How to Extract Tables Containing Text from PDF using PDF.co and Zapier
IN THIS TUTORIAL
Extract Tables with Text from PDF
In this tutorial, we will show you how to extract tables containing text from PDF using PDF.co and Zapier.
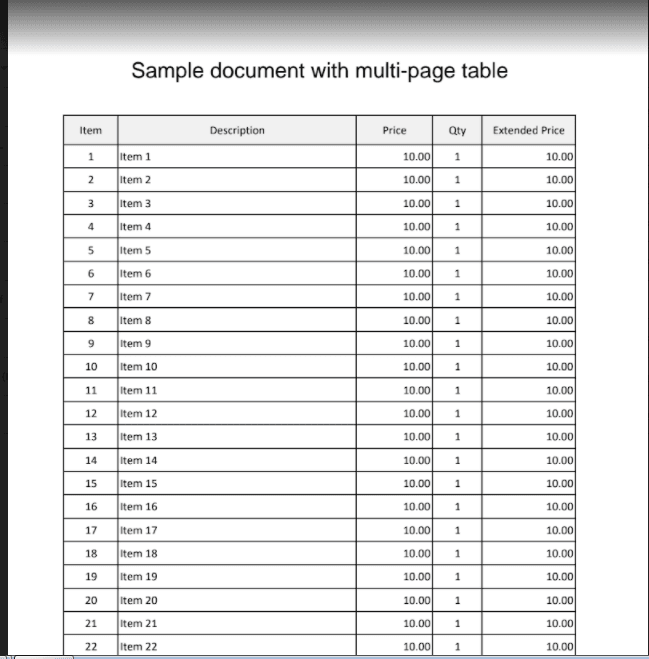
We will use this 2-page sample PDF and extract the table items that span two pages.
Make A Zap
First, click on the Make a Zap button in the upper left corner of your dashboard.
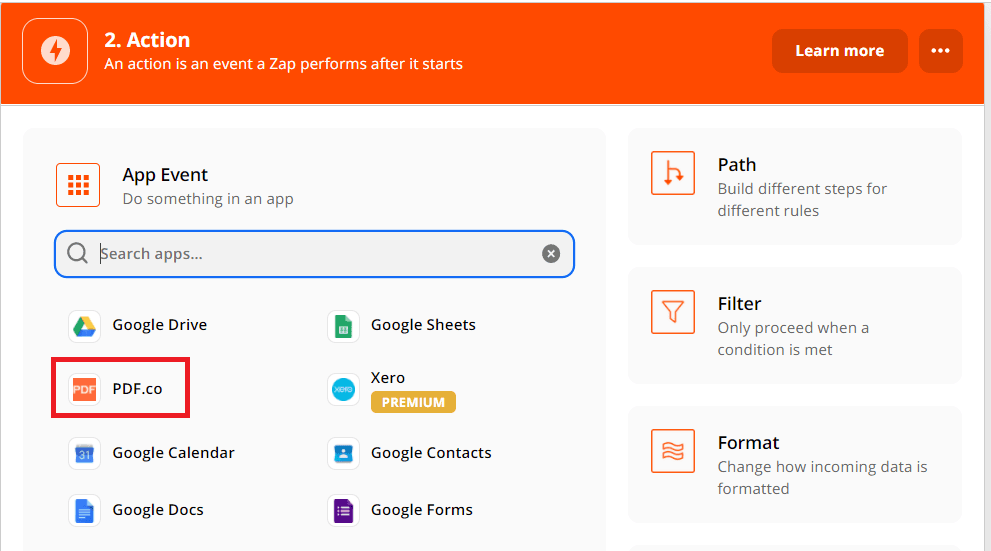
Add App Event
Now, select PDF.co as the App Event.
