Extract Table with Text from PDF in C# using PDF.co Web API
In this article, you will see how to extract a table with a text from PDF Document. To do so, we will be using the PDF.co Web API with the C# programming language for this task.
Extract Table with Text from PDF in C# – Step-by-Step
First, you will create a C# console application in this section that calls the PDF.co Web API to extract tables with text from PDF.
This step is to import the required libraries as shown in the following script:
using System;
using System.Collections.Generic;
using System.IO;
using System.Net;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;The Microsoft .NET framework contains all the above packages by default except the “Newtonsoft” library.
To install this library from Microsoft Visual Studio ID, go to “Tools-> NuGet Package Manager”. Search for the “Newtonsoft” library. You will see the following packages. Select the first package and click the “Install” button.
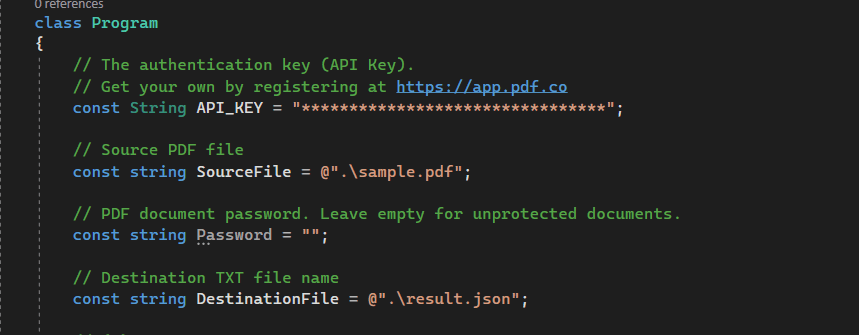
Inside the class, just before the “Main” method, declare three variables: API key from PDF.co, Source PDF File, and the Destination file for storing the destination path for the extracted table with text.
Note: You can get your API key by signing up at https://app.pdf.co.
Next, add the template text you created. You can create a new template in PDF.co Document Parser Template Editor. To learn how to quickly create a template, follow this tutorial.
The complete code for extracting the table with text from PDF in C# is as follows:
Program.cs
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;
using System;
using System.Collections.Generic;
using System.IO;
using System.Net;
using System.Threading;
// Cloud API asynchronous "Document Parser" job example.
// Allows to avoid timeout errors when processing huge or scanned PDF documents.
namespace ByteScoutWebApiExample
{
class Program
{
// The authentication key (API Key).
// Get your own by registering at https://app.pdf.co
const String API_KEY = "***********************************";
// Source PDF file
const string SourceFile = @".\MultiPageTable.pdf";
// PDF document password. Leave empty for unprotected documents.
const string Password = "";
// Destination TXT file name
const string DestinationFile = @".\result.json";
// (!) Make asynchronous job
const bool Async = true;
static void Main(string[] args)
{
// Template text. Use Document Parser (https://pdf.co/document-parser, https://app.pdf.co/document-parser)
// to create templates.
// Read template from file:
String templateText = File.ReadAllText(@".\MultiPageTable-template1.yml");
//String templateText = File.ReadAllText(@".\MultiPageTable-template2.yml");
// Create standard .NET web client instance
WebClient webClient = new WebClient();
// Set API Key
webClient.Headers.Add("x-api-key", API_KEY);
// 1. RETRIEVE THE PRESIGNED URL TO UPLOAD THE FILE.
// * If you already have a direct file URL, skip to the step 3.
// Prepare URL for `Get Presigned URL` API call
string query = Uri.EscapeUriString(string.Format(
"https://api.pdf.co/v1/file/upload/get-presigned-url?contenttype=application/octet-stream&name={0}",
Path.GetFileName(SourceFile)));
try
{
// Execute request
string response = webClient.DownloadString(query);
// Parse JSON response
JObject json = JObject.Parse(response);
if (json["error"].ToObject<bool>() == false)
{
// Get URL to use for the file upload
string uploadUrl = json["presignedUrl"].ToString();
string uploadedFileUrl = json["url"].ToString();
// 2. UPLOAD THE FILE TO CLOUD.
