This article explains how you can generate a secure PDF document using the PDF.CO Web API.
The PDF.CO Web API provides several options to generate a secure PDF, e.g., adding password and encryption to a document, converting a document to an image, adding a watermark to an image, and making a PDF document unsearchable.
In this article, you will see how to generate a secure PDF document by:
So, let’s begin without further ado.
Make a PDF Document Unsearchable
We will create a C# console application that demonstrates how you can call the PDF.CO web API to make a PDF document unsearchable.
Creating the Application
The first step is to import the required libraries as shown below:
using System;
using System.Collections.Generic;
using System.IO;
using System.Net;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;All the aforementioned libraries are by default installed with the Microsoft .NET framework except the Newtonsoft library. You can install the Newtonsoft library in the Microsoft Visual Studio IDE.
In Visual Studio, go to “Tools-> NuGet Package Manager”. Search for “Newtonsoft” library. You will see the following packages. Select the first package and click the “Install” button.
In this section, we will be generating a PDF file using a CSV file. The sample CSV file is located at this link:
https://bytescout-com.s3.amazonaws.com/files/demo-files/cloud-api/csv-to-pdf/sample.csv
Next, we will define variables that store the PDF.CO API key, the URL to the source CSV file, the path to the destination PDF file, and the password for the source PDF file if any. Here is a script for that.
const String API_KEY = "****************";
const string SourceFile = @"https://bytescout-com.s3.amazonaws.com/files/demo-files/cloud-api/csv-to-pdf/sample.csv";
const string DestinationFile = @".\newDocument.pdf";
const string Password = "";Note: You can get your API key by registering at https://app.pdf.co
We will create an object of the WebClient class that we will use to make requests to the PDF.CO Web API. The rest of the code will be executed inside the main method. The following script creates our web client.
WebClient webClient = new WebClient();
webClient.Headers.Add("x-api-key", API_KEY);The script below defines the API call to the PDF.CO Web API, which will be used to convert a CSV document to PDF.
string url = "https://api.pdf.co/v1/pdf/convert/from/csv";The information passed to the PDF call is stored inside a parameter dictionary. To convert a CSV document to PDF, you only need to pass the URL to the source CSV file and the name of the destination PDF file, as shown in the script below.
Dictionary<string, string> parameters = new Dictionary<string, string>();
parameters.Add("url", SourceFile);
parameters.Add("name", Path.GetFileName(DestinationFile));
// Convert dictionary of params to JSON
string jsonPayload = JsonConvert.SerializeObject(parameters);The script below makes the API call to the PDF.CO Web API using the UploadString() method of the WebClient class object. The response is parsed as a JSON object.
try
{
string response = webClient.UploadString(url, jsonPayload);
JObject json = JObject.Parse(response);Next, we check if the response contains an error, if it contains an error a message is printed on the console. Else, the converted PDF file is downloaded. Here is a script to do so:
if (json["error"].ToObject<bool>() == false)
{
string resultFileUrl = json["url"].ToString();
Console.WriteLine(resultFileUrl);
webClient.DownloadFile(resultFileUrl, DestinationFile);
Console.WriteLine("Generated PDF file saved as \"{0}\" file.", DestinationFile);We have successfully generated a PDF file from a CSV file. This is just one of the many amazing functionalities of PDF.co Web API, which could also help you export PDF to CSV online. We covered this one in another tutorial.
Now, going back to our discussion:
The next step is to make this PDF file secure. To do so, we will make this newly generated PDF file unsearchable.
The PDF file that we just created will be uploaded to the PDF.CO cloud server. Next, will use the PDF.CO Web API to make this PDF file unsearchable.
The script uses PDF.CO Web API to generate a URL where you can upload your newly generated PDF document.
string query = Uri.EscapeUriString(string.Format(
"https://api.pdf.co/v1/file/upload/get-presigned-url?contenttype=application/octet-stream&name={0}",
Path.GetFileName(DestinationFile)));
string response2 = webClient.DownloadString(query);
JObject json2 = JObject.Parse(response2);
string uploadUrl = json2["presignedUrl"].ToString();
string uploadedFileUrl = json2["url"].ToString();The script below uses the UploadFile() method to upload the PDF file to the PDF.CO cloud.
// UPLOAD THE FILE TO CLOUD.
webClient.Headers.Add("content-type", "application/octet-stream");
webClient.UploadFile(uploadUrl, "PUT", DestinationFile);We are now ready to call the PDF.CO Web API that makes a PDF document unbearable. The API call which makes a PDF file unsearchable is stored in a string variable as shown below:
var url2 = "https://api.pdf.co/v1/pdf/makeunsearchable";Just like you did while converting a CSV file to PDF, you need to create a parameter dictionary that contains information passed to the API call that makes a PDF document unsearchable. The following script does that.
Dictionary<string, object> parameters2 = new Dictionary<string, object>();
parameters2.Add("name", Path.GetFileName(DestinationFile));
parameters2.Add("password", Password);
parameters2.Add("url", uploadedFileUrl);
parameters2.Add("pages", "");
parameters2.Add("lang", "eng");Check out the official API Documentation to learn more about the aforementioned parameters.