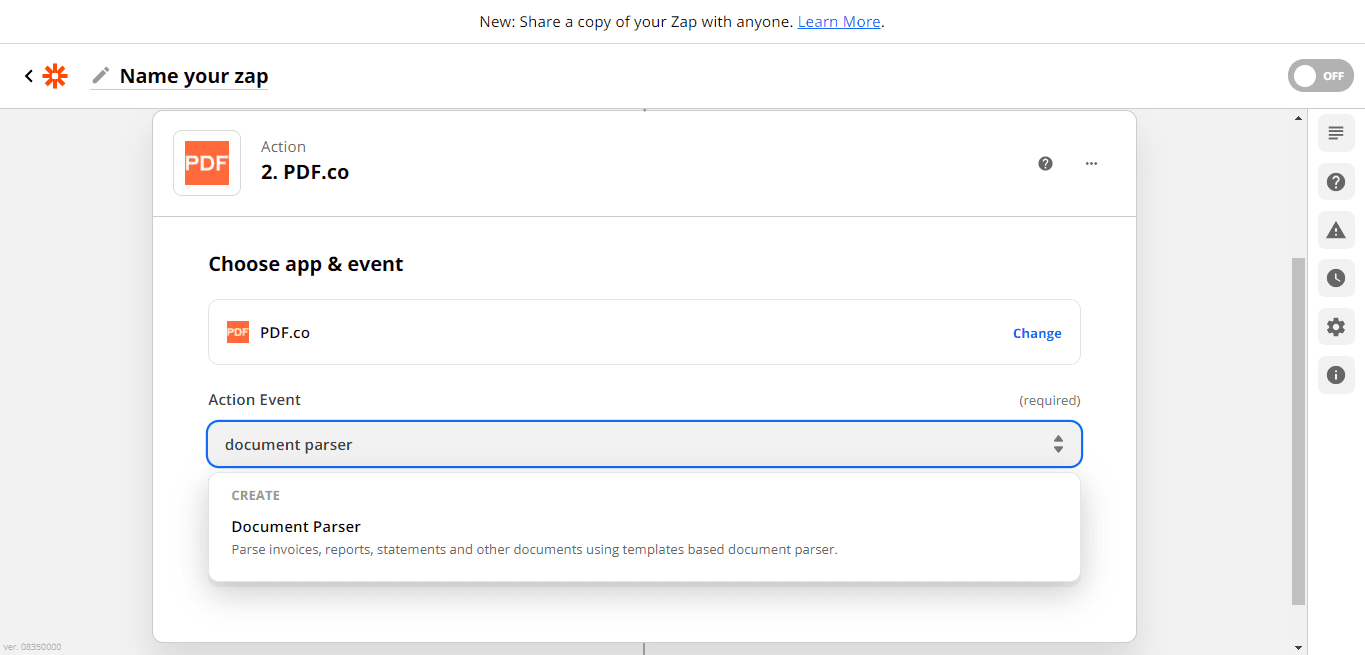
Add Action Event
Under the Action Event, select the Document Parser to parse invoices and other documents using templates.
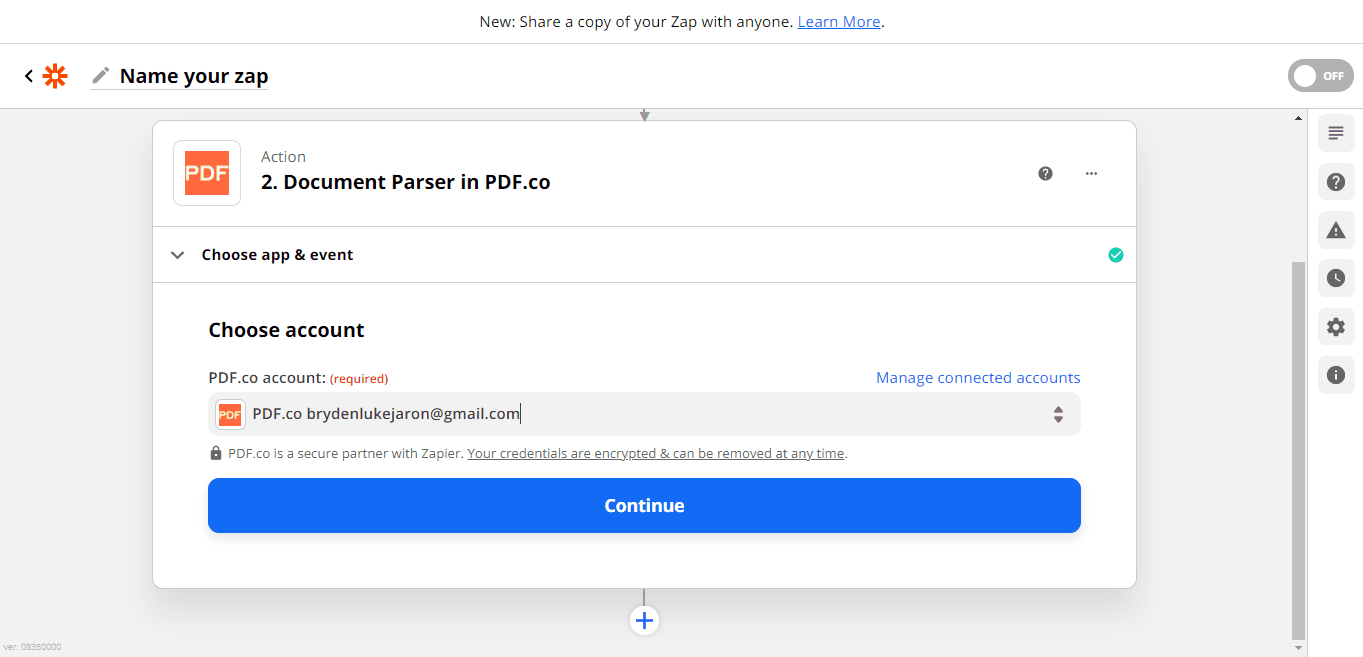
Connect PDF.co Account
In the Choose Account field, select your PDF.co account.
Document Parser Configuration
Now, we can set up the action.
