How to Convert PDF to XML with UiPath
In this step-by guide, we’ll learn how to extract data from PDF in XML format using UiPath and PDF.co.
Install PDF.co package for UiPath
UiPath Studio provides a nice NuGet-like experience in adding third-party packages. To install the PDF.co package follow these steps.
Open the package window by clicking “Manage Packages” in the top ribbon menu.
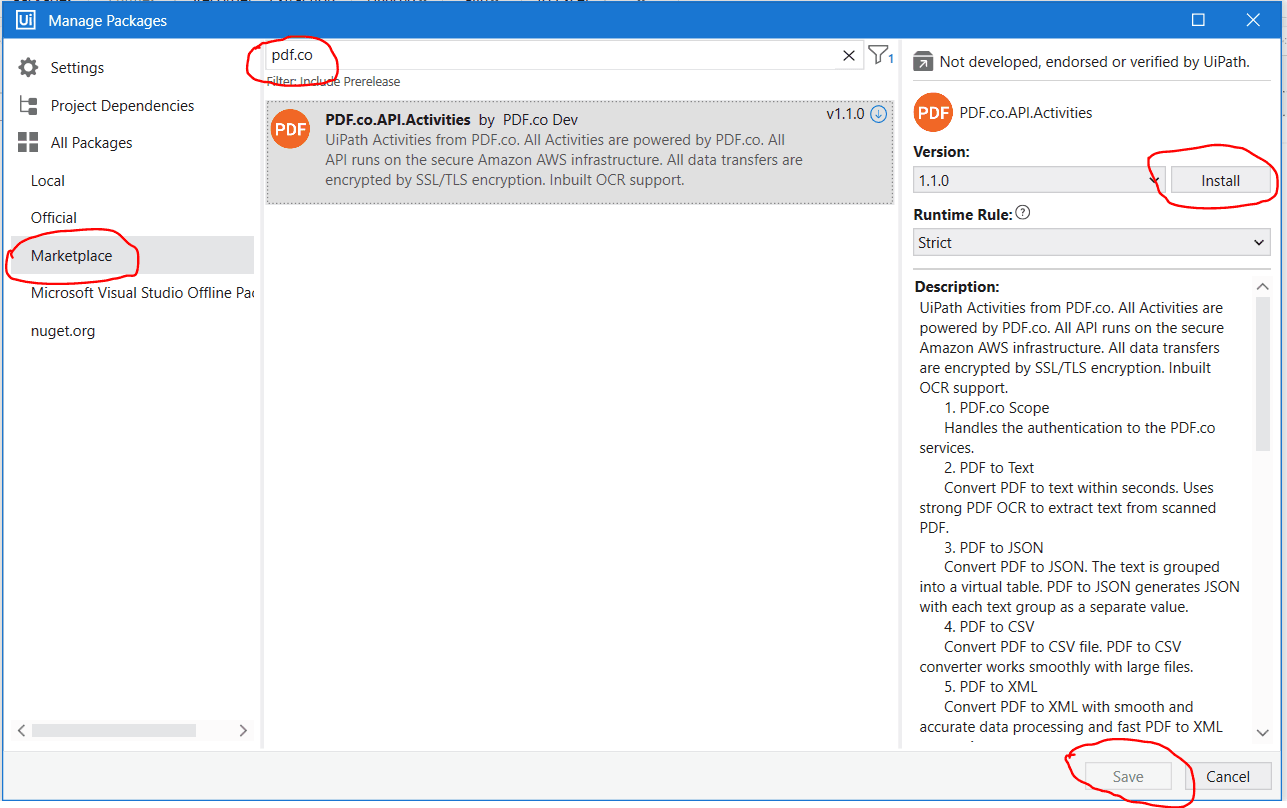
With the completion of this simple step, you’ve successfully installed the PDF.co package in your UiPath Studio. Now, you’ll find PDF.co activities in the activity panel as shown in the following image.