Next, you need to serialize your parameter dictionary and pass it to the PDF.CO Web API via the WebClient class object. The response is parsed as a JSON object as shown in the script below:
string jsonPayload2 = JsonConvert.SerializeObject(parameters2);
// Execute POST request with JSON payload
response2 = webClient.UploadString(url2, jsonPayload2);
// Parse JSON response
json2 = JObject.Parse(response2);The rest of the process is similar to generating a PDF file. If the response from the API call contains an error, the error is displayed on the console. Else, the unsearchable PDF file is downloaded via the WebClient class object as shown in the script below:
if (json["error"].ToObject<bool>() == false)
{
// Get URL of generated PDF file
string resultFileUrl2 = json2["url"].ToString();
// Download PDF file
webClient.DownloadFile(resultFileUrl2, DestinationFile);
Console.WriteLine("Generated PDF file saved as \"{0}\" file.", DestinationFile);
}
else
{
Console.WriteLine(json["message"].ToString());
}
}Finally, the script below disposes of the WebClient class object.
catch (WebException e)
{
Console.WriteLine(e.ToString());
}
webClient.Dispose();
Console.WriteLine();
Console.WriteLine("Press any key...");
Console.ReadKey();Complete Code
using System;
using System.Collections.Generic;
using System.IO;
using System.Net;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;
namespace ByteScoutWebApiExample
{
class Program
{
const String API_KEY = "***********************";
const string SourceFile = @"https://bytescout-com.s3.amazonaws.com/files/demo-files/cloud-api/csv-to-pdf/sample.csv";
const string DestinationFile = @".\newDocument.pdf";
const string Password = "";
static void Main(string[] args)
{
WebClient webClient = new WebClient();
webClient.Headers.Add("x-api-key", API_KEY);
string url = "https://api.pdf.co/v1/pdf/convert/from/csv";
Dictionary<string, string> parameters = new Dictionary<string, string>();
parameters.Add("url", SourceFile);
parameters.Add("name", Path.GetFileName(DestinationFile));
// Convert dictionary of params to JSON
string jsonPayload = JsonConvert.SerializeObject(parameters);
try
{
string response = webClient.UploadString(url, jsonPayload);
JObject json = JObject.Parse(response);
if (json["error"].ToObject<bool>() == false)
{
string resultFileUrl = json["url"].ToString();
Console.WriteLine(resultFileUrl);
webClient.DownloadFile(resultFileUrl, DestinationFile);
Console.WriteLine("Generated PDF file saved as \"{0}\" file.", DestinationFile);
// Make file unsearchable
string query = Uri.EscapeUriString(string.Format(
"https://api.pdf.co/v1/file/upload/get-presigned-url?contenttype=application/octet-stream&name={0}",
Path.GetFileName(DestinationFile)));
string response2 = webClient.DownloadString(query);
JObject json2 = JObject.Parse(response2);
string uploadUrl = json2["presignedUrl"].ToString();
string uploadedFileUrl = json2["url"].ToString();
// 2. UPLOAD THE FILE TO CLOUD.
webClient.Headers.Add("content-type", "application/octet-stream");
webClient.UploadFile(uploadUrl, "PUT", DestinationFile); // You can use UploadData() instead if your file is byte[] or Stream
var url2 = "https://api.pdf.co/v1/pdf/makeunsearchable";
Dictionary<string, object> parameters2 = new Dictionary<string, object>();
parameters2.Add("name", Path.GetFileName(DestinationFile));
parameters2.Add("password", Password);
parameters2.Add("url", uploadedFileUrl);
parameters2.Add("pages", "");
parameters2.Add("lang", "eng");
string jsonPayload2 = JsonConvert.SerializeObject(parameters2);
// Execute POST request with JSON payload
response2 = webClient.UploadString(url2, jsonPayload2);
// Parse JSON response
json2 = JObject.Parse(response2);
if (json["error"].ToObject<bool>() == false)
{
// Get URL of generated PDF file
string resultFileUrl2 = json2["url"].ToString();
// Download PDF file
webClient.DownloadFile(resultFileUrl2, DestinationFile);
Console.WriteLine("Generated PDF file saved as \"{0}\" file.", DestinationFile);
}
else
{
Console.WriteLine(json["message"].ToString());
}
}
else
{
Console.WriteLine(json["message"].ToString());
}
}
catch (WebException e)
{
Console.WriteLine(e.ToString());
}
webClient.Dispose();
Console.WriteLine();
Console.WriteLine("Press any key...");
Console.ReadKey();
}
}
}Output
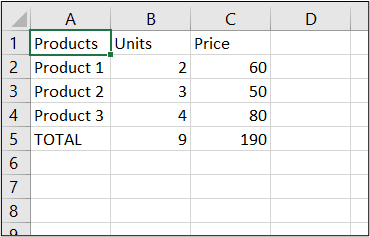
Our input CSV file looks like this:
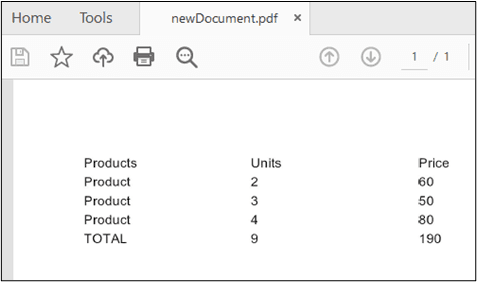
After executing the scripts in this section, a secure and unsearchable PDF file will be generated which looks like this:
Convert PDF to Image
Another way to secure a PDF document is by converting the document to an image. The PDF Generator API can help you do this or even the other way around – image or doc to PDF, email or HTML to PDF, and much more.
