How to Process Large Files with PDF.co and Zapier using Custom API Call Action
By default, Zapier limits steps to run no more than 30 seconds. But some processes for the extraction or converting PDF may take much longer.
The solution is to use 4 separate steps as the following:
- Trigger step: an event to initiate the workflow.
- PDF.co action step with “Async for Large Docs” selected.
- Run Zapier Delay as the next step to wait for 5+ minutes. Depending on the size of your input file.
- Run Job Check for PDF.co to check the result of the job using jobId from the second step.
References: to learn how to customize sample requests and how to set parameters you may want to explore PDF.co API documentations.
Contents
Step 1: Create a Zap
Let’s start by logging into your Zapier account and creating a Zap.
Step 2: Google Drive App
- Next, search and select the Google Drive app. You can also use other file storage services where you want to get the source file.
- Then, choose the New File in Folder to trigger when a new file is added to a folder.
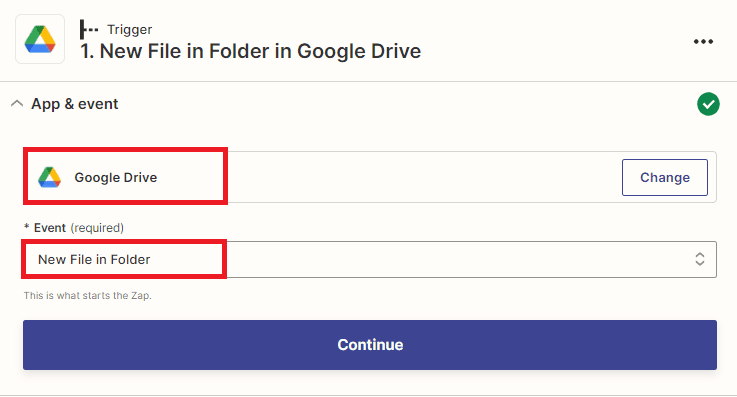
Step 3: Setup Trigger
Let’s set up the trigger.
- First, select My Google Drive as the drive to be used.
- Next, select the specific folder which contains the source file.
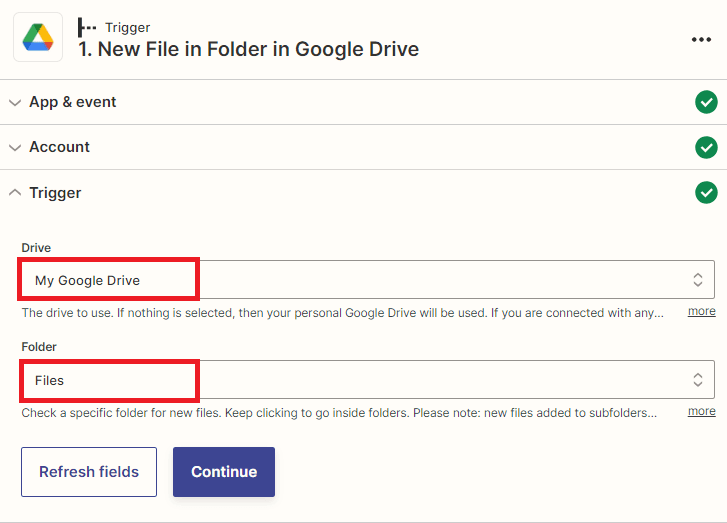
Once you have set up the trigger, it is important to test it to ensure that it has been configured correctly.
Step 4: Test Trigger Result
- Once the test trigger was successful and fetched the file from your Google Drive folder. Let’s move on to the action step to process the large document.