webClient.Headers.Add("content-type", "application/octet-stream");
webClient.UploadFile(uploadUrl, "PUT", SourceFile); // You can use UploadData() instead if your file is byte[] or Stream
webClient.Headers.Remove("content-type");
// 3. PARSE UPLOADED PDF DOCUMENT
// URL of `Document Parser` API call
string url = "https://api.pdf.co/v1/pdf/documentparser";
Dictionary<string, object> requestBody = new Dictionary<string, object>();
requestBody.Add("template", templateText);
requestBody.Add("name", Path.GetFileName(DestinationFile));
requestBody.Add("url", uploadedFileUrl);
requestBody.Add("async", Async);
// Convert dictionary of params to JSON
string jsonPayload = JsonConvert.SerializeObject(requestBody);
// Execute request
response = webClient.UploadString(url, "POST", jsonPayload);
// Parse JSON response
json = JObject.Parse(response);
if (json["error"].ToObject<bool>() == false)
{
// Asynchronous job ID
string jobId = json["jobId"].ToString();
// Get URL of generated JSON file
string resultFileUrl = json["url"].ToString();
// Check the job status in a loop.
// If you don't want to pause the main thread you can rework the code
// to use a separate thread for the status checking and completion.
do
{
string status = CheckJobStatus(webClient, jobId); // Possible statuses: "working", "failed", "aborted", "success".
// Display timestamp and status (for demo purposes)
Console.WriteLine(DateTime.Now.ToLongTimeString() + ": " + status);
if (status == "success")
{
// Download JSON file
webClient.DownloadFile(resultFileUrl, DestinationFile);
Console.WriteLine("Generated JSON file saved as \"{0}\" file.", DestinationFile);
break;
}
else if (status == "working")
{
// Pause for a few seconds
Thread.Sleep(3000);
}
