How to Extract Borderless Tables from PDF to CSV in Java Using Asynchronous Processing
This tutorial and the sample source code demonstrate asynchronous data extraction from a PDF document, including extracting borderless tables from a PDF to CSV using the Document Parser functionality of PDF.co Web API. By using asynchronous processing, the application avoids timeouts and continues other operations while waiting for the conversion to finish. This approach is especially useful for large PDFs or lengthy conversions, ensuring a smooth and efficient workflow.
The provided source code illustrates how to convert a PDF table to CSV in Java while leveraging asynchronous processing. Additionally, users can parse JPG and PNG documents to extract tables, barcodes, values, and fields from orders, invoices, statements, and other PDF documents.
IN THIS TUTORIAL
Features of Document Parser API Endpoint
The PDF.co Web API offers tools to convert PDF documents or scanned images into formats such as CSV, XML, and JSON. The API uses automatic classification techniques to handle incoming documents effectively. Users can take advantage of the document classifier endpoint to automatically detect the document type based on custom rules or AI-based classification.
Key features include:
- Custom Templates: Use predefined or custom templates to extract data fields such as invoice IDs, dates, taxes, and totals from invoices in English.
- Secure Processing: PDF.co ensures secure handling of sensitive user data through encrypted connections. For more details on security protocols, visit the PDF.co documentation.
- Flexible Formats: Extract data into structured formats like CSV, which are ideal for further processing and analysis.
Benefits of Asynchronous Processing for PDF to CSV Conversion
By using asynchronous processing, applications can:
- Avoid Timeouts: For large or complex PDFs, asynchronous processing ensures the operation completes without hitting server or client time limits.
- Optimize Performance: While waiting for the conversion, the application can continue handling other tasks, improving overall efficiency.
- Reliability: Asynchronous processing minimizes the risks of interruptions during lengthy conversions, resulting in a smoother workflow.
This setup ensures an efficient and seamless PDF-to-CSV conversion process. For more details on asynchronous processing, refer to the PDF.co documentation.
Endpoint Parameters to Extract PDF Table to CSV in Java
Following are the Document Parser API endpoint parameters for converting the PDF to CSV:
- url: It is a required parameter that provides the URL to the source file. The PDF.co platform supports any publicly accessible URL, including those from Dropbox, Google Drive, and the built-in file storage of PDF.co.
- httpusername: It is an optional parameter and provides an HTTP auth user name to access the source URL if required.
- httppassword: It is an optional parameter and provides an HTTP auth password to access the source URL if needed.
- templateId: It is a required parameter that sets the Id of a document parser temple the user uses.
- template: It is an optional parameter. The users can provide the document parser template code using this parameter directly.
- inline: It is an optional parameter. The users can set it to true to return data as inline or false to return the link to an output file.
- outputFormat: It is an optional parameter. The user can set this parameter to generate the output in any required format, including CSV, XML, or JSON.
- password: It is an optional parameter that must be a string. It provides the password for the PDF file if required.
- async: Setting
"async": trueenables background processing, allowing large or complex conversions to complete without blocking the initial request. - name: It is an optional parameter and must be a string. It provides the name of the generated output file after successful code execution.
- expiration: It is an optional parameter that offers the expiration time for the output link.
- profiles: It is an optional parameter and must be a string. This parameter helps in setting additional configurations and extra options
Extracting Borderless Table Using Template ID
Below is the sample code to detect and extract data from a borderless table in a PDF. In this case, the user has created and saved a custom template using the Document Parser Tool in their PDF.co account. The Template ID, which is copied from the Choose Extraction Template Page (available here), is then used in the code to specify the extraction settings.