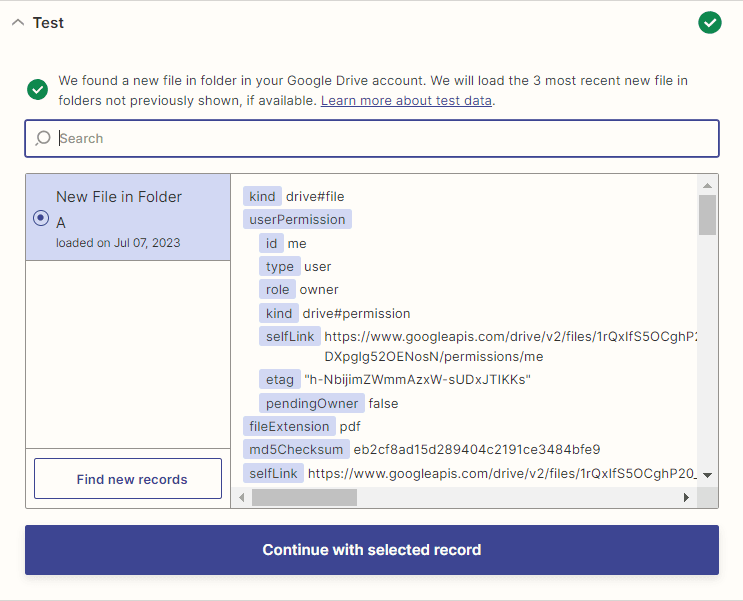
For the next step, we will add the PDF.co action with “Async for Large Docs” for Job Execution Mode. This mode is ideal for files that may take up to 5 minutes to process.
Step 5: Add PDF.co App
- In this step, we will add the PDF.co app and choose the PDF Make Searchable option. This feature will allow us to convert scanned PDF to searchable text PDF and initiate the Async for Large Docs mode to process the large document which may take up to 5 minutes.

Note: To connect your PDF.co account to Zapier, simply add your API Key. You can obtain the API Key from your PDF.co dashboard or by signing up.
Step 6: Setup PDF.co Configuration
Let’s set up the PDF.co configuration.
- In the Source File URL field, select the Web Content Link from Google Drive.
- For the OCR Language field, specify the language for OCR (Optical Character Recognition) when extracting text from scanned documents.
- In the Output File Name field, enter the name of your output file.
- For the Job Execution Mode field, select the Async for Large Docs mode to run the job check module separately and process files that may take up to 5 minutes.
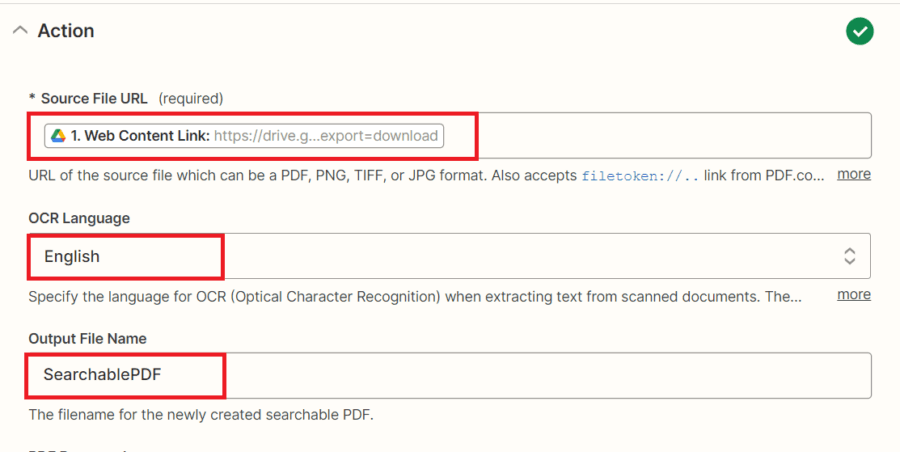
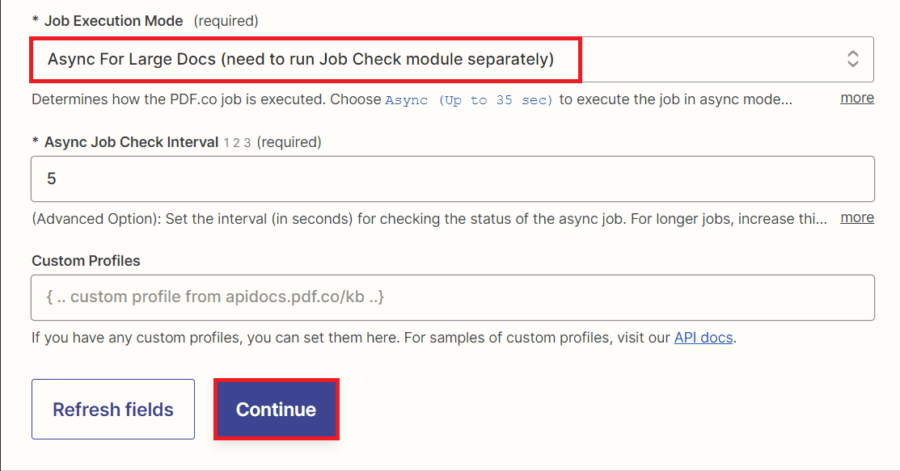
After setting up the PDF.co configuration, let’s test the action to make sure it will process the large document that takes up to 5 minutes.
