Go here to get a copy of our sample files.
Extract Tables with Text from PDF in PHP using PDF.co Web API
Sep 2, 2024·2 Minutes Read
In this tutorial, we will show you how to extract tables with text from PDF in PHP using PDF.co Web API.
IN THIS TUTORIAL
Step 1: Source Code
To begin, let’s copy the HTML and the PHP source code. Save it in a folder inside the /www or /htdocs directory depending on whether you are using XAMPP or WampServer
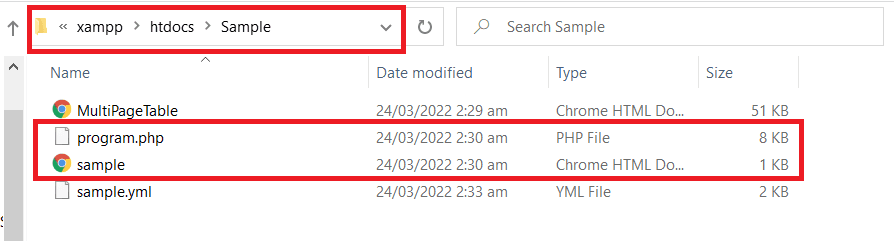
Step 2: Start Apache
Next, let’s start the Apache server so we can run the program on our local machine.
Step 3: Run Program
Now, let’s run our program. Type in localhost/folder_name/sample.html in your browser. Then, enter your PDF.co API Key, sample PDF, and sample template. You can get your API Key in the dashboard.
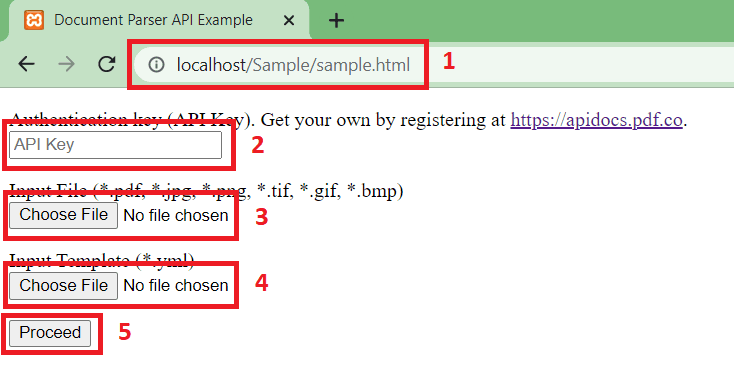
Step 4: Extracted Table Output
PDF.co will return a temporary URL to access the extracted table output. Kindly open the URL to see the result.
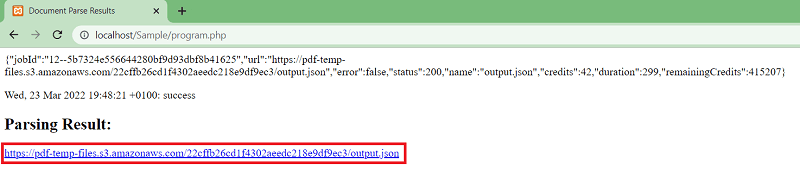
In this tutorial, you learned how to extract tables with text in PHP using PDF.co Web API. You also learned how easy it is to set up the code samples to get your program running right away.
Video Guide
Related Tutorials

Quick Start with Document Parser Template Editor: How To Create a Template
Sep 2, 2024·5 Minutes Read