- In the Input field, enter the source file link. If you use Google Drive, Dropbox, or another service, set the file-sharing setting to Anyone with a link so the engine can access the file.
- Under the Template ID field, type in the ID of the document parser template.
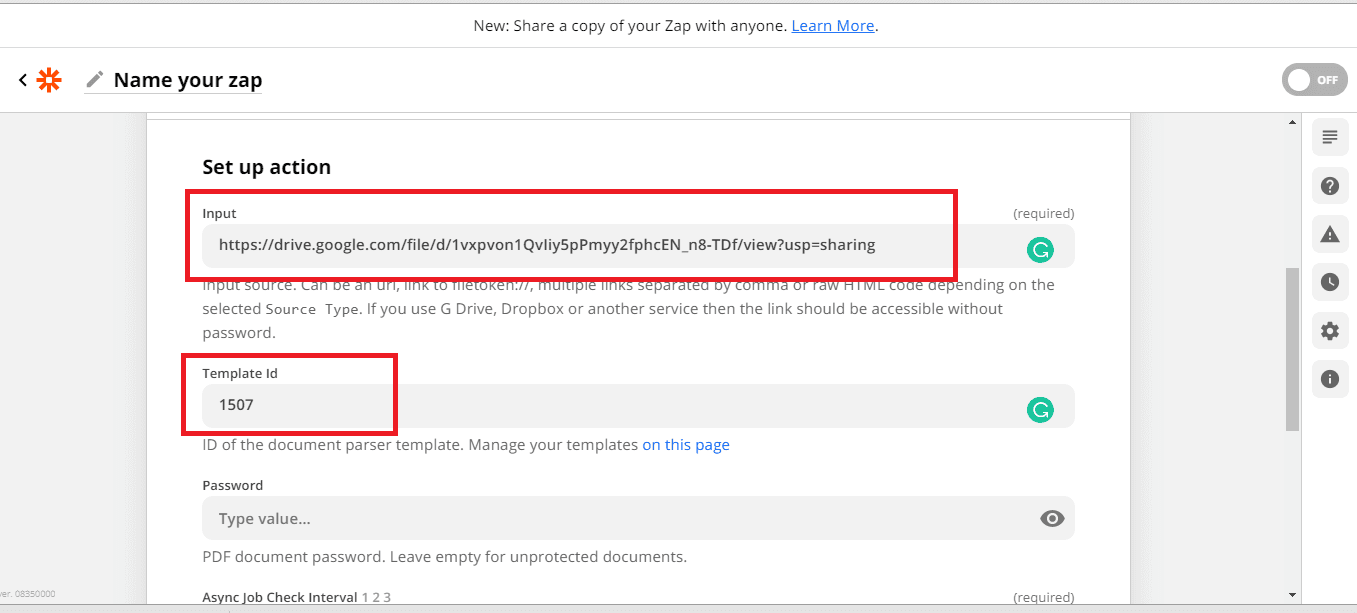
Test Document Parser
Let’s send our Document Parser configuration to PDF.co to Test & Review. This is to make sure that we set it up correctly.
