Split PDFs by Text and by Page in C# using PDF.CO
In this article, you will see how to split a PDF document using text strings and page indexes. You will be using the PDF.CO Web API in the C# programming language to perform these tasks.
Split PDF by Text Via A URL
In this section, you will see how you can split a PDF document using a text string in a C# console application that calls the PDF.CO Web API for document splitting.
This section is further divided into two parts. First, you will see how to split a PDF document from a URL.
Steps
Create a new C# console application and import the following three libraries:
using System.Net;
using Newtonsoft.Json;
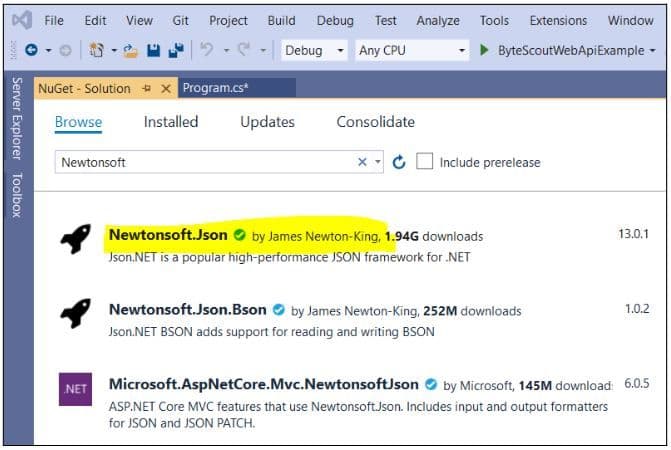
using Newtonsoft.Json.Linq;The System.Net library is a built-in library. However, you will have to install the “NewtonSoft” library yourself. To install this library from the Microsoft Visual Studio IDE, go to “Tools-> NuGet Package Manager.” Search for the “Newtonsoft” library. You will see the following packages. Select the first package and click the “Install” button.
The rest of the script is executed Inside the “Main” method of your C# console application.
The first step is to Store your PDF.CO API key in a variable. You can get your API key by registering at https://app.pdf.co. The URL of the source PDF file that you want to split is also stored in a string variable.
In this section, you will split the PDF document located at this link:
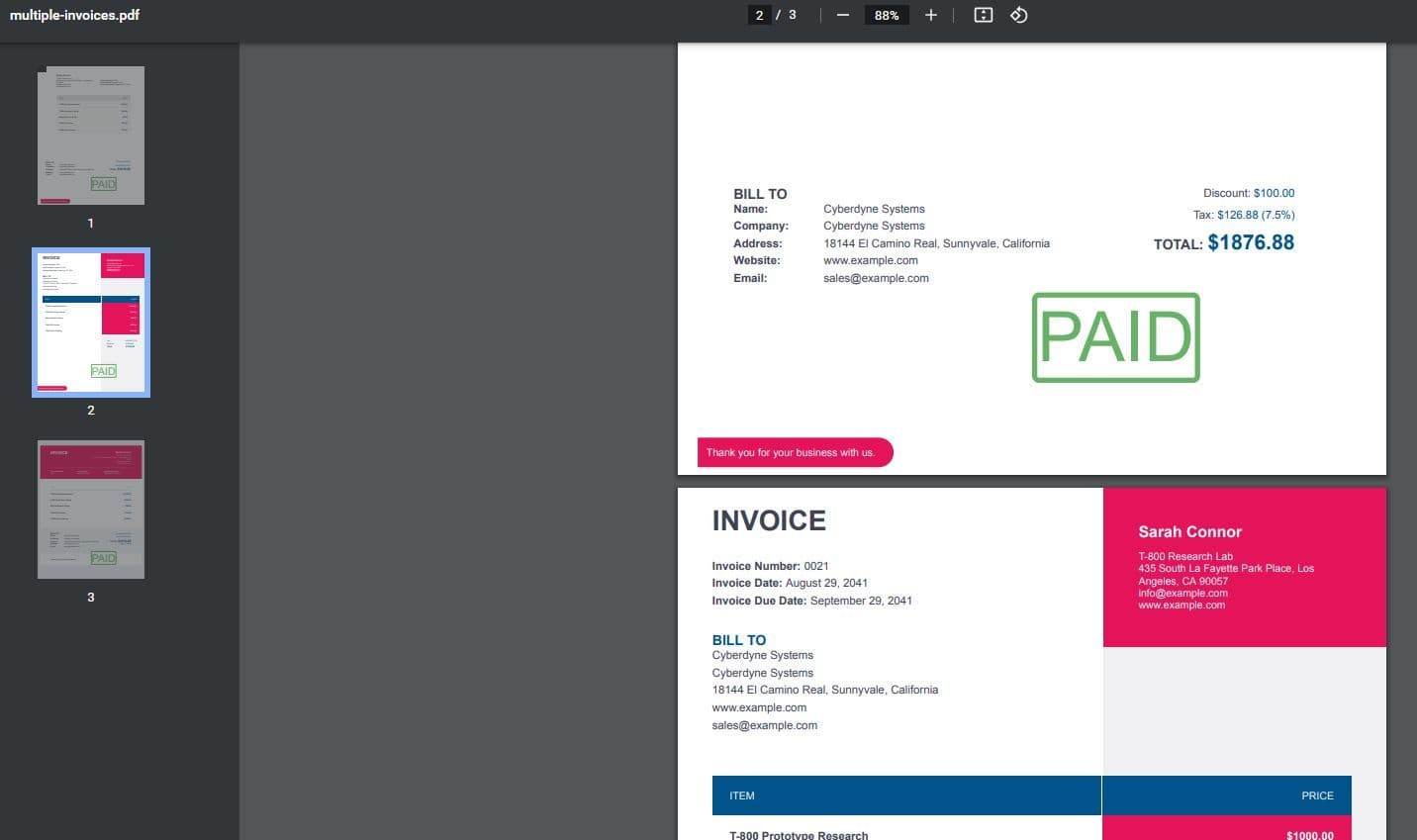
The PDF document contains a purchase invoice.
const String API_KEY = "*************************";
const string SourceFile = @"https://bytescout-com.s3-us-west-2.amazonaws.com/files/demo-files/cloud-api/pdf-split/multiple-invoices.pdf";Next, you need to create an object for the WebClient class. This object will be used to make calls to the PDF.CO web API.
