Asynchronous Data Extraction from PDF Columns using Java
This tutorial and sample source code demonstrate asynchronous data extraction from specific columns in a PDF document using PDF.co's PDF to CSV functionality. The code, written in Java, leverages the PDF.co Web API for converting PDF content to CSV based on specific layouts, tables, rows, and columns.
With asynchronous processing, larger files and complex tasks can run in the background, allowing you to track job progress without facing potential timeouts. For more details on asynchronous processing, refer to the PDF.co documentation.
Additionally, the PDF.co editor provides precise coordinates to simplify identifying specific sections for extraction, even in scanned documents.
Features of PDF to CSV API Endpoint
The PDF.co Web API provides tools and functionalities to convert any PDF document or scanned image to CSV. This process preserves the formatting, the text, the vectors, and the images efficiently after the conversion. The API uses the method of automatic document classification of incoming documents. The users can utilize the document classifier endpoint to automatically sort and detect the document’s class on their keywords-based rules.
Another reason to use the PDF.co Web API for sensitive information is they provide a highly secure platform for its consumers. The platform transmits user data via encrypted connections to ensure security. The users can go through the security protocols in detail here.
Endpoint Parameters
Following are the PDF to CSV endpoint parameters:
- url: It is a required parameter that provides the URL to the source file. The PDF.co platform supports any publicly accessible URL, including those from Dropbox, Google Drive, and the built-in file storage of PDF.co.
- httpusername: It is an optional parameter that provides an HTTP auth user name to access the source URL if required.
- httppassword: It is an optional parameter that provides an HTTP auth password to access the source URL if needed.
- pages: It is an optional parameter and must be a string. The parameter provides a comma-separated list of the pages required. The users can set a page range by using “ -.” Moreover, the users can leave the parameter empty to indicate selecting all the pages.
- unwrap: It is an optional parameter that helps unwrap the lines and forms them into a single line in the table cells. It is done by enabling lineGrouping.
- rect: It is an optional parameter and must be a string. It provides the specific data coordinates for extraction.
- lang: It is an optional parameter that helps set the language for OCR to use for scanned JPG, PNG, and PDF document inputs to extract text from them.
- inline: It is an optional parameter. The users can set it to true to return data as inline or false to return the link to an output file.
- lineGrouping: It is an optional parameter and must be a string. It enables grouping within the table cells.
- name: It is an optional parameter and must be a string. It provides the name of the generated output file after successful code execution.
- expiration: It is an optional parameter that offers the expiration time for the output link.
- async: Setting
"async": trueenables background processing, allowing large or complex conversions to complete without blocking the initial request. - profiles: It is an optional parameter and must be a string. This parameter helps in setting additional configurations and extra options
Extract Data from PDF Column – Example in Java
The following source code demonstrates how to extract data from any PDF document and save it as a CSV file, focusing on specific columns, using the PDF to CSV API endpoint. This example involves taking a sample PDF file for classification and leveraging the PDF.co editor to locate the document coordinates. Once the coordinates of the required columns are identified, the code extracts the relevant data into a CSV format. The resulting CSV file is then returned to the user after completing the extraction process.
For scenarios where the source file is uploaded from local storage, you can refer to the sample code here. This example provides detailed guidance on how to handle local file uploads while working with the PDF to CSV API endpoint.
Sample Code: PDF to CSV from URL
Source File for PDF Data Extraction in Java
Following is the source PDF file:
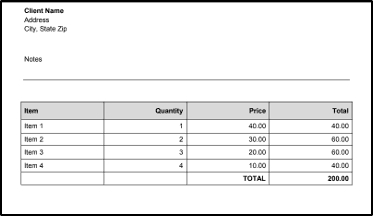
Output File in CSV Format
Following is the generated output file in CSV:
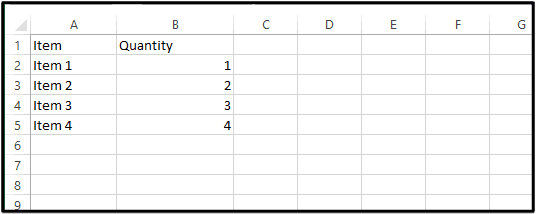
Step-by-Step Guide To Extract Data from PDF to CSV Asynchronously
Importing Necessary Libraries and Setting Up the Environment
You can use the IDE of your choice, whether it's VS Code, IntelliJ, or another environment that you're comfortable with.