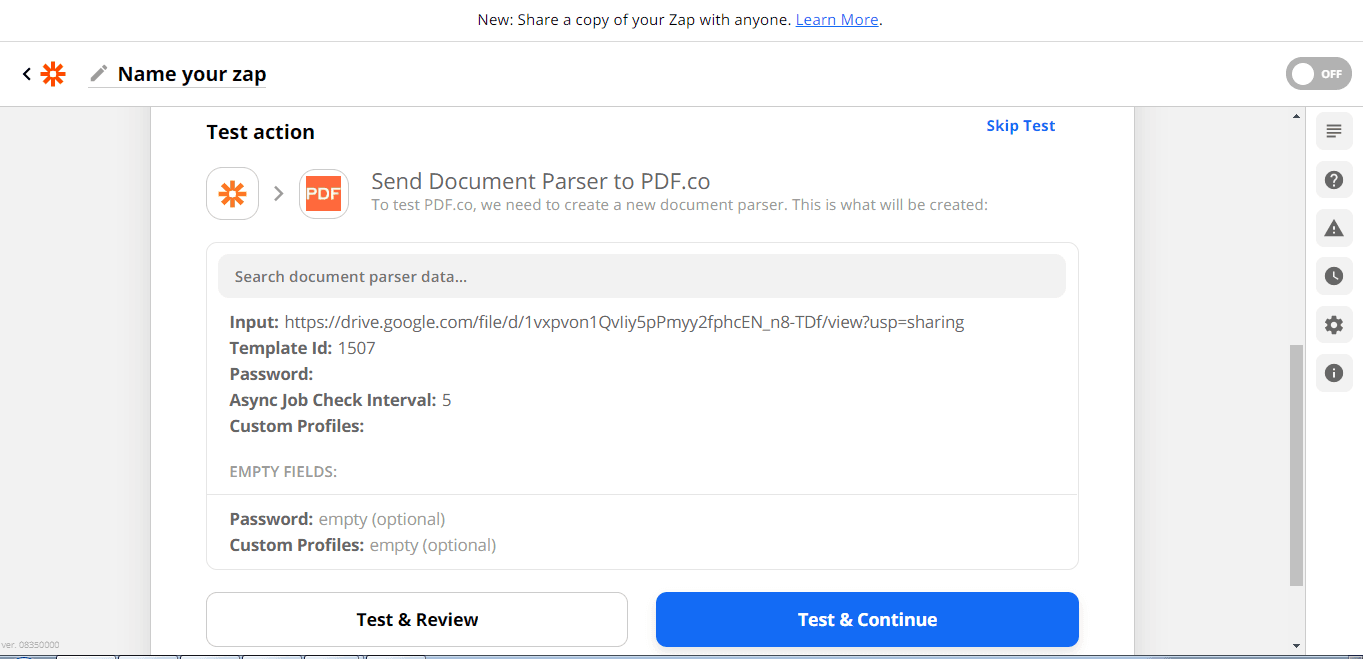
Test Result
Great! The test was successful. In the inline result, you will see all the table line items from 1 to 45. You can then turn the Zap on.
Create Document Parser Template
We will show you how to create the template to extract a multi-page table.