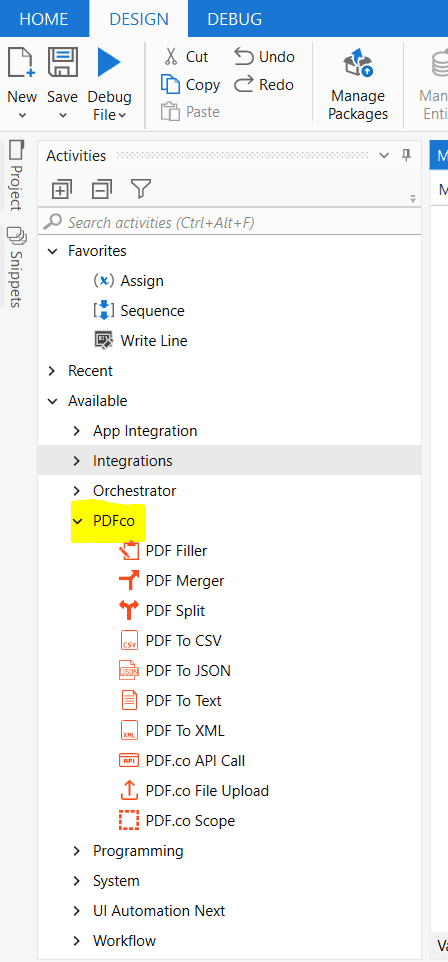
Configure PDF.co Scope
Adding and configuring PDF.co Scope is very important for running PDF.co services. PDF.co scope provides a generic way to provide PDF.co API key as shown in the following figure.
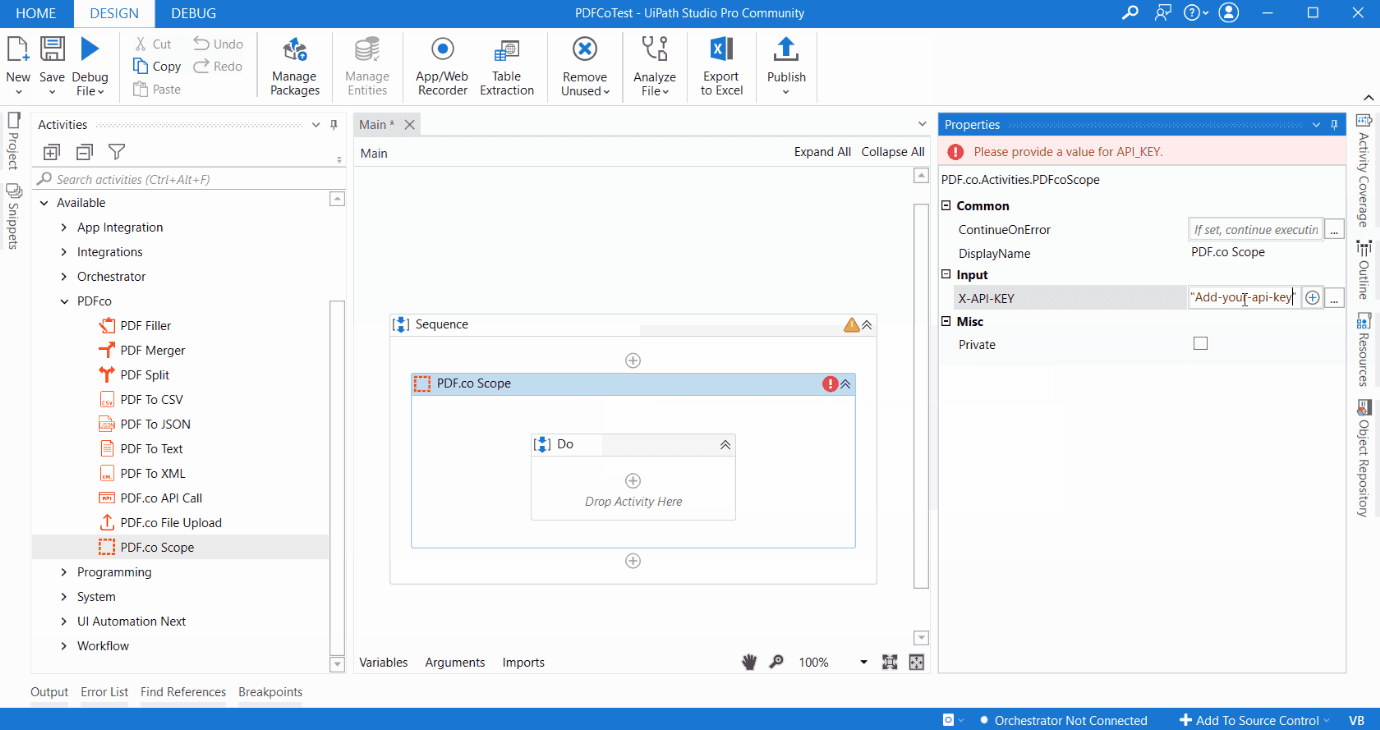
Please note that all other PDF.co activities such as PDF Merge, PDF Split, PDF Filler, PDF to XML must be inside PDF.co Scope. It is because PDF.co scope contains PDF.co API key and as other activities use PDF.co API key from PDF.co Scope, it must be within scope.
