How to Extract Text from Scanned PDF in Python using PDF.co Web API
PDF.co Web API provides a rich set of functionalities for performing various operations on PDF documents. It can merge, split, and parse PDF documents. You can automatically fill form fields with PDF documents and scan the PDF documents into various formats. PDF.co Web API helps with extracting text from scanned PDF documents in Python and provides a set of data extraction functions and tools for document manipulation.
Now, we will show you how to extract text from the scanned PDF in Python using PDF.co Web API. Below is the sample scanned PDF document that we’re going to use in this tutorial.
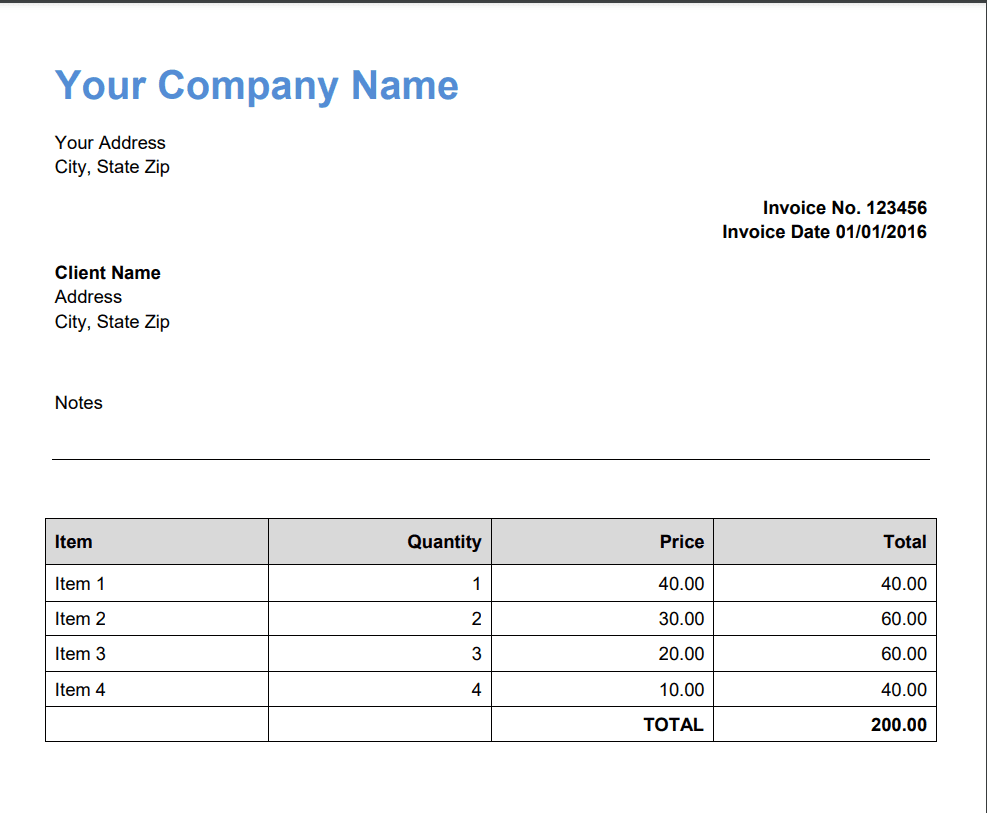
Here’s the step-by-step guide to extracting text from the scanned PDF.
Step 1: Install the Request Module
First, let’s start by installing the request module to manage new packages written in Python. To do that, type python -m pip install request in your command line.
Step 2: Open Visual Studio Code Editor
Next, open the Visual Studio Code Editor. Let’s use this editor to execute the Python code. You can also use your favorite editor in Python.
Then, add the Python sample code. You can copy/download the sample code here.
Step 3: Setup Python Code
Now, let’s set up the Python code.
- In line 6, add your PDF.co API Key inside the quote. You can get the API Key by logging in or signing up at PDF.co.
- In line 12, input the scanned PDF file name. You can get the sample scanned PDF here.
- In line 18, enter your preferred file name of the extracted text from the scanned PDF.
