How to Extract Text from Scanned PDF using Make
Experience an entirely new approach to transforming your PDF documents into text format through the remarkable collaboration of PDF.co and Make. This partnership simplifies the process of converting PDFs into editable text. PDF.co and Make have combined to make this process smooth, efficient, and even inspiring.
Imagine releasing yourself from the challenges of formatting issues and the repetitive task of manually extracting data. With PDF.co’s advanced technology smoothly integrated into Make’s user-friendly interface, converting PDFs to text becomes as easy as a few clicks. Whether you’re a business professional extracting data from financial documents, invoices, or research papers, or simply someone who values productivity, our PDF-to-text conversion solution meets your needs.
In this guide, you’ll discover the remarkable possibilities that develop when using PDF.co and Make to transform your PDF documents into text format. So without further ado, let’s get started!
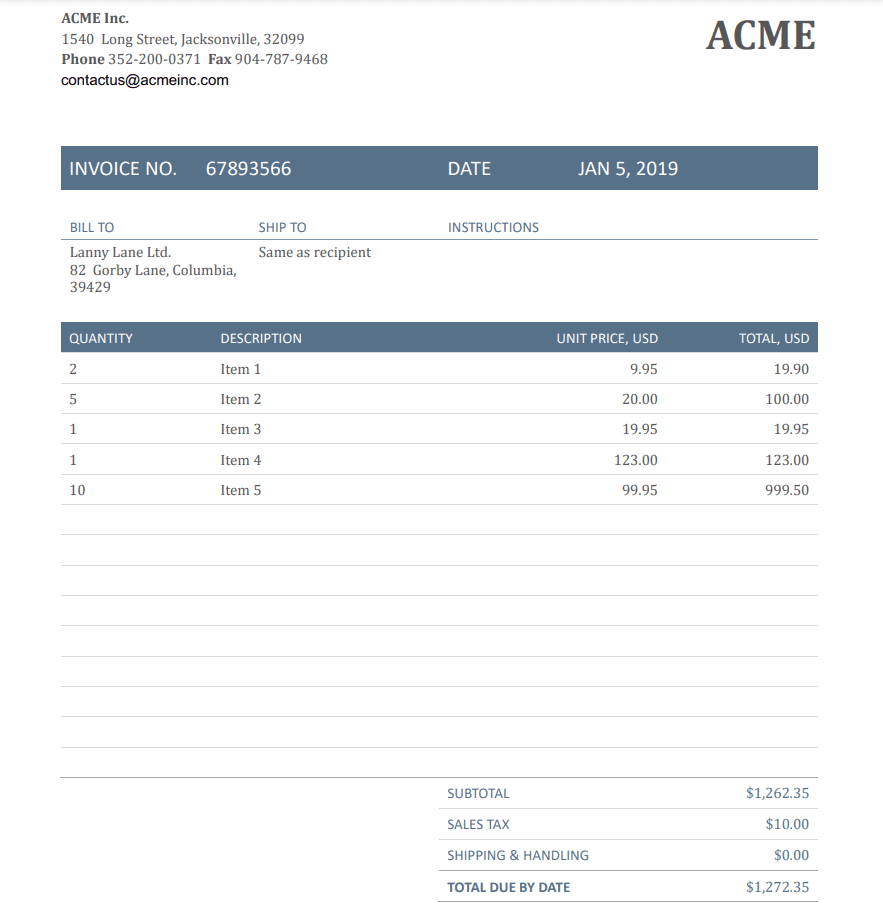
We will utilize this sample PDF document and transform it into text format.
Step 1: Create a New Scenario
First, let’s open your Make account and initiate the process by creating a new scenario.
Step 2: Add Google Drive Module
Next, locate and choose the Google Drive app from the available options. Alternatively, you can also select other cloud storage services that contain the source file you desire.
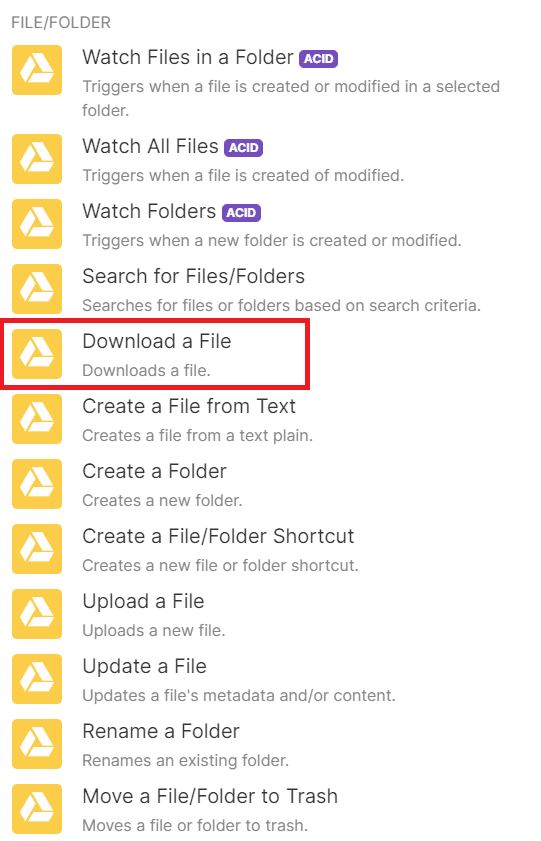
Then, select the Download a File module, which will be activated when a file is downloaded from Google Drive.