Step 7: Test Result
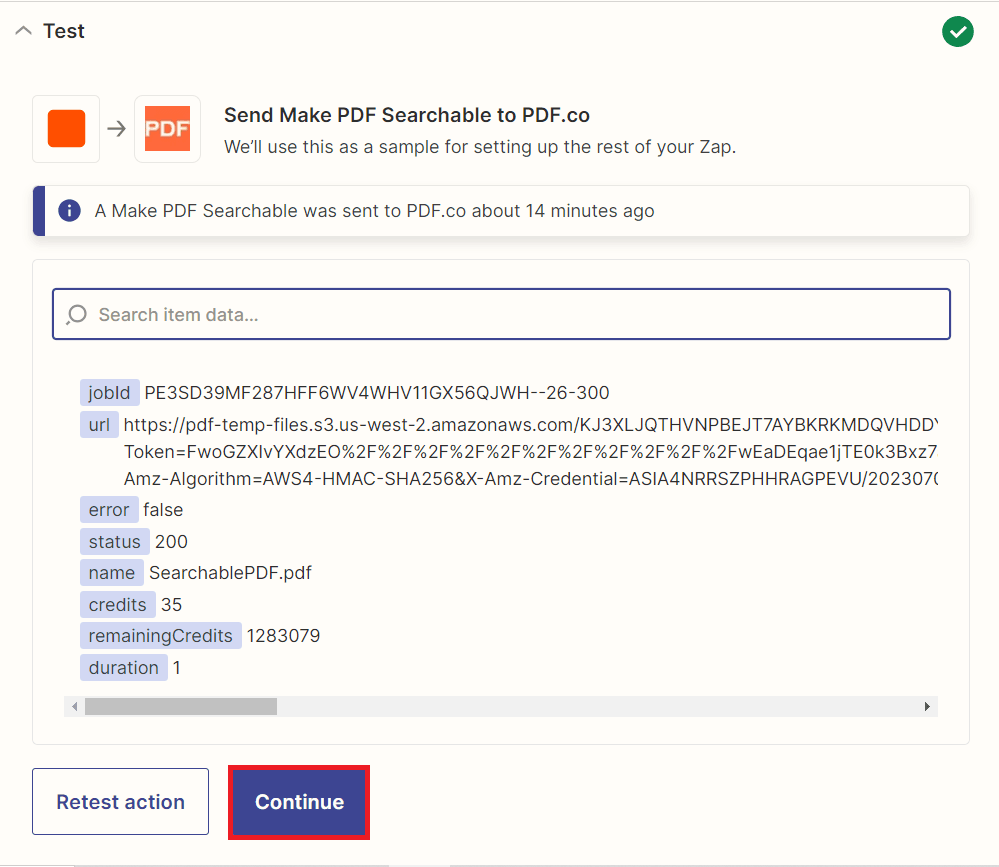
- Excellent! The test was successful and processed the large document. We will now show you how to use the Delay by Zapier feature. Suppose your file requires more than 5 minutes to process. This delay allows sufficient time for the processing to complete.