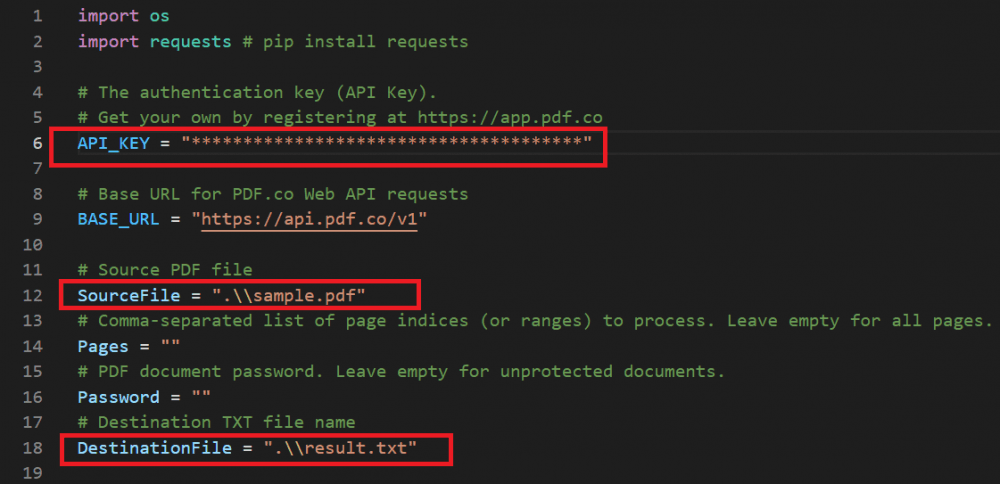
Since we’re done setting up the Python code, let’s save the file and click the Run button to execute the program.
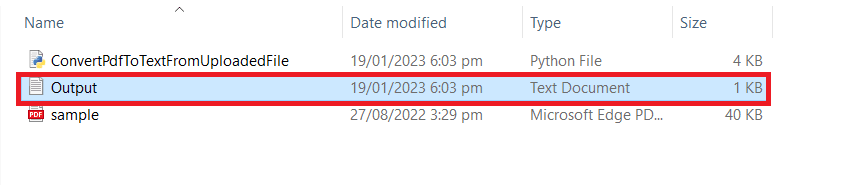
Step 4: Run Program Result
Once the PDF extraction using Python runs successfully, go to the Python program folder to view the output.
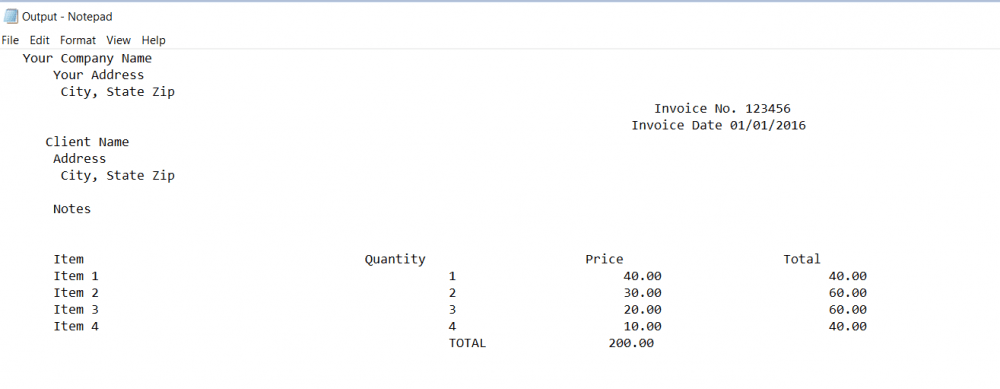
Step 5: Extracted Text Output
This is the extracted text from the scanned PDF document using Python.
In this tutorial, you learned how to extract text from scanned PDF documents in Python using the PDF.co Web API. You learned how to install the requests module. You learned how to use the PDF.co PDF to TEXT Web API to extract text from the scanned PDF document.

