Extract PDF Attachments using PDF.co and Node.js
A PDF can have other files attached to it. This might not be apparent when we’re viewing PDF files in the browser, however many PDF viewers have this feature to extract and display PDF attachment files.
IN THIS TUTORIAL
Sample File
For example, let’s consider this sample PDF. When this PDF is opened in the browser, we’re only able to view PDF contents like below.
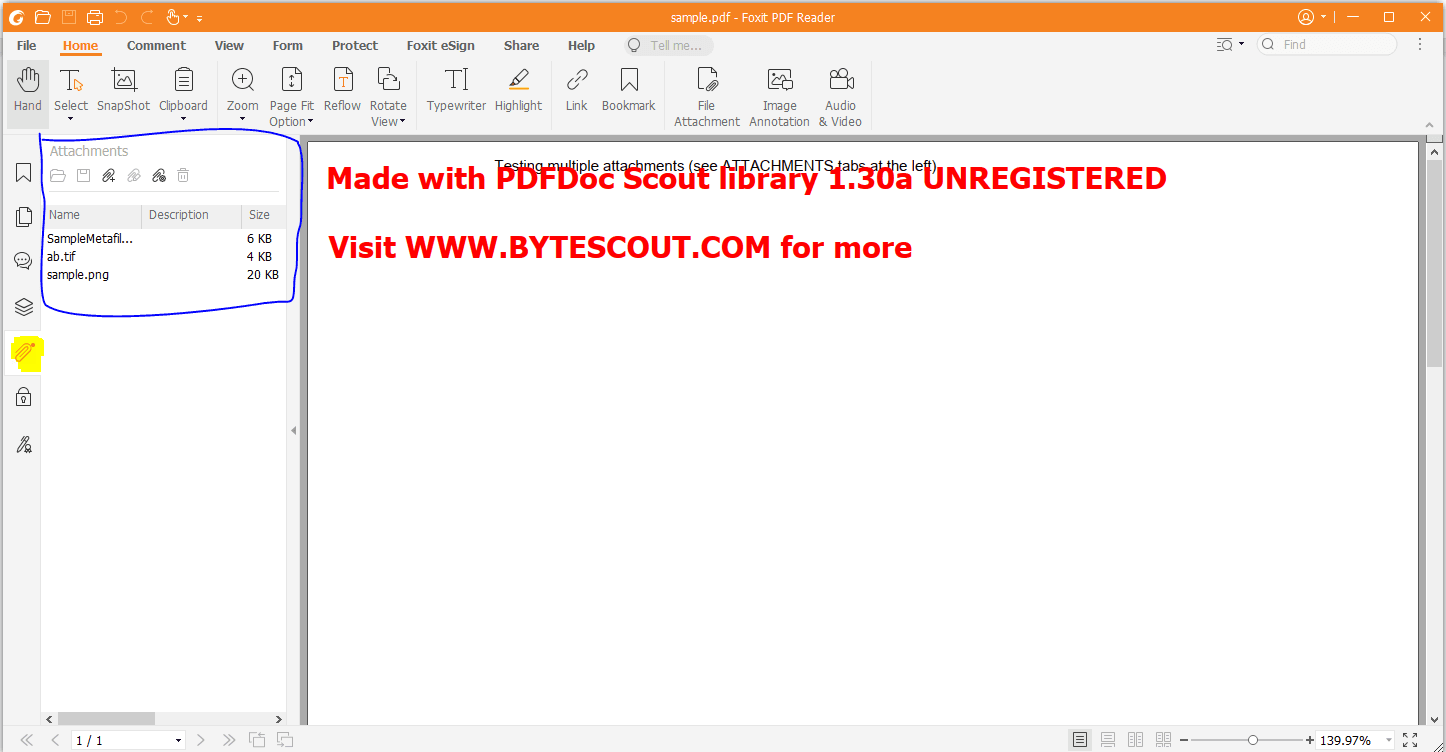
However, when the same file is opened in PDF Reader software attachments are visible.
Source Code
The main goal of this tutorial is to demonstrate how to extract PDF attachments programmatically. PDF.co API Endpoint v1/pdf/attachments/extract just do this job. Also, we’ll be using NodeJs to demonstrate source code.
Let’s dive into the source code first, then we’ll analyze it!
var https = require("https");
var fs = require("fs");
var path = require("path");
// The authentication key (API Key).
// Get your own by registering at https://app.pdf.co
const API_KEY = "***********************************";
// Source PDF file
// You can also upload your own file into PDF.co and use it as url. Check "Upload File" samples for code snippets: https://github.com/bytescout/pdf-co-api-samples/tree/master/File%20Upload/
const SourceFileUrl = "https://bytescout-com.s3.us-west-2.amazonaws.com/files/demo-files/cloud-api/pdf-attachments/attachments.pdf";
// Prepare request for API endpoint
var queryPath = `/v1/pdf/attachments/extract`;
// JSON payload for api request
var jsonPayload = JSON.stringify({
url: SourceFileUrl
});
var reqOptions = {
host: "api.pdf.co",
method: "POST",
path: queryPath,
headers: {
"x-api-key": API_KEY,
"Content-Type": "application/json",
"Content-Length": Buffer.byteLength(jsonPayload, 'utf8')
}
};
// Send request
var postRequest = https.request(reqOptions, (response) => {
response.on("data", (d) => {
// Parse JSON response
var data = JSON.parse(d);
if (data.error == false) {
// Download extracted files
data.urls.forEach((url) => {
var localFileName = path.basename(url);
var file = fs.createWriteStream(localFileName);
https.get(url, (response2) => {
response2.pipe(file)
.on("close", () => {
console.log(`Generated file saved as "${localFileName}" file.`);
});
});
}, this);
}
else {
// Service reported error
console.log(data.message);
}
});
}).on("error", (e) => {
// Request error
console.error(e);
});
// Write request data
postRequest.write(jsonPayload);
postRequest.end();Code Analysis
Now that we’ve already viewed the source code let’s highlight the important code snippets.
As previously mentioned, PDF.co endpoint v1/pdf/attachments/extract is being used for PDF attachment extraction.
// Prepare request for API endpoint
var queryPath = `/v1/pdf/attachments/extract`;Furthermore, PDF.co API Key is passed into the request header. This API key is required for request authentication.
var reqOptions = {
host: "api.pdf.co",
method: "POST",
path: queryPath,
headers: {
"x-api-key": API_KEY,We can obtain this API key by signing-up with PDF.co.
The rest of the code is simply invoking the PDF.co endpoint, obtaining the resulting JSON, downloading URLs, and saving them as separate files.
Related Tutorials