The code imports the required packages and libraries to make the API request and reads the file from the URL.These libraries are instrumental in facilitating interaction with the PDF.co API and managing downloaded files effectively.
Defining Constants and Initializing Variables
Several key variables are initialized:
- API_KEY: This is your unique PDF.co API Key, which is required to authenticate API calls. You can get your API key by logging into your PDF.co account and copying it from your dashboard. Once you have the key, paste it into the code where it says
API_KEY. - SourceFileUrl: Here, you can input the URL of the source PDF file that you wish to convert to CSV. Make sure the URL points to a valid PDF file that is publicly accessible.
- Pages, Password, and DestinationFile: Specify details like pages to extract, password (if any), and the local path where the CSV file will be saved.
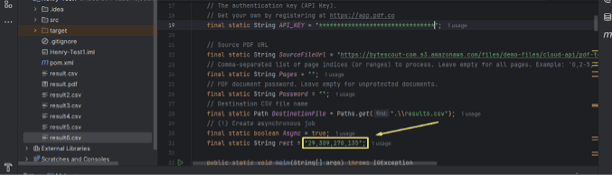
- rect: The rectangular region in the PDF containing the data to extract, provided as coordinates.
Creating the JSON Payload for the Request
After this, the user has to provide API’s body payload, which in this sample code is the destination and source file URL, file password, file pages, column layout, the rect parameter and the “async” flag set to true.
The users can provide their own required information here and customize the code. The code utilizes the PDF.co sample code containing the source file.
Sending the API Request to Convert PDF to CSV
The code sends a POST request to PDF.co’s “PDF to CSV” endpoint using the assembled JSON payload. Upon a successful response, the API returns a jobId (for tracking) and an initial status.
Extract Data Coordinates from PDF Document
The “rect” parameter contains the data coordinates that must be extracted from the PDF document. The users can get these coordinates using the PDF.co editor, which provides all the document coordinates. To achieve this, upload your file and draw the rectangle over the area to be extracted then the coordinates will be generated.
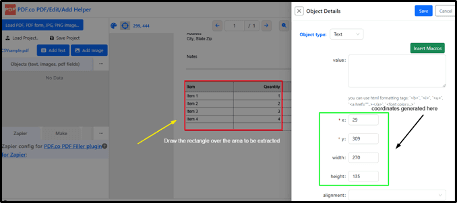
Insert the generated coordinates into the code as shown below.
Polling the Job Status Asynchronously
- The code enters a loop where it periodically checks the job’s status using the jobId.
- Every 3 seconds, a request is sent to the job status endpoint, which returns the current status (e.g., “
working”, “success”, or “error”). - This polling mechanism allows other processes to continue running while waiting for the conversion to complete, a key advantage of asynchronous processing.
- Once the job status is “success,” the resultFileUrl (URL of the converted CSV) is retrieved.
Downloading the CSV File
The successful request returns the CSV formatted data that the file stream reads and stores on the local storage as the result.csv file, i.e., the destination file.
This asynchronous approach allows you to extract data from large PDFs efficiently, avoiding potential timeouts and tracking job progress. The provided code demonstrates how to set up and customize an API request to convert PDF data to CSV based on specific coordinates, making data extraction from PDFs seamless and reliable.
Using these steps, users can easily customize the code to match their requirements and extract targeted data from PDFs to CSV files.
Related Tutorials
