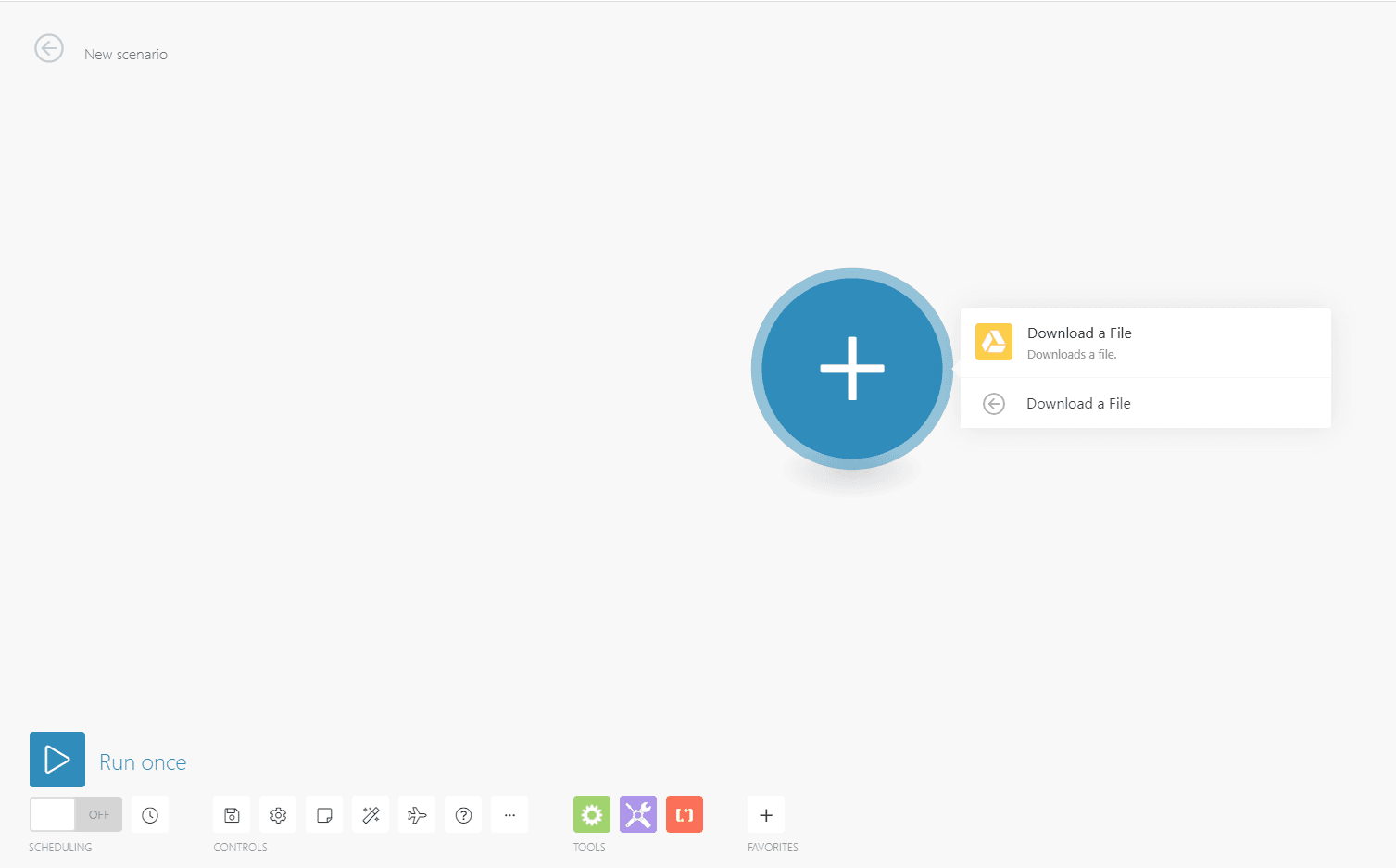
Step 3: Set up the Google Drive module
- Select a connection for Google Drive
- For Enter a File ID combo box you can choose either Select from the list or Enter manually
- Choose My Drive as the drive to be used