WebClient webClient = new WebClient();
webClient.Headers.Add("x-api-key", API_KEY);Finally, it would be best if you stored the PDF.CO Web API call in a string variable. The PDF.CO Web API call that splits a PDF document by text is as follows:
string url = “https://api.pdf.co/v1/pdf/split2”;
The next step is to define a parameter dictionary containing parameter values that will be passed to the PDF.CO Web API call.
To split a document by text, we only need to pass text to split to the “SearchString” parameter and the path to the source file to the “url” parameter of the parameter dictionary.
You will also need to serialize the python dictionary using the JsonConvert.SerializeObject() function.
Dictionary<string, object> parameters = new Dictionary<string, object>();
parameters.Add("searchString", "invoice number");
parameters.Add("url", SourceFile);
// Convert dictionary of params to JSON
string jsonPayload = JsonConvert.SerializeObject(parameters);Note: You can look at the rest of the optional parameters at the official documentation link.
The rest of the process is straightforward. Inside the try/catch block, make a call to the PDF.CO Web API using the UploadString() method of the WebClient class object.
The response from the API call is then parsed as a JSON object. In case the response contains an error, the error message is displayed.
If the response doesn’t contain any error, the URLs returned in the JSON response are iterated. Each URL contains a link to the split part of the PDF document. The split PDF document can be downloaded to your local file system.
Finally, the WebClient class object is disposed of.