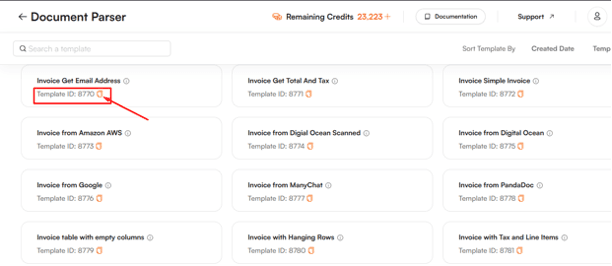
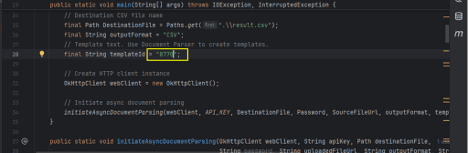
This approach allows you to leverage a custom template for more accurate and tailored data extraction from the PDF, particularly when dealing with complex structures like borderless tables.
Sample Code to Convert PDF Form to CSV
import com.google.gson.JsonObject;
import com.google.gson.JsonParser;
import com.google.gson.JsonPrimitive;
import okhttp3.*;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
public class Main {
// Get your own API Key by registering at https://app.pdf.co
final static String API_KEY = "*************";
public static void main(String[] args) throws IOException, InterruptedException {
// Source PDF file
final String SourceFileUrl = "https://pdfco-test-files.s3.us-west-2.amazonaws.com/document-parser/sample-invoice.pdf";
// PDF document password. Leave empty for unprotected documents.
final String Password = "";
// Destination CSV file name
final Path DestinationFile = Paths.get(".\\result.csv");
final String outputFormat = "CSV";
// Template text. Use Document Parser to create templates.
final String templateId = "1";
// Create HTTP client instance
OkHttpClient webClient = new OkHttpClient();
// Initiate async document parsing
initiateAsyncDocumentParsing(webClient, API_KEY, DestinationFile, Password, SourceFileUrl, outputFormat, templateId);
}
public static void initiateAsyncDocumentParsing(OkHttpClient webClient, String apiKey, Path destinationFile,
String password, String uploadedFileUrl, String outputFormat, String templateId) throws IOException, InterruptedException {
// Prepare POST request body in JSON format
JsonObject jsonBody = new JsonObject();
jsonBody.add("url", new JsonPrimitive(uploadedFileUrl));
jsonBody.add("outputFormat", new JsonPrimitive(outputFormat));
jsonBody.add("templateId", new JsonPrimitive(templateId));
jsonBody.add("async", new JsonPrimitive(true)); // Enable async mode
RequestBody body = RequestBody.create(MediaType.parse("application/json"), jsonBody.toString());
// Prepare request to `Document Parser` API
Request request = new Request.Builder()
.url("https://api.pdf.co/v1/pdf/documentparser")
.addHeader("x-api-key", apiKey) // (!) Set API Key
.addHeader("Content-Type", "application/json")
.post(body)
.build();
// Execute request
Response response = webClient.newCall(request).execute();
if (response.code() == 200) {
// Parse JSON response
JsonObject json = JsonParser.parseString(response.body().string()).getAsJsonObject();
boolean error = json.get("error").getAsBoolean();
if (!error) {
// Asynchronous job ID
String jobId = json.get("jobId").getAsString();
System.out.println("Job#" + jobId + ": has been created.");
// Poll job status
pollJobStatus(webClient, apiKey, jobId, destinationFile);
} else {
// Display service reported error
System.out.println(json.get("message").getAsString());
}
} else {
// Display request error
System.out.println(response.code() + " " + response.message());
}
}
private static void pollJobStatus(OkHttpClient webClient, String apiKey, String jobId, Path destinationFile) throws IOException, InterruptedException {
DateTimeFormatter dtf = DateTimeFormatter.ofPattern("MM/dd/yyyy HH:mm:ss");
String jobStatusUrl = "https://api.pdf.co/v1/job/check?jobid=" + jobId;
while (true) {
// Prepare request to check job status
Request request = new Request.Builder()
.url(jobStatusUrl)
.addHeader("x-api-key", apiKey) // (!) Set API Key
.build();
// Execute request
Response response = webClient.newCall(request).execute();
if (response.code() == 200) {
// Parse JSON response
JsonObject json = JsonParser.parseString(response.body().string()).getAsJsonObject();
String status = json.get("status").getAsString();