- Select the folder and the file that you’re going to use

Step 4: Create a new module for PDF.co
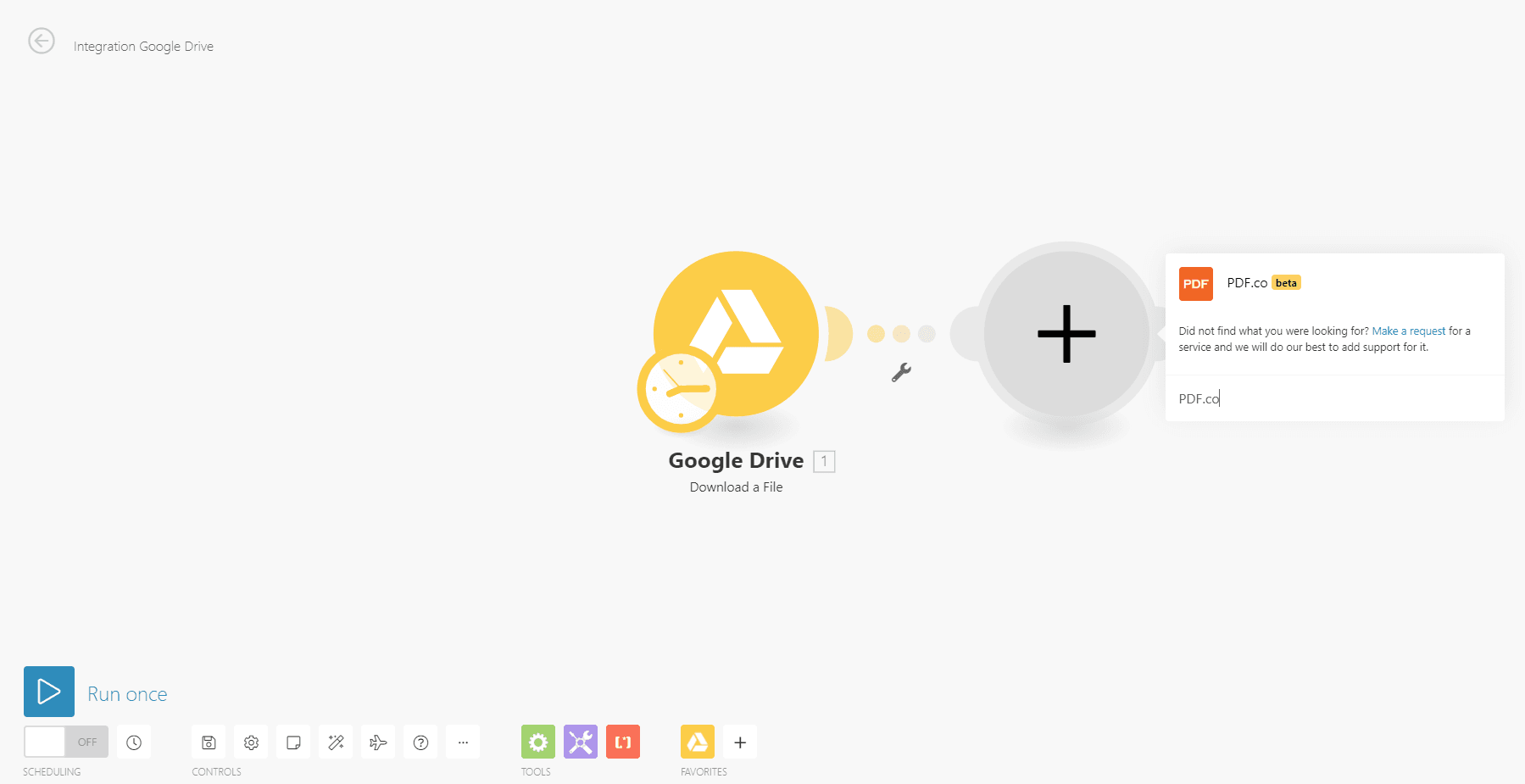
Step 5: Choose Convert from PDF
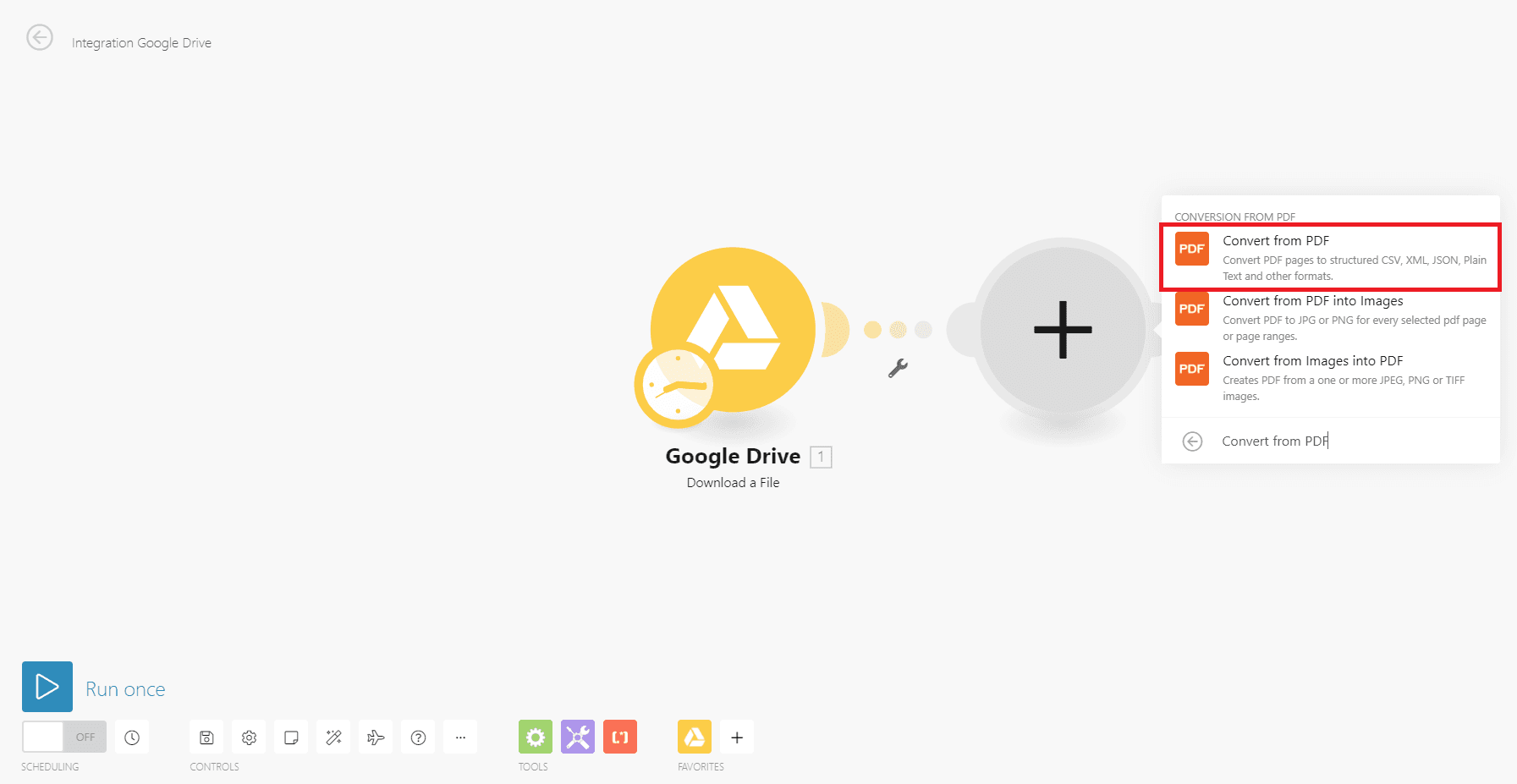
Step 6: Setup the PDF.co module
- Select a connection for PDF.co