The following script performs all these steps.
try
{
string response = webClient.UploadString(url, jsonPayload);
JObject json = JObject.Parse(response);
if (json["error"].ToObject<bool>() == false)
{
// Download generated PDF files
int part = 1;
foreach (JToken token in json["urls"])
{
string resultFileUrl = token.ToString();
string localFileName = String.Format(@"D:\Datasets\part{0}.pdf", part);
webClient.DownloadFile(resultFileUrl, localFileName);
Console.WriteLine("Downloaded \"{0}\".", localFileName);
part++;
}
}
else
{
Console.WriteLine(json["message"].ToString());
}
}
catch (WebException e)
{
Console.WriteLine(e.ToString());
}
webClient.Dispose();
Console.WriteLine();
Console.WriteLine("Press any key...");
Console.ReadKey();Complete Code
Here is the code for splitting a PDF document from a URL, using a text string.
using System.Net;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;
namespace PDFCOWebApiExample
{
public class Program
{
const String API_KEY = "usmanmalik57@gmail.com_8df5671cedb0fb37ec9610eada409f110c38";
const string SourceFile = @"https://bytescout-com.s3-us-west-2.amazonaws.com/files/demo-files/cloud-api/pdf-split/multiple-invoices.pdf";
static void Main(string[] args)
{
WebClient webClient = new WebClient();
webClient.Headers.Add("x-api-key", API_KEY);
string url = "https://api.pdf.co/v1/pdf/split2";
Dictionary<string, object> parameters = new Dictionary<string, object>();
parameters.Add("searchString", "invoice number");
parameters.Add("url", SourceFile);
// Convert dictionary of params to JSON
string jsonPayload = JsonConvert.SerializeObject(parameters);
try
{
string response = webClient.UploadString(url, jsonPayload);
JObject json = JObject.Parse(response);
if (json["error"].ToObject<bool>() == false)
{
// Download generated PDF files
int part = 1;
foreach (JToken token in json["urls"])
{
string resultFileUrl = token.ToString();
string localFileName = String.Format(@"D:\Datasets\part{0}.pdf", part);
webClient.DownloadFile(resultFileUrl, localFileName);
Console.WriteLine("Downloaded \"{0}\".", localFileName);
part++;
}
}
else
{
Console.WriteLine(json["message"].ToString());
}
}
catch (WebException e)
{
Console.WriteLine(e.ToString());
}
webClient.Dispose();
Console.WriteLine();
Console.WriteLine("Press any key...");
Console.ReadKey();
}
}
}Console Output
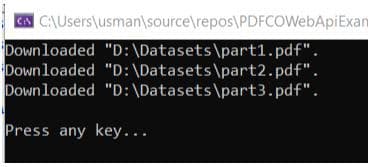
Since the text “invoice number” is found on three pages of our input PDF document, the document is split into three parts.
Input Document
Output Documents
Split PDF by Text Via Uploaded File
In this section, you will see how you can split a PDF document uploaded from your local file system.
Steps
The process of splitting a PDF document via an uploaded file is very similar to the one used for splitting a PDF document from a URL. The only difference lies in the step for uploading a PDF file from your local file system to a data cloud.
Let’s see how to do this.
Following script imports the required libraries.
using System.Net;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;The script below sets your API key and the path to the source file on your local file system.
const String API_KEY = "************************";
const string SourceFile = @"D:\Datasets\multiple-invoices.pdf";The following script creates a WebClient object.
WebClient webClient = new WebClient();
webClient.Headers.Add("x-api-key", API_KEY);The next step is to upload the local PDF document from your hard drive.
The following script uses the WebClient class object to fetch the URL from the PDF.CO cloud storage. Your local PDF document will be uploaded to that URL.
string query = Uri.EscapeUriString(string.Format(
"https://api.pdf.co/v1/file/upload/get-presigned-url?contenttype=application/octet-stream&name={0}",
Path.GetFileName(SourceFile)));
try
{
string response = webClient.DownloadString(query);
JObject json = JObject.Parse(response);
if (json["error"].ToObject<bool>() == false)
{
// Get URL to use for the file upload
string uploadUrl = json["presignedUrl"].ToString();
string uploadedFileUrl = json["url"].ToString();
// 2. UPLOAD THE FILE TO CLOUD.
webClient.Headers.Add("content-type", "application/octet-stream");
webClient.UploadFile(uploadUrl, "PUT", SourceFile); // You can use UploadData() instead if your file is byte[] or Stream
webClient.Headers.Remove("content-type");The rest of the process is similar to what you have already seen. The following script stores the Web API call to split the document.