Step 8: Delay by Zapier
- In this step, we will add the Delay by Zapier feature to process your file to a sufficient time to complete and choose the Delay For option to wait for a set amount of time before completing your Actions.
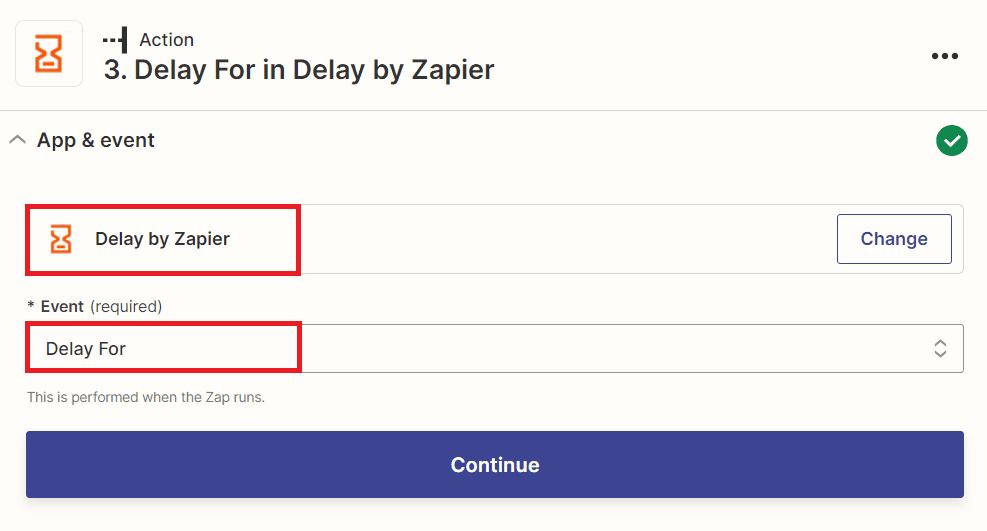
Step 9: Setup Delay For
Let’s set up the Delay configuration.
- Start by entering the desired time value to specify when your actions should be completed.
- Then, select the unit of time to determine the delay.
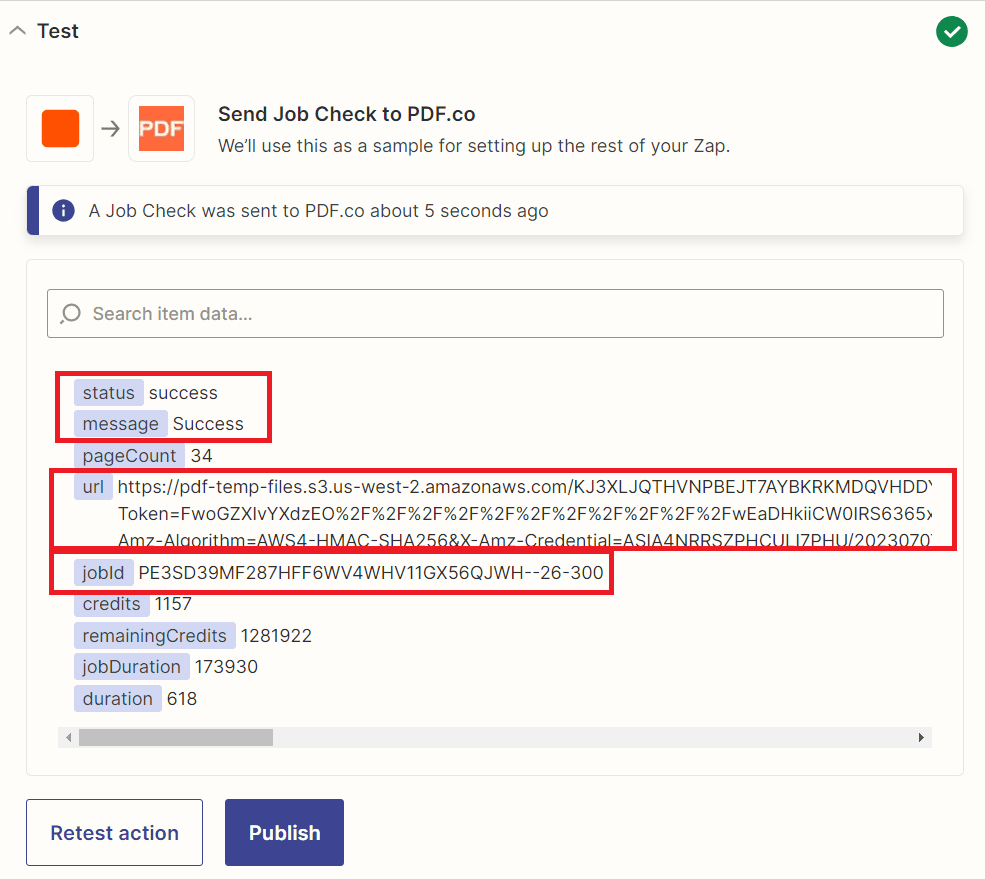
After configuring the delay, it is important to test the action to ensure that it has been set up correctly.