Step 3: Google Drive Configuration
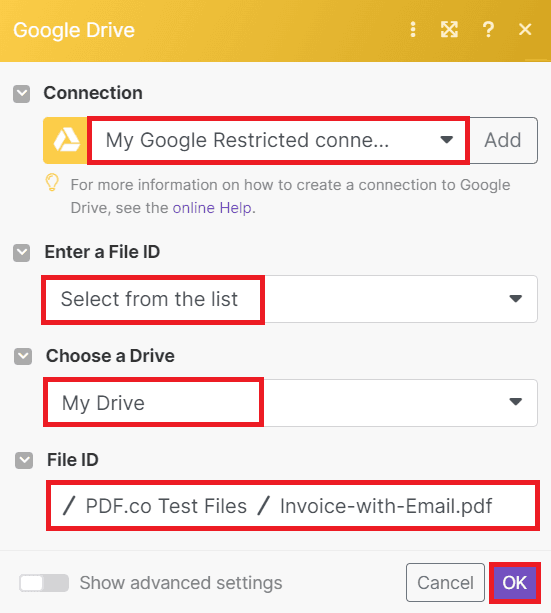
To configure the Google Drive settings, begin by connecting your Google Drive account to Make. This step ensures that Make can obtain access and authorization to your Google Drive files.
Next, in the Enter a File ID field, choose the Select from the list option.
Proceed by selecting My Drive as the desired drive in the Choose a Drive field.
Lastly, enter the folder and file name you wish to use for the process in the File ID field.
Once the configuration has been correctly set up, proceed to run the scenario to observe the results. By executing the scenario, you will be able to witness the outcome of the conversion process.
Step 4: Run Scenario Result
Great! The scenario was successfully executed and the file was retrieved from Google Drive, let’s proceed by incorporating another app that will enable us to convert the PDF document into a text format.
Step 5: Add PDF.co Module
In this step, we will integrate the PDF.co app into our workflow and select the Convert from PDF module. This module will enable us to easily convert the PDF document into a text format.

Step 6: Setup PDF.co Configuration
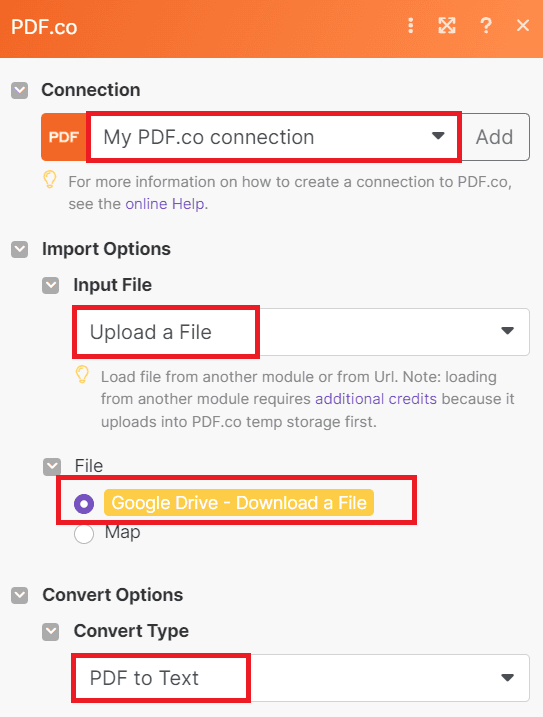
To begin setting up the PDF.co configuration, establish a connection between your PDF.co account and Make by adding the API Key. You can obtain the API Key from your PDF.co dashboard or by signing up at the provided link.
In the Input File field, select the Upload File option. This will allow us to conveniently upload the file that was previously downloaded from Google Drive.
For the Convert Type field, choose the PDF to Text option. This selection ensures that the PDF document is converted into a text format as desired.
After finalizing the configuration, execute the scenario to initiate the conversion process of the PDF document into a text format.
Step 7: Conversion Result
Congratulations on the successful conversion of the PDF document into a text format! To view the output, simply copy the provided URL and paste it into your web browser. This will allow you to access and examine the converted text conveniently.
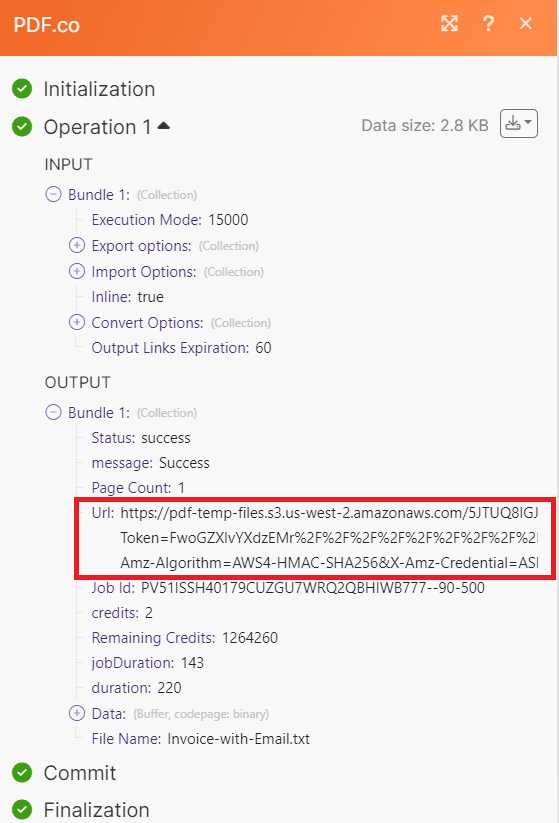
Step 8: Output
Presented below is the extracted text obtain from the PDF document.

In this tutorial, you have acquired the knowledge of converting PDF documents to text format using the collaborative efforts of PDF.co and Make. You have become familiar with the PDF.co PDF to Text API, which enables you to extract text from PDF documents efficiently. This API allows you to smoothly convert PDF files into editable text format.
Related Tutorials