- For Input File combo box you can either choose Upload a File or Input a File from URL
- For the Source file, you can choose either Google Drive – Download a file or Map manually
- For Convert Options choose PDF to CSV
- For the Pages, you can leave it blank if you want all of the pages to be extracted
- Set Inline to true if you want the extracted data to be displayed automatically, set it into false if you want to get a downloadable file

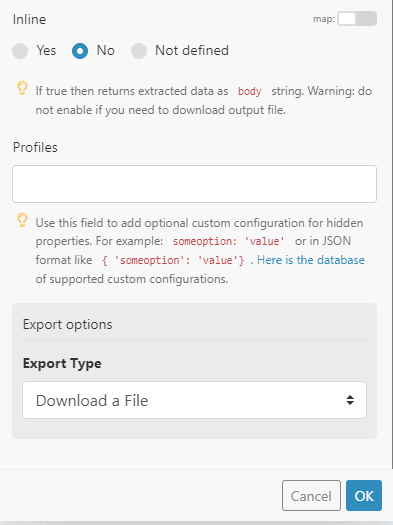
Step 7: Run Scenario
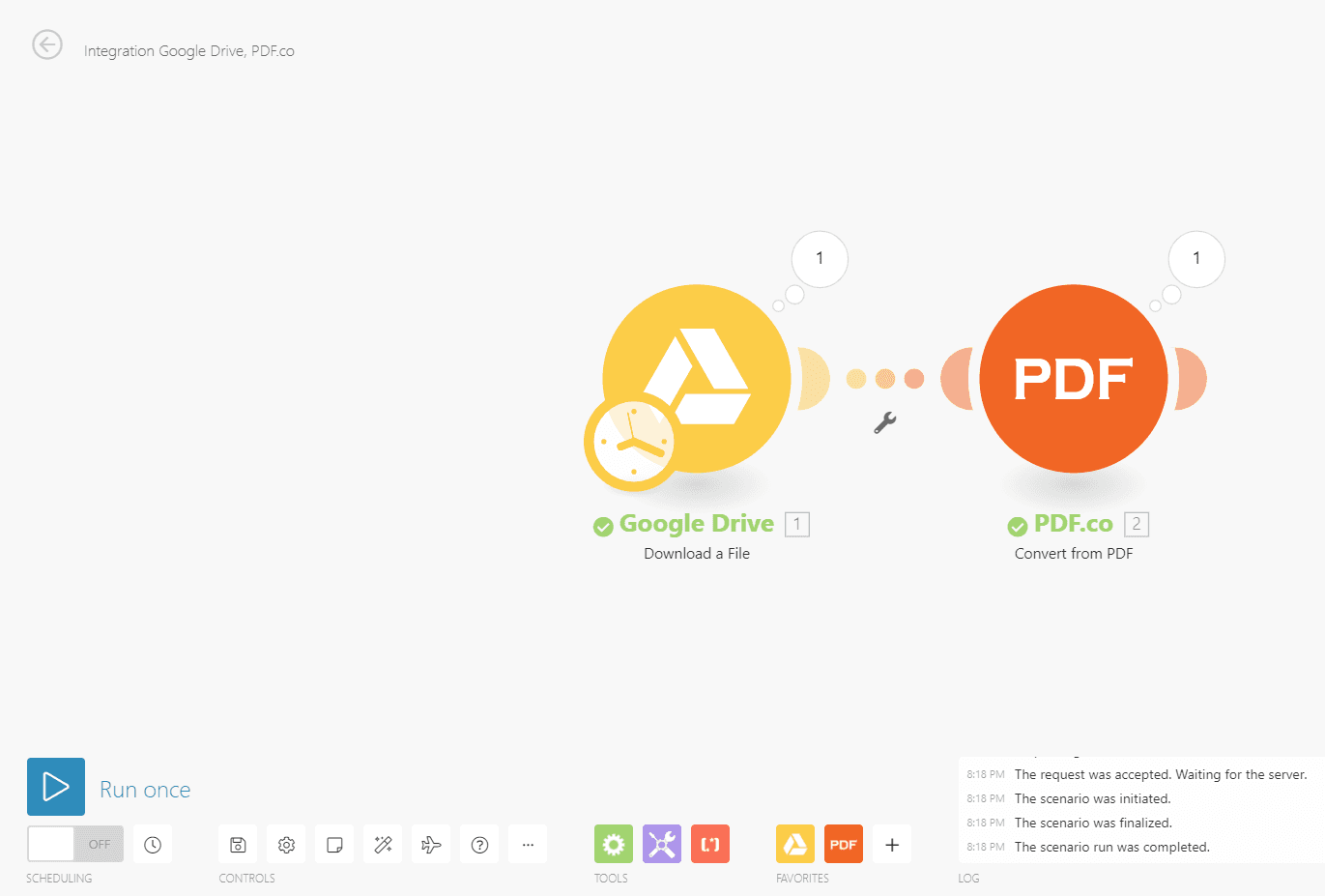