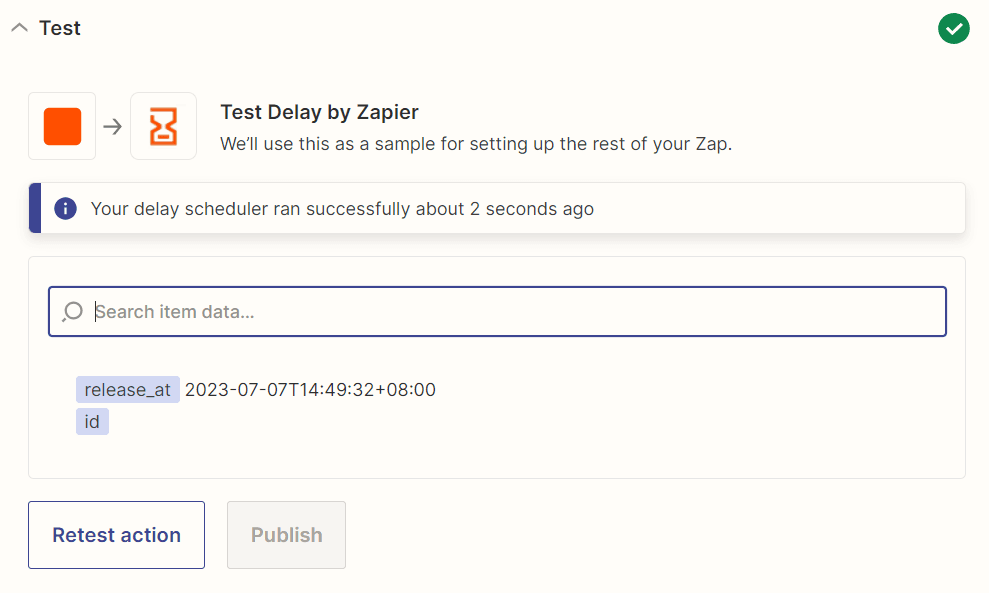
Step 10: Delay by Zapier Result
- Awesome! The delay scheduler runs successfully. We can now add another app to check results from processing large documents.
Step 11: Add Another PDF.co App
- In this step, we will add the PDF.co app and choose the Job Check option to check the status of the job and determine if it has been completed.
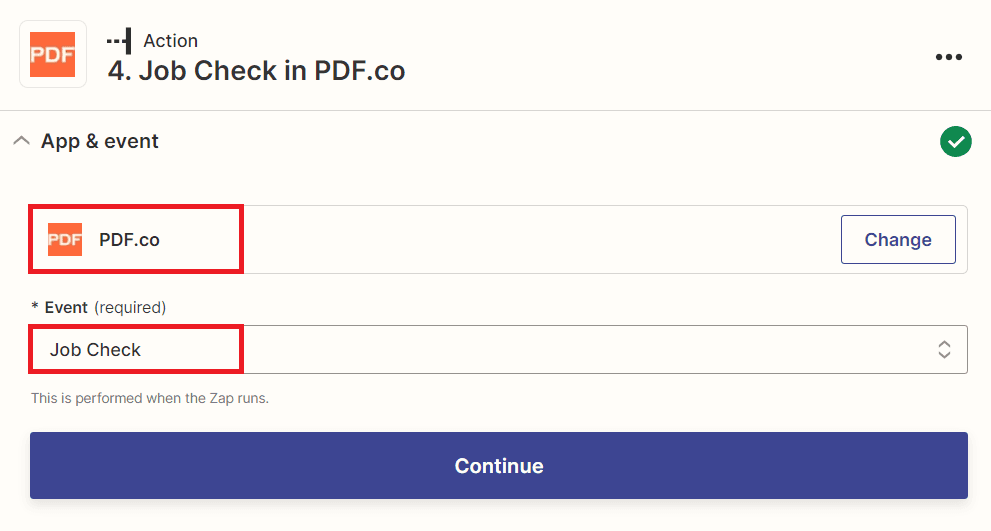
Step 12: Configure PDF.co Settings
Let’s configure the PDF.co settings.
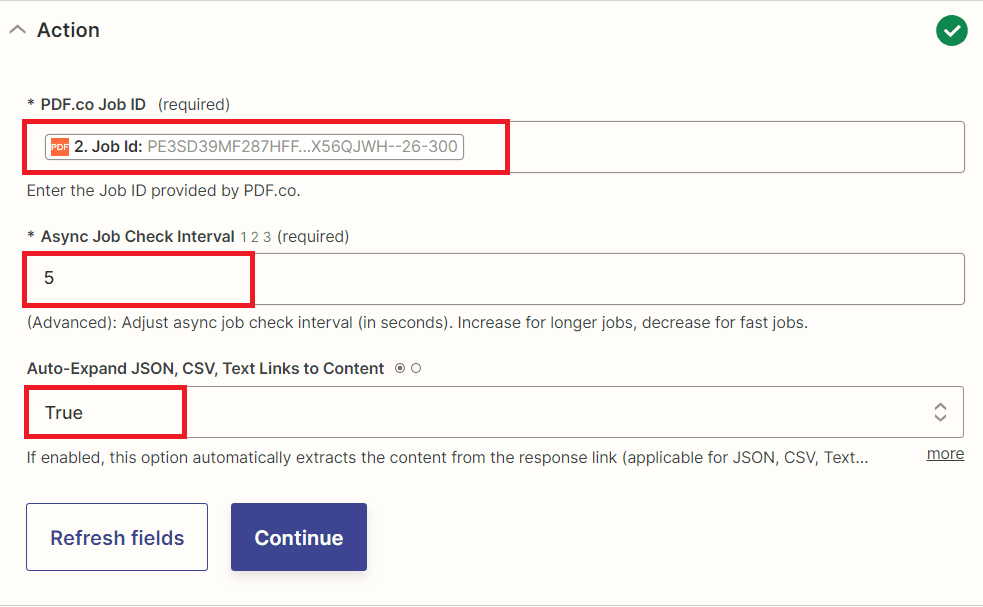
- In the PDF.co Job ID field, enter the Job Id provided by PDF.co.
- For the Async Job Check Interval field, adjust the async job check interval (in seconds). You may increase for longer jobs and decrease for fast jobs.
- Choose either true or false for the Auto-Expand JSON, CSV, and Text Links to Content fields. Setting it to true will automatically extract the content from the response link (applicable for JSON, CSV, and Text formats) and include it directly in the output.
Step 13: Job Check Result
- Congratulations! PDF.co successfully process our request and check the Job ID. You may now copy the resulting URL and paste it into your browser to view the converted scanned PDF to editable text PDF.
You just learned how to process large files with PDF.co and Zapier. Since PDF.co can be integrated into hundreds of different applications, we also have several hundreds of tutorials on our site. For example, we can also show you how to process large files using PDF.co and Make using custom API call action, in case you’re interested.