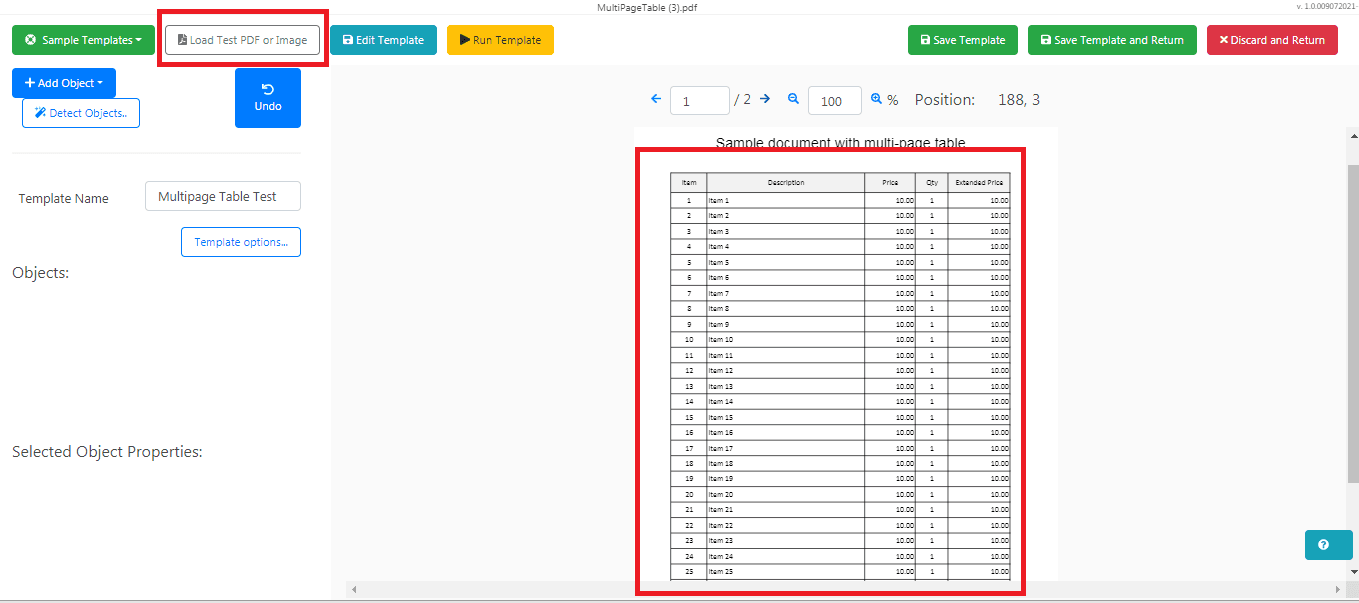
Load Test PDF
Click the Load Test PDF or Image button to open the PDF document that you will use for your template.
Name and Regex
You can rename the object in the Name field. Make sure to check the Regex box when using any Text Search objects.