Step 8: Get the output link
If there are no errors, you can now check your output link
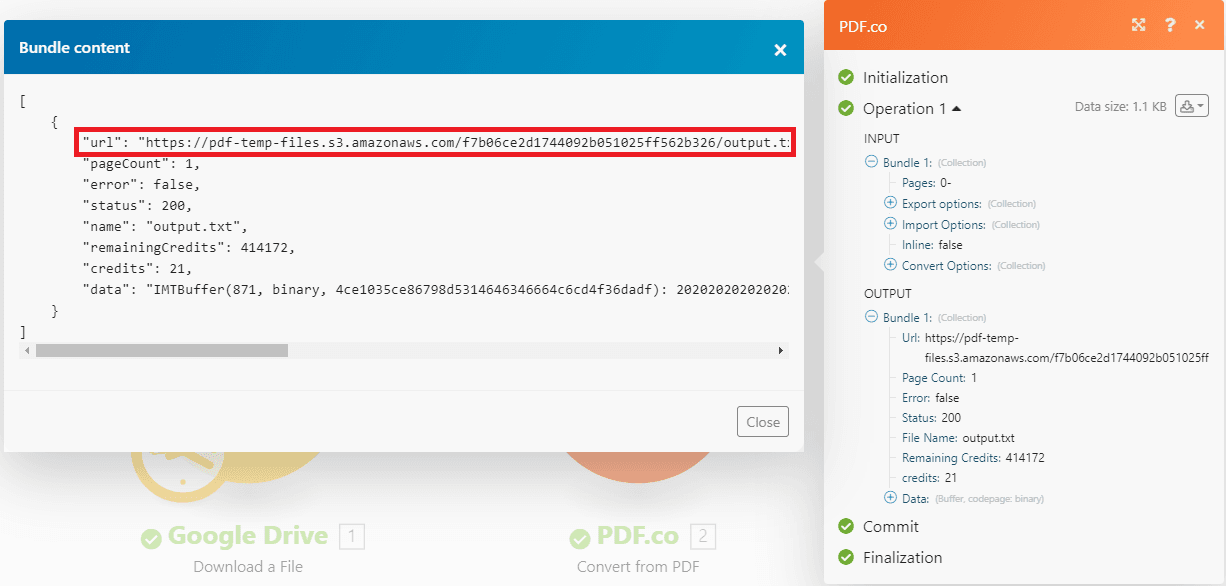
Step 9: Extracted text output

In this tutorial, you’ve learned how to extract text from scanned PDFs using Make.
Video Guide
Related Tutorials