Normally, it is difficult to copy content from an image compared to a simple PDF document. Let’s see how you can convert a PDF document to an Image using the PDF.CO Web API.
Here is the Input PDF

The first step is to define the API key and the source PDF file that will be converted to an image. The password for the source file is also stored.
const String API_KEY = "**************************";
const string SourceFile = @"https://bytescout-com.s3.amazonaws.com/files/demo-files/cloud-api/pdf-to-image/sample.pdf";
const string Password = "";Next, we define a WebClient class object that will be used to make calls to the PDF.CO Web API.
WebClient webClient = new WebClient();
webClient.Headers.Add("x-api-key", API_KEY);The path to the API call is stored in a string type variable, as shown below:
string url = "https://api.pdf.co/v1/pdf/convert/to/jpg";In the next step, we need to create a parameter dictionary that contains the password of the PDF file, the URL to the source file, and the number of pages that we want to convert to images. If you leave the number of pages empty, all pages will be converted to images.
Dictionary<string, object> parameters = new Dictionary<string, object>();
parameters.Add("password", Password);
parameters.Add("pages", "");
parameters.Add("url", SourceFile);
// Convert dictionary of params to JSON
string jsonPayload = JsonConvert.SerializeObject(parameters);Check out the official PDF.CO Web API documentation to learn more about the parameters mentioned in the above script.
Next, inside the try/catch block, the UploadString() method from the WebClient class object makes the API call. The response is parsed as a JSON object.
If the response doesn’t contain an error, a for loop executes through all the URLs for all the images generated. The images are then locally stored.
try
{
string response = webClient.UploadString(url, jsonPayload);
JObject json = JObject.Parse(response);
if (json["error"].ToObject<bool>() == false)
{
int page = 1;
foreach (JToken token in json["urls"])
{
string resultFileUrl = token.ToString();
string localFileName = String.Format(@".\page{0}.jpg", page);
webClient.DownloadFile(resultFileUrl, localFileName);
Console.WriteLine("Downloaded \"{0}\".", localFileName);
page++;
}
}
else
{
Console.WriteLine(json["message"].ToString());
}
}
catch (WebException e)
{
Console.WriteLine(e.ToString());
}Finally, the script below destroys the WebClient class object.
webClient.Dispose();
Console.WriteLine();
Console.WriteLine("Press any key...");
Console.ReadKey();Our input PDF document contains 2 pages, therefore when you run the above script, you will see two images generated in the output.
Source Code
using System;
using System.Collections.Generic;
using System.IO;
using System.Net;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;
namespace ByteScoutWebApiExample
{
class Program
{
const String API_KEY = "*********************";
const string SourceFile = @"https://bytescout-com.s3.amazonaws.com/files/demo-files/cloud-api/pdf-to-image/sample.pdf";
const string DestinationFile = @".\newDocument.pdf";
const string Password = "";
static void Main(string[] args)
{
WebClient webClient = new WebClient();
webClient.Headers.Add("x-api-key", API_KEY);
string url = "https://api.pdf.co/v1/pdf/convert/to/jpg";
Dictionary<string, object> parameters = new Dictionary<string, object>();
parameters.Add("password", Password);
parameters.Add("pages", "");
parameters.Add("url", SourceFile);
// Convert dictionary of params to JSON
string jsonPayload = JsonConvert.SerializeObject(parameters);
try
{
string response = webClient.UploadString(url, jsonPayload);
JObject json = JObject.Parse(response);
if (json["error"].ToObject<bool>() == false)
{
int page = 1;
foreach (JToken token in json["urls"])
{
string resultFileUrl = token.ToString();
string localFileName = String.Format(@".\page{0}.jpg", page);
webClient.DownloadFile(resultFileUrl, localFileName);
Console.WriteLine("Downloaded \"{0}\".", localFileName);
page++;
}
}
else
{
Console.WriteLine(json["message"].ToString());
}
}
catch (WebException e)
{
Console.WriteLine(e.ToString());
}
webClient.Dispose();
Console.WriteLine();
Console.WriteLine("Press any key...");
Console.ReadKey();
}
}
}Secure Image Outputs


Related Tutorials