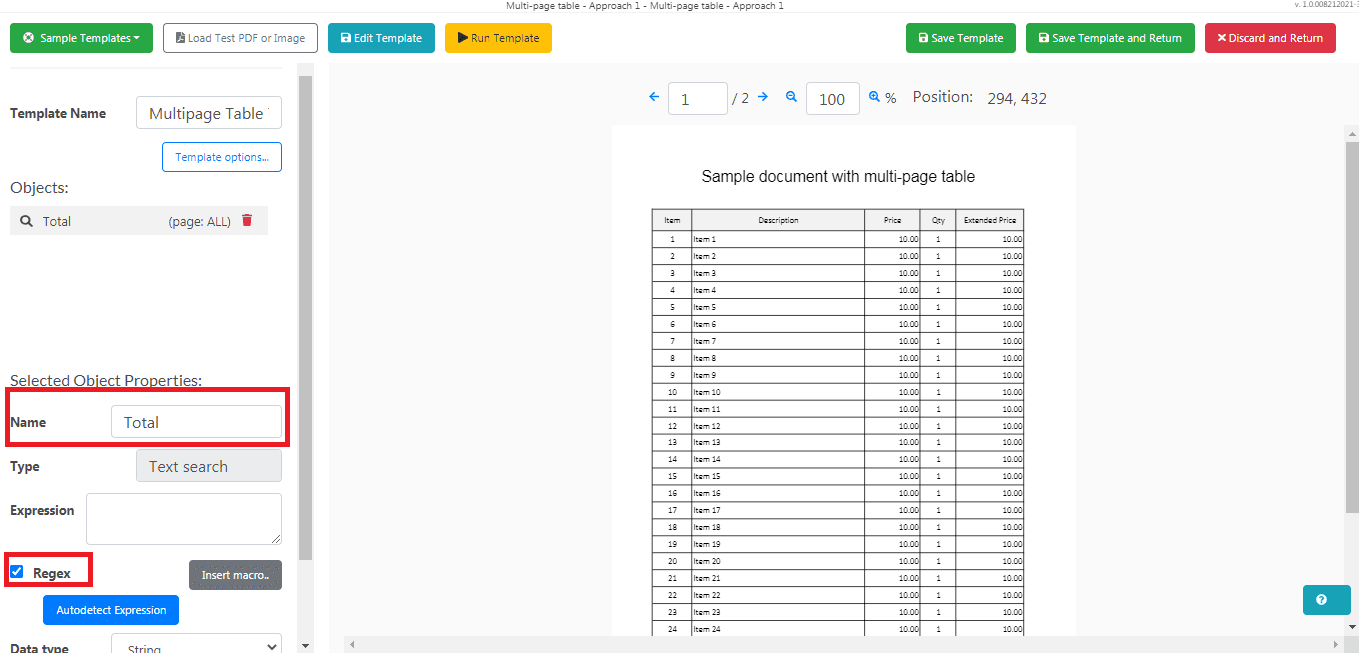
Add TABLE Field Based on TEXT SEARCH
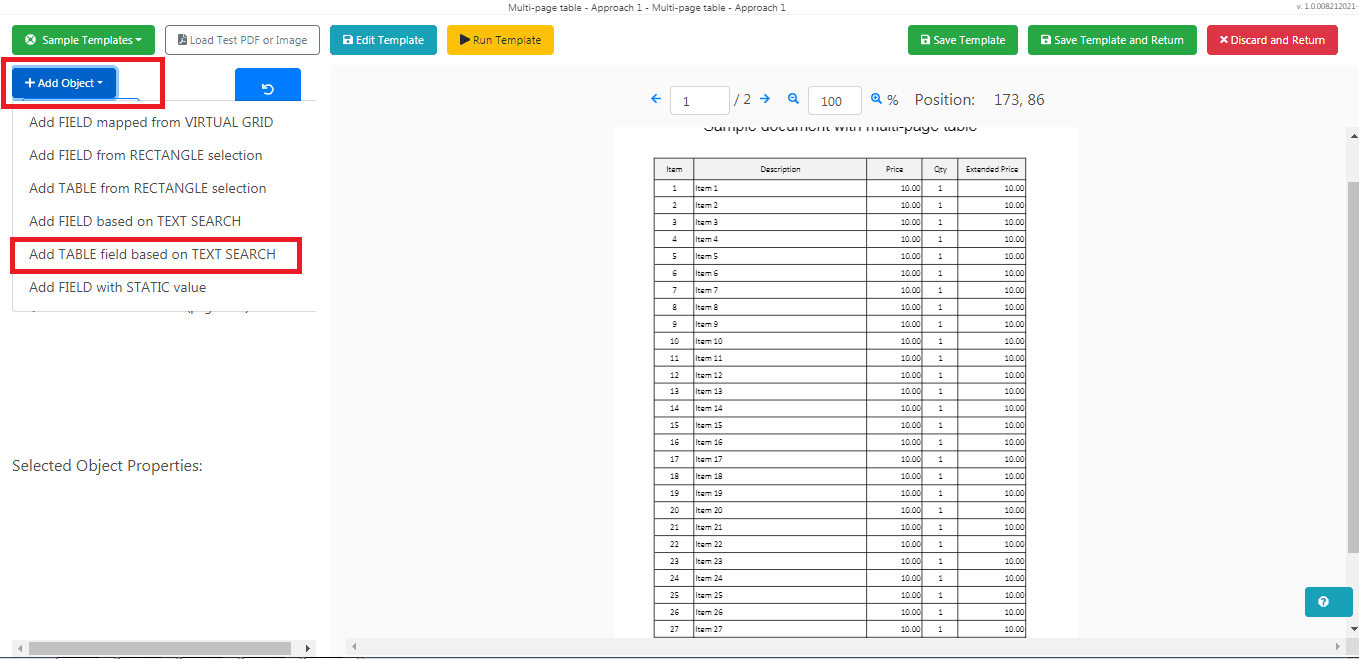
Now, click on the Add Object button and select the Add TABLE Field based on TEXT SEARCH.