// 3. SPLIT UPLOADED PDF By Text
string url = "https://api.pdf.co/v1/pdf/split2";
Dictionary<string, object> parameters = new Dictionary<string, object>();
parameters.Add("searchString", "invoice number");
parameters.Add("url",uploadedFileUrl);
// Convert dictionary of params to JSON
string jsonPayload = JsonConvert.SerializeObject(parameters);The script below splits the document and stores the split parts in your local file system.
try
{
response = webClient.UploadString(url, jsonPayload);
json = JObject.Parse(response);
if (json["error"].ToObject<bool>() == false)
{
// Download generated PDF files
int part = 1;
foreach (JToken token in json["urls"])
{
string resultFileUrl = token.ToString();
string localFileName = String.Format(@"D:\Datasets\part{0}.pdf", part);
webClient.DownloadFile(resultFileUrl, localFileName);
Console.WriteLine("Downloaded \"{0}\".", localFileName);
part++;
}
}
else
{
Console.WriteLine(json["message"].ToString());
}
}
catch (WebException e)
{
Console.WriteLine(e.ToString());
}
}
else
{
Console.WriteLine(json["message"].ToString());
}
}
catch (WebException e)
{
Console.WriteLine(e.ToString());
}
webClient.Dispose();
Console.WriteLine();
Console.WriteLine("Press any key...");
Console.ReadKey();Complete Code
using System.Net;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;
namespace ByteScoutWebApiExample
{
class Program
{
const String API_KEY = "***********************";
const string SourceFile = @"D:\Datasets\multiple-invoices.pdf";
static void Main(string[] args)
{
WebClient webClient = new WebClient();
webClient.Headers.Add("x-api-key", API_KEY);
string query = Uri.EscapeUriString(string.Format(
"https://api.pdf.co/v1/file/upload/get-presigned-url?contenttype=application/octet-stream&name={0}",
Path.GetFileName(SourceFile)));
try
{
string response = webClient.DownloadString(query);
JObject json = JObject.Parse(response);
if (json["error"].ToObject<bool>() == false)
{
// Get URL to use for the file upload
string uploadUrl = json["presignedUrl"].ToString();
string uploadedFileUrl = json["url"].ToString();
// 2. UPLOAD THE FILE TO CLOUD.
webClient.Headers.Add("content-type", "application/octet-stream");
webClient.UploadFile(uploadUrl, "PUT", SourceFile); // You can use UploadData() instead if your file is byte[] or Stream
webClient.Headers.Remove("content-type");
// 3. SPLIT UPLOADED PDF By Text
string url = "https://api.pdf.co/v1/pdf/split2";
Dictionary<string, object> parameters = new Dictionary<string, object>();
parameters.Add("searchString", "invoice number");
parameters.Add("url",uploadedFileUrl);
// Convert dictionary of params to JSON
string jsonPayload = JsonConvert.SerializeObject(parameters);
try
{
response = webClient.UploadString(url, jsonPayload);
json = JObject.Parse(response);
if (json["error"].ToObject<bool>() == false)
{
// Download generated PDF files
int part = 1;
foreach (JToken token in json["urls"])
{
string resultFileUrl = token.ToString();
string localFileName = String.Format(@"D:\Datasets\part{0}.pdf", part);
webClient.DownloadFile(resultFileUrl, localFileName);
Console.WriteLine("Downloaded \"{0}\".", localFileName);
part++;
}
}
else
{
Console.WriteLine(json["message"].ToString());
}
}
catch (WebException e)
{
Console.WriteLine(e.ToString());
}
}
else
{
Console.WriteLine(json["message"].ToString());
}
}
catch (WebException e)
{
Console.WriteLine(e.ToString());
}
webClient.Dispose();
Console.WriteLine();
Console.WriteLine("Press any key...");
Console.ReadKey();
}
}
}Console Output
Input Document
Output Documents
Split PDF by Page
The process of Splitting a PDF document by Page is similar to splitting a PDF document by text string with two main differences.