else
{
Console.WriteLine(status);
break;
}
}
while (true);
}
else
{
Console.WriteLine(json["message"].ToString());
}
}
else
{
Console.WriteLine(json["message"].ToString());
}
}
catch (WebException e)
{
Console.WriteLine(e.ToString());
}
webClient.Dispose();
Console.WriteLine();
Console.WriteLine("Press any key...");
Console.ReadKey();
}
static string CheckJobStatus(WebClient webClient, string jobId)
{
string url = "https://api.pdf.co/v1/job/check?jobid=" + jobId;
string response = webClient.DownloadString(url);
JObject json = JObject.Parse(response);
return Convert.ToString(json["status"]);
}
}
}
Template.yml
{
“templateVersion”: 4,
“templatePriority”: 0,
“culture”: “en-US”,
“objects”: [
{
“id”: 1669297411075,
“objectType”: “table”,
“name”: “TableFromRectangle1”,
“tableProperties”: {
“start”: {
“y”: 240,
“pageIndex”: 0,
“expression”: null
},
“end”: {
“y”: 416,
“pageIndex”: 0,
“expression”: null
},
“left”: 32,
“right”: 581
}
}
],
“oldObjects”: [
{
“id”: 1669297411075,
“objectType”: “table”,
“name”: “TableFromRectangle1”,
“tableProperties”: {
“start”: {
“y”: 240,
“pageIndex”: 0,
“expression”: null
},
“end”: {
“y”: 416,
“pageIndex”: 0,
“expression”: null
},
“left”: 32,
“right”: 581
}
}
],
“templateName”: “”,
“description”: “”,
“options”: {
“ocrMode”: “auto”,
“ocrLanguage”: “eng”,
“ocrResolution”: 300,
“ocrImageFilters”: “”,
“ocrWhiteList”: “”,
“ocrBlackList”: “”
}
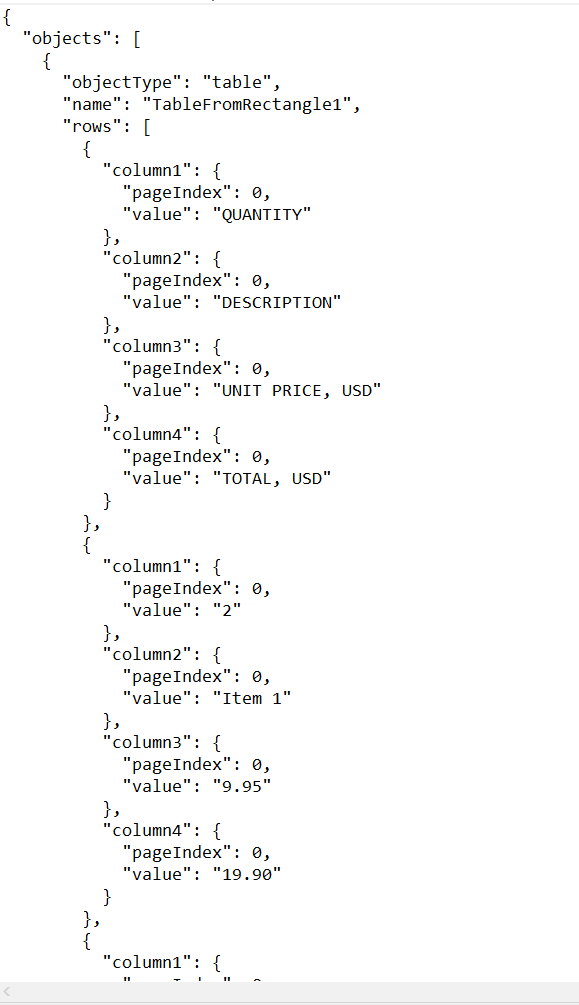
}When you run the above script, a JSON format named “result.json” will be generated in your local directory.
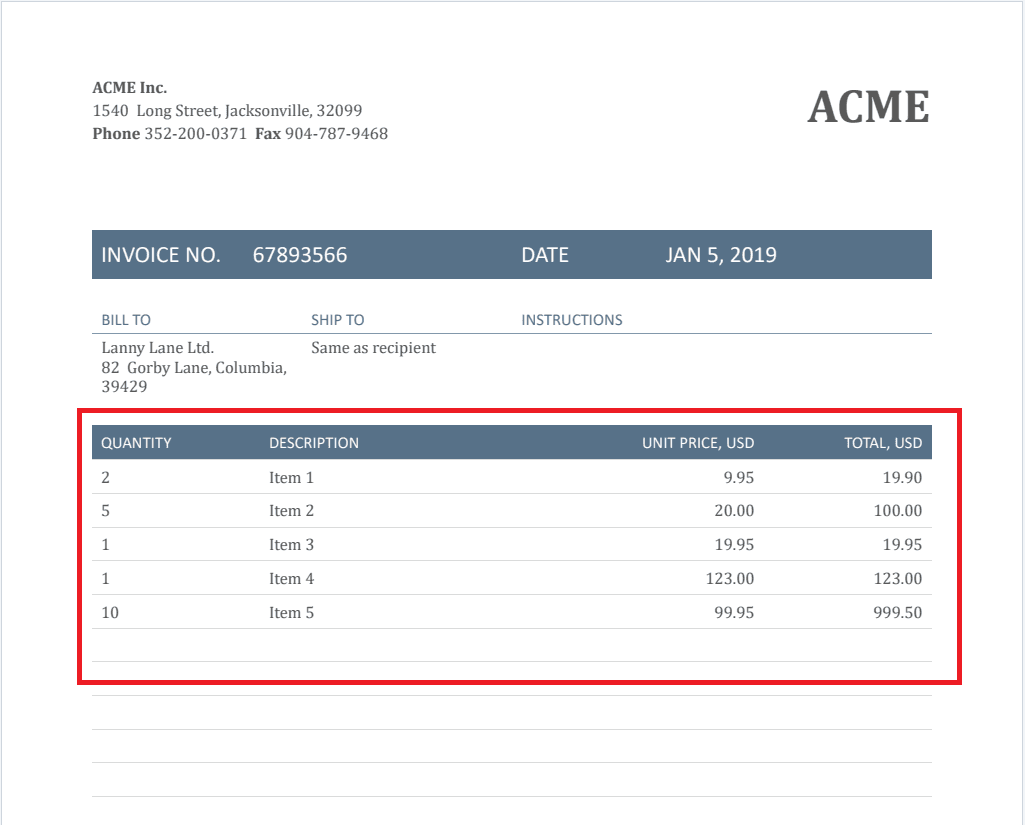
Sample Source File
Here’s the sample PDF file that we used:
JSON Output for PDF Text Extraction in C#
Here’s the extracted table with text in JSON format: