Search PDF using Regular Expressions with C# and PDF.CO Web API
In this article, you will see how to search PDF documents using regular expressions in C# with the help of PDF.CO web API.
The article is divided into two sections. In the first section, you will see how to search a PDF document using keywords via PDF.CO Web API.
In the next section, you will see how to use regular expressions in C# to search PDF documents using PDF.CO Web API.
Search with Keywords in C#
Searching a PDF document with keywords in C# using PDF.CO Web API is very simple.
Steps
The first step is to import the libraries required to execute our C# script in this section.
using System.Net;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;The System.Net library comes preinstalled with the Microsoft.NET framework. However, you will have to install the “NewtonSoft” library yourself.
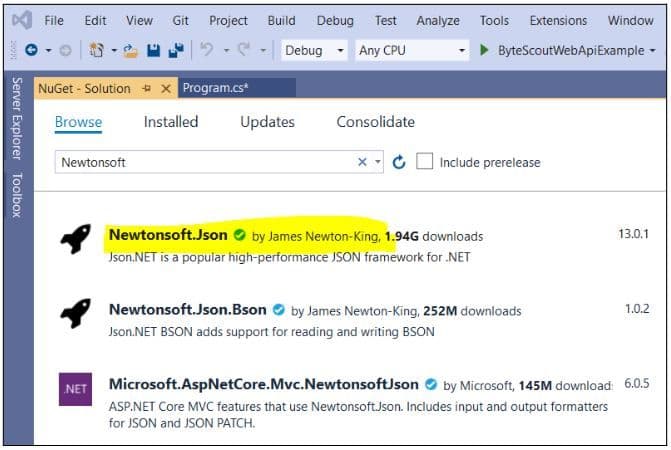
To do so from the Microsoft Visual Studio IDE, go to “Tools-> NuGet Package Manager.” Search for the “Newtonsoft” library. Select the first package and click the “Install” button.
The next step is to define C# string variables that store the following:
- The PDF.CO Web API key. You can get your API key by registering at https://app.pdf.co.
- The URL of the source PDF document that you want to search. The source PDF document for this article can be found at this link:
- The pages of the PDF document that you want to search. Leaving this field empty results in searching all the pages of the PDF document.
- The search string: the keywords you want to search in your PDF document.
Finally, you also need to create a boolean variable that specifies whether or not you want to use regular expressions to search the PDF document. To search with keywords only, this boolean variable is set to False.
The following script defines the aforementioned C# variables:
const String API_KEY = "************************";
const string SourceFile = @"https://bytescout-com.s3-us-west-2.amazonaws.com/files/demo-files/cloud-api/pdf-split/multiple-invoices.pdf";
const string Pages = "";
const string SearchString = @"date";
const bool RegexSearch = false;Next, you create an object of the C# WebClient class. You need to add your PDF.CO API key to this object. The script below also defines a variable that stores the PDF.CO API call for searching PDF documents.
WebClient webClient = new WebClient();
webClient.Headers.Add("x-api-key", API_KEY);string url = "https://api.pdf.co/v1/pdf/find";The next step is to define the parameter dictionary containing parameters that will be sent to the PDF.CO Web API call. The parameter dictionary should contain the following:
- The number of pages to search
- The URL of the source file
- The search string
- The boolean value for the regex search, which in this case will be false.
You can look at the official documentation to see details of the other optional parameters.
Finally, you also need to serialize your parameter dictionary.
Dictionary<string, object> parameters = new Dictionary<string, object>();
parameters.Add("pages", Pages);
parameters.Add("url", SourceFile);
parameters.Add("searchString", SearchString);
parameters.Add("regexSearch", RegexSearch);// Convert dictionary of params to JSON
string jsonPayload = JsonConvert.SerializeObject(parameters);Now, you are ready to make a call to the PDF.CO Web API for searching PDF documents.
Inside the try/catch block, the WebClient object makes a call to the PDF.CO Web API using the UploadString() method.
The response from the call is parsed as a JSON object. In case of an error or exception, the error message is displayed on the console.
If the response does not contain any error, the “body” list from the JSON object is parsed, and the details of all the search items found inside the PDF documents are displayed on the console.
try
{
// Execute POST request with JSON payload
string response = webClient.UploadString(url, jsonPayload);// Parse JSON response
JObject json = JObject.Parse(response);
if (json["status"].ToString() != "error")
{
foreach (JToken item in json["body"])
{
Console.WriteLine($"Found text \"{item["text"]}\" at coordinates {item["left"]}, {item["top"]}");
}
}
else
{
Console.WriteLine(json["message"].ToString());
}
}
catch (WebException e)
{
Console.WriteLine(e.ToString());
}
webClient.Dispose();
Console.WriteLine();
Console.WriteLine("Press any key...");
Console.ReadKey();Complete Code to Search PDF with Keywords in C#
Here is the code for searching a PDF document with Keywords using C# and PDF.CO Web API.
In this script, we search for the keyword “date” in our input PDF document.
using System.Net;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;namespace PDFCOWebApiExample
{
public class Program
{
const String API_KEY = "*********************";
const string SourceFile = @"https://bytescout-com.s3-us-west-2.amazonaws.com/files/demo-files/cloud-api/pdf-split/multiple-invoices.pdf";
const string Pages = "";
const string SearchString = @"date";
const bool RegexSearch = false;static void Main(string[] args)
{
WebClient webClient = new WebClient();
webClient.Headers.Add("x-api-key", API_KEY);
string url = "https://api.pdf.co/v1/pdf/find";
Dictionary<string, object> parameters = new Dictionary<string, object>();
parameters.Add("pages", Pages);
parameters.Add("url", SourceFile);
parameters.Add("searchString", SearchString);
parameters.Add("regexSearch", RegexSearch);
// Convert dictionary of params to JSON
string jsonPayload = JsonConvert.SerializeObject(parameters);
try
{
// Execute POST request with JSON payload
string response = webClient.UploadString(url, jsonPayload);
// Parse JSON response
JObject json = JObject.Parse(response);
if (json["status"].ToString() != "error")
{
foreach (JToken item in json["body"])
{
Console.WriteLine($"Found text \"{item["text"]}\" at coordinates {item["left"]}, {item["top"]}");
}
}
else
{
Console.WriteLine(json["message"].ToString());
}
}
catch (WebException e)
{
Console.WriteLine(e.ToString());
}
webClient.Dispose();
Console.WriteLine();
Console.WriteLine("Press any key...");
Console.ReadKey();
}
}
}Input PDF Document
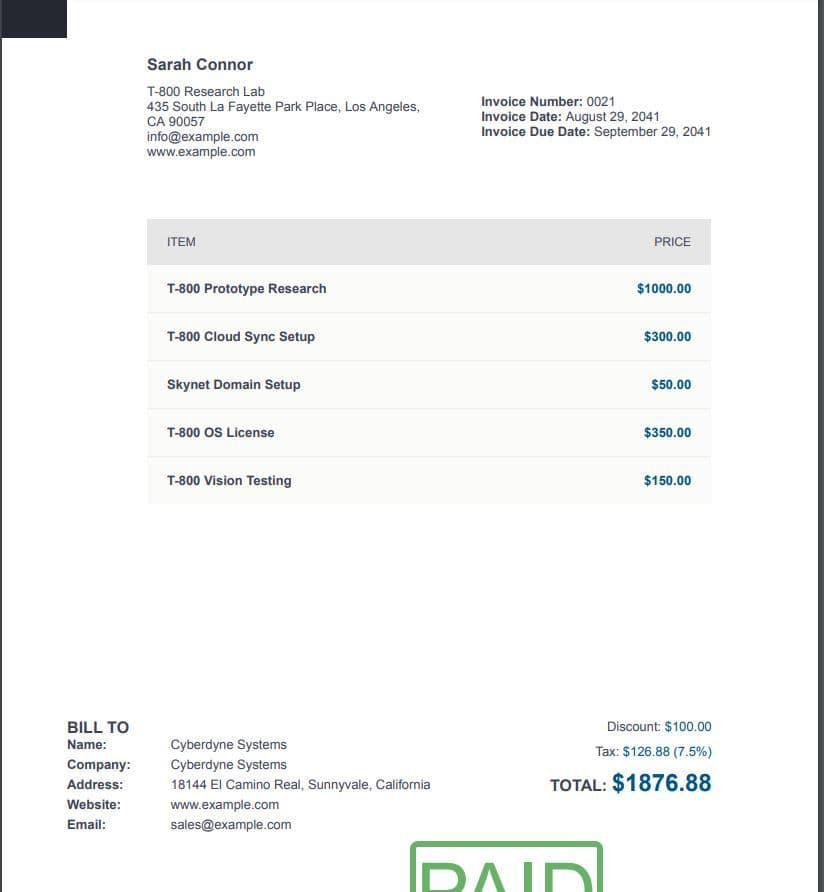
Our input PDF document looks like this. You can see it contains the keyword “date” at the top right corner. There are many other instances of date as well.