PDF.co API key is necessary for authentication of PDF.co requests. You can get the PDF.co API key upon signing up.
Add and Configure PDF to XML Activity
As the name suggests, the “PDF to XML” activity is useful to convert PDF to XML. Now, drag and drop PDF to XML activity inside PDF.co Scope.
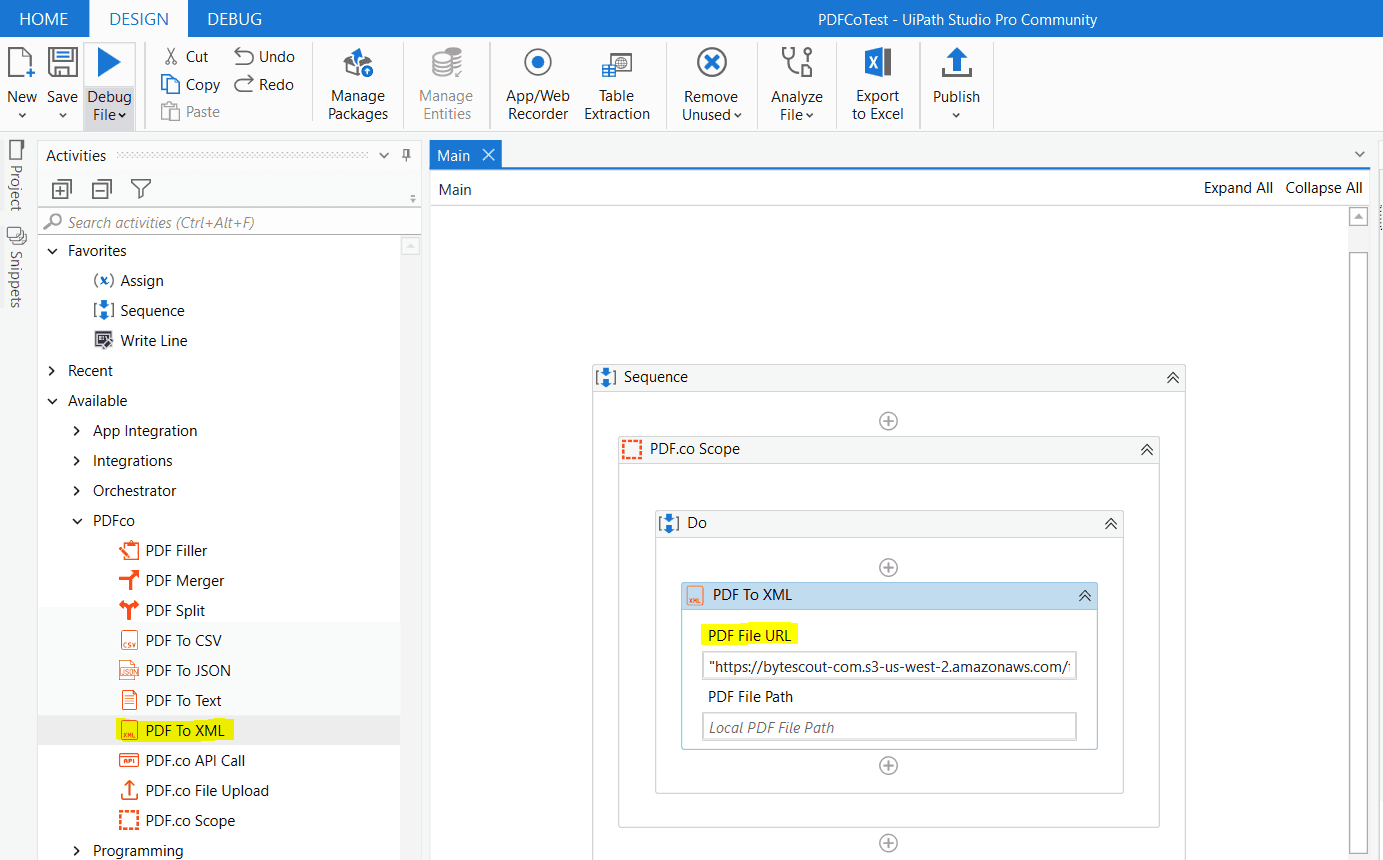
For input PDF we can either give the URL of the PDF file (as shown image above), or we can give a physical path to the PDF file. In this case, input is in string format, hence as per UiPath constraints, it must be within a double quotation (“”).
“PDF to XML” activity consists of many properties to configure output as per our requirement. Let’s see them briefly.
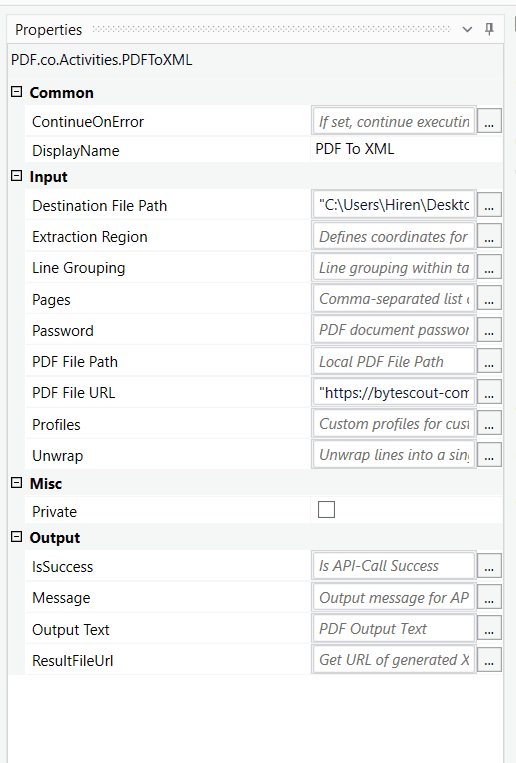
Destination File Path- Input. Output physical path for storing resulting XML file.Extraction Region- Input. If we only need to extract a particular portion of PDF as XML, we need to provide coordinates here. For example, “51, 114, 235, 204”.Line Grouping- Input. To enable line grouping between table cells, enable this field.Pages- Input. Configure this field with page numbers for restricting extraction from that page only.Comma-separated list of page indices (or ranges) to process. IMPORTANT: the very first page starts at 0 (zero). To set a range use the dash -, for example 0,2-5,7-. To set a range from index to the last page use range like this: 2- (from page #3 as the index starts at zero and till the end of the document). For ALL pages just leave this param empty.Password- Input. When the input PDF is password protected, provide the password here.PDF File Path- Input. The physical path of input PDF file.PDF File URL- Input. URL of input PDF file.Profiles- Input. You can set additional and extra options using this parameter that allows you to set custom configurations. See profile samples for more examples.Unwrap- Input. Unwrap lines into a single line within table cells whenlineGroupingis enabled.IsSuccess- Output This field contains the status of API calls. Whether it succeeded or not.Message- Output. Response message if anyOutput Text- Output. Output XML textResultFileUrl- Output. URL of the output XML result
To get more out of this article, please practice this in your machine. Thank you for reading!