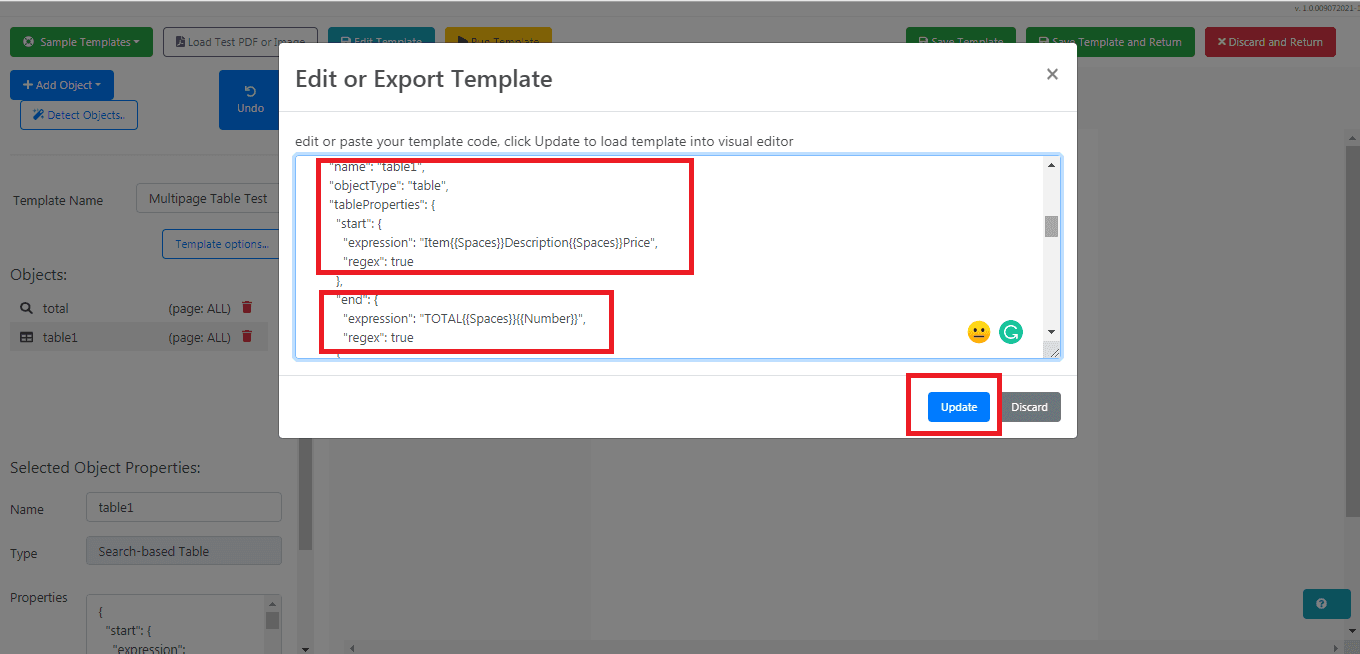
Add Table Object Expression
In the Edit Template window, add the start and end expressions as well as necessary rows and columns. Then, set the multipage to true.