The first difference is that instead of the text string, you have to specify the page indexes. The second difference lies in the PDF.CO Web API call.
Let’s see an example. You have already seen most of these steps, so I will briefly skim through them.
Steps
The following script imports the required libraries.
using System.Net;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;The script below stores the API key and the URL to the input PDF file. The page numbers also need to be stored in the form of a string. You can specify individual pages to split via commas or a range of page numbers using a hyphen. The following script splits the PDF document into two parts: page 1 and pages 2-3.
const String API_KEY = "***************************";
const string SourceFile = @"https://bytescout-com.s3-us-west-2.amazonaws.com/files/demo-files/cloud-api/pdf-split/multiple-invoices.pdf";
const string Pages = "1,2-3";Next, we create a WebClient class object.
WebClient webClient = new WebClient();
webClient.Headers.Add("x-api-key", API_KEY);The PDF.CO call to split PDF document by page index is as follows.
string url = "https://api.pdf.co/v1/pdf/split";The next step is to create a parameter dictionary containing pages, and the URL of the input PDF document.
The detail of other optional parameters is available at the official documentation link.
Dictionary<string, object> parameters = new Dictionary<string, object>();
parameters.Add("pages", Pages);
parameters.Add("url", SourceFile);
// Convert dictionary of params to JSON
string jsonPayload = JsonConvert.SerializeObject(parameters);The following script makes a call to the PDF.CO Web API parses the response as a JSON object.
string response = webClient.UploadString(url, jsonPayload);
JObject json = JObject.Parse(response);Next, split pages are downloaded via the following script, and the WebClient object is disposed of.
try
{
string response = webClient.UploadString(url, jsonPayload);
JObject json = JObject.Parse(response);
if (json["error"].ToObject<bool>() == false)
{
// Download generated PDF files
int part = 1;
foreach (JToken token in json["urls"])
{
string resultFileUrl = token.ToString();
string localFileName = String.Format(@"D:\Datasets\part{0}.pdf", part);
webClient.DownloadFile(resultFileUrl, localFileName);
Console.WriteLine("Downloaded \"{0}\".", localFileName);
part++;
}
}
else
{
Console.WriteLine(json["message"].ToString());
}
}
catch (WebException e)
{
Console.WriteLine(e.ToString());
}
webClient.Dispose();
Console.WriteLine();
Console.WriteLine("Press any key...");
Console.ReadKey();Complete Code
using System.Net;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;namespace PDFCOWebApiExample
{
public class Program
{
const String API_KEY = "************************";
const string SourceFile = @"https://bytescout-com.s3-us-west-2.amazonaws.com/files/demo-files/cloud-api/pdf-split/multiple-invoices.pdf";
const string Pages = "1,2-3";
static void Main(string[] args)
{
WebClient webClient = new WebClient();
webClient.Headers.Add("x-api-key", API_KEY);
string url = "https://api.pdf.co/v1/pdf/split";
Dictionary<string, object> parameters = new Dictionary<string, object>();
parameters.Add("pages", Pages);
parameters.Add("url", SourceFile);
// Convert dictionary of params to JSON
string jsonPayload = JsonConvert.SerializeObject(parameters);
try
{
string response = webClient.UploadString(url, jsonPayload);
JObject json = JObject.Parse(response);
if (json["error"].ToObject<bool>() == false)
{
// Download generated PDF files
int part = 1;
foreach (JToken token in json["urls"])
{
string resultFileUrl = token.ToString();
string localFileName = String.Format(@"D:\Datasets\part{0}.pdf", part);
webClient.DownloadFile(resultFileUrl, localFileName);
Console.WriteLine("Downloaded \"{0}\".", localFileName);
part++;
}
}
else
{
Console.WriteLine(json["message"].ToString());
}
}
catch (WebException e)
{
Console.WriteLine(e.ToString());
}
webClient.Dispose();
Console.WriteLine();
Console.WriteLine("Press any key...");
Console.ReadKey();
}
}
}Console Output
Input Document
Output Documents