How to Extract Images From PDF in Python and Convert Them Back to PDF
Sep 2, 2024·7 Minutes Read
In this tutorial, we’re going to show you how to extract images from PDF in Python and convert them back to PDF.
Step 1: Source
Create a Python file and add the following source code:
import requests # pip install requests
# The authentication key (API Key).
# Get your own by registering at https://app.pdf.co
API_KEY = "***************************************"
# Base URL for PDF.co Web API requests
BASE_URL = "https://api.pdf.co/v1"
# Direct URL of source PDF file.
# You can also upload your own file into PDF.co and use it as url. Check "Upload File" samples for code snippets: https://github.com/bytescout/pdf-co-api-samples/tree/master/File%20Upload/
SourceFileURL = "https://bytescout-com.s3.amazonaws.com/files/demo-files/cloud-api/pdf-to-image/sample.pdf"
# Comma-separated list of page indices (or ranges) to process. Leave empty for all pages. Example: '0,2-5,7-'.
Pages = ""
# PDF document password. Leave empty for unprotected documents.
Password = ""
def main(args = None):
convertPdfToImage(SourceFileURL)
def convertPdfToImage(sourceFileURL):
"""Converts PDF To Image using PDF.co Web API"""
# Prepare requests params as JSON
# See documentation: https://developer.pdf.co
parameters = {}
parameters["password"] = Password
parameters["pages"] = Pages
parameters["url"] = sourceFileURL
# Prepare URL for 'PDF To PNG' API request
url = "{}/pdf/convert/to/png".format(BASE_URL)
# Execute request and get response as JSON
response = requests.post(url, data=parameters, headers={ "x-api-key": API_KEY })
if (response.status_code == 200):
json = response.json()
if json["error"] == False:
# Download generated PNG files
part = 1
for resultFileUrl in json["urls"]:
# Download Result File
r = requests.get(resultFileUrl, stream=True)
localFileUrl = f"Page{part}.png"
if r.status_code == 200:
with open(localFileUrl, 'wb') as file:
for chunk in r:
file.write(chunk)
print(f"Result file saved as \"{localFileUrl}\" file.")
else:
print(f"Request error: {response.status_code} {response.reason}")
part = part + 1
else:
# Show service reported error
print(json["message"])
else:
print(f"Request error: {response.status_code} {response.reason}")
if __name__ == '__main__':
main()Step 2: Install request module
- Have installed the request module already? If not, kindly install the requests module. You can do it by running on your command line:
python -m pip install requests Step 3: Add API Key
- On
line 5Insert your API key into your Python code. You may get your API key from your dashboard.
Step 4: URL to Source and Path to Output File
- Add the URL to your source and path for your output file on
line 12withSourceFileURL
Step 5: Setup Parameters
- Set up the parameters for your PDF to PNG conversion
- On
lines 27-30define any parameters you may need for passwords etc.
Step 6: Run Program
- Once you’re done with your code, you may now run your program. You can see the output file in your folder
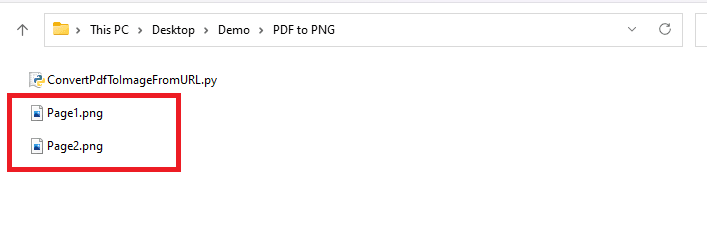
Step 7: How to Convert Them Back into PDF
Follow these steps to convert images back to PDF in Python.
Step 1: URL to Source and Path to Output
- Add the URL to your source and path for your output file
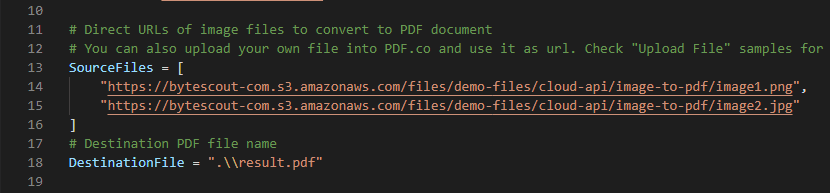
Step 2: Setup Parameters
- Set up the parameters for your PNG to PDF conversion
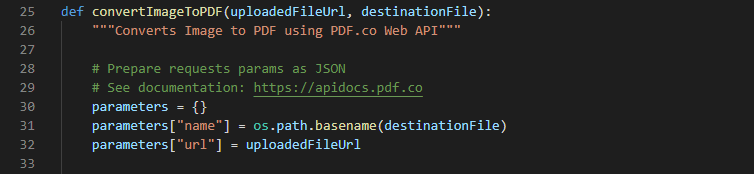
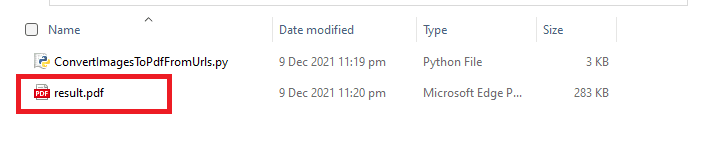
Step 3: Run Program
- Once you’re done with your code, you may now run your program. You can see the output file in your folder
In this tutorial you’ve learned how to convert PDF to PNG and convert the PNG back to PDF in Python with PDF Extractor API.