{
"start": {
"expression": "Item{{Spaces}}Description{{Spaces}}Price",
"regex": true
},
"end": {
"expression": "TOTAL{{Spaces}}{{Number}}",
"regex": true
},
"row": {
"expression": "{{LineStart}}{{Spaces}}(?{{Digits}}){{Spaces}}(?{{SentenceWithSingleSpaces}}){{Spaces}}(?{{Number}}){{Spaces}}(?{{Digits}}){{Spaces}}(?{{Number}})",
"regex": true
},
"columns": [
{
"name": "itemNo",
"dataType": "integer"
},
{
"name": "description",
"dataType": "string"
},
{
"name": "price",
"dataType": "decimal"
},
{
"name": "qty",
"dataType": "integer"
},
{
"name": "extPrice",
"dataType": "decimal"
}
],
"multipage": true
}Then Run the template to make sure there are no errors.
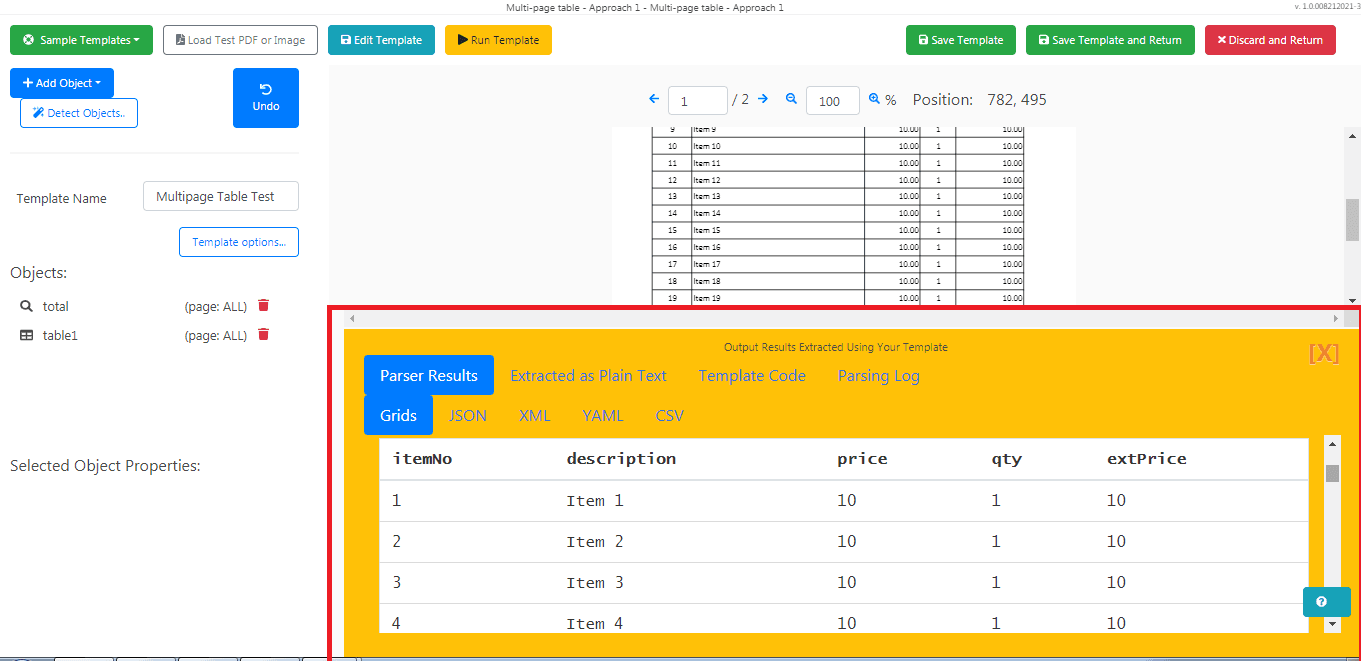
Parsed Table Output
Here’s the parsed table line items output.
In this tutorial, you learned how to extract tables containing text from PDF using PDF.co and Zapier. You also learned how to create a Document Parser template.
Video Guide
Related Tutorials