System.out.println("Job#" + jobId + ": " + status + " - " + dtf.format(LocalDateTime.now()));
if (status.equalsIgnoreCase("success")) {
// Get result file URL
String resultFileUrl = json.get("url").getAsString();
downloadFile(webClient, resultFileUrl, destinationFile.toFile());
System.out.printf("Generated file saved to \"%s\" file.%n", destinationFile.toString());
break;
} else if (status.equalsIgnoreCase("failed") || status.equalsIgnoreCase("aborted")) {
System.out.println("Job failed with status: " + status);
break;
}
// Wait for a few seconds before checking again
Thread.sleep(3000);
} else {
// Display request error
System.out.println(response.code() + " " + response.message());
break;
}
}
}
public static void downloadFile(OkHttpClient webClient, String url, File destinationFile) throws IOException {
// Prepare request
Request request = new Request.Builder()
.url(url)
.build();
// Execute request
Response response = webClient.newCall(request).execute();
byte[] fileBytes = response.body().bytes();
// Save downloaded bytes to file
OutputStream output = new FileOutputStream(destinationFile);
output.write(fileBytes);
output.flush();
output.close();
response.close();
}
}Step-by-Step Guide to Extract PDF Form Data to CSV Using Document Parser in Asynchronous Mode
This guide explains how to extract borderless tables from a PDF and convert them into a CSV file using the PDF.co Document Parser API with asynchronous processing.
Steps Overview
Import Required Libraries and Set Up
You can use the IDE of your choice, whether it's VS Code, IntelliJ, or another environment that you're comfortable with.Start by importing necessary packages and libraries to handle the API request. These libraries will manage file I/O, HTTP requests, and JSON parsing. Ensure the file is accessible via a URL or upload it if needed.
Set Up the API Key
Obtain your API key by signing up or logging into your PDF.co account. This key authenticates your requests to the API. Initialize the API key in your code.
Prepare the API Request Payload
Customize the payload with the following:
- Source File URL: The location of your PDF form.
- File Password (if applicable): Add if the PDF is password-protected.
- TemplateID: The TemplateID references a saved JSON template on your PDF.co account that defines all the necessary instructions for extracting data from a document, including keywords, objects, and expressions. Users can either use the built-in templates provided by the API or create and save custom templates to achieve their desired output.
- Output Format: Set this to "CSV" for the desired output.
Enable Asynchronous Processing
Set the "async" parameter in your request body to true. This ensures the processing happens asynchronously, allowing you to poll for results without waiting for the process to finish.
Send the API Request
Use an HTTP POST request to send the payload to the Document Parser endpoint. Ensure the payload is JSON-formatted with all necessary parameters.
Poll for Job Status
The API will return a jobId and a statusUrl to track the processing status. Use these details to periodically check if the job is complete.
Retrieve and Save the Results
Once the job status is "success", download the resulting CSV file using the resultUrl provided in the response. Save the file locally, for example, as result.csv.
Results
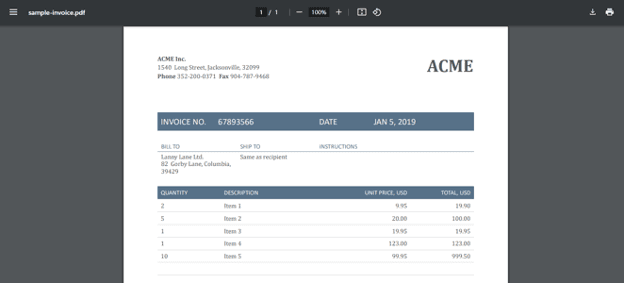
Source PDF File for CSV Extraction
Below is the screenshot of the source PDF file.
Output File in CSV Format
Below is the CSV output of the above code:
Company Name,Invoice No,Date,Total Due,tableNames,tables
ACME Inc.,,,,Table Items,"Column1,Column2
ACME Inc.,
""1540 Long Street, Jacksonville, 32099"",ACME Phone 352-200-0371 Fax 904-787-9468,"Related Tutorials