Output
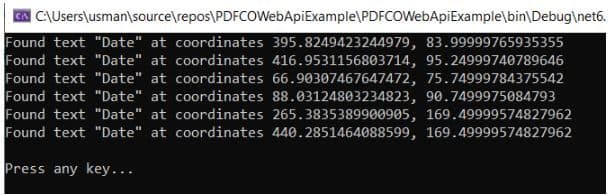
In the console output below, you can see the text “date” along with its coordinates in the PDF document.
Search with Regex in C#
In this section, you will see how you can search PDF documents using regular expressions in C# using the PDF.CO Web API.
The process remains similar to what you have already seen with only slight changes.
Steps
The first step is to import the required libraries:
using System.Net;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;Next, you need to define variables containing your API key, the URL of the source file, the number of pages, the search string, and the boolean variables, which specify if the regular expressions should be used.
However, in this case, the search string will contain regular expressions whereas the boolean variable for using regular expressions is set to false.
We will use the same invoice (as you saw in the last section) as the source PDF document. The regex expression will look for all the digits that follow a currency symbol in our source document.
Look at the script below for reference.
const String API_KEY = "***************";
const string SourceFile = @"https://bytescout-com.s3-us-west-2.amazonaws.com/files/demo-files/cloud-api/pdf-split/multiple-invoices.pdf";
const string Pages = "";
const string SearchString = @"(\p{Sc}) *([0-9.]*)";
const bool RegexSearch = true;The following script defines the WebClient object for making PDF.CO Web API calls. The Web API call for searching PDF documents is also stored in a C# variable.
WebClient webClient = new WebClient();
webClient.Headers.Add("x-api-key", API_KEY);
string url = "https://api.pdf.co/v1/pdf/find";The following script defines the parameter dictionary containing parameters that will be sent along with the API call. The parameter dictionary is also serialized.
Dictionary<string, object> parameters = new Dictionary<string, object>();
parameters.Add("pages", Pages);
parameters.Add("url", SourceFile);
parameters.Add("searchString", SearchString);
parameters.Add("regexSearch", RegexSearch);
// Convert dictionary of params to JSON
string jsonPayload = JsonConvert.SerializeObject(parameters);The rest of the script is the same. The WebClient object makes a call to the PDF.CO Web API. The response from the PDF call is parsed as a JSON object.
If the JSON object contains no errors, the “body” list from the JSON object is iterated and the details of the searched items are displayed on the console.
In case of an error or an exception, the error message is displayed on the console.
try
{
// Execute POST request with JSON payload
string response = webClient.UploadString(url, jsonPayload);
// Parse JSON response
JObject json = JObject.Parse(response);
if (json["status"].ToString() != "error")
{
foreach (JToken item in json["body"])
{
Console.WriteLine($"Found text \"{item["text"]}\" at coordinates {item["left"]}, {item["top"]}");
}
}
else
{
Console.WriteLine(json["message"].ToString());
}
}
catch (WebException e)
{
Console.WriteLine(e.ToString());Finally, the WebClient class object is disposed of.
webClient.Dispose();
Console.WriteLine();
Console.WriteLine("Press any key...");
Console.ReadKey();Complete Code to Search PDF with RegEx in C Sharp
Here is the complete code for searching a PDF Document using regular expressions in C# with PDF. CO Web API.
using System.Net;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;namespace PDFCOWebApiExample
{
public class Program
{
const String API_KEY = "******************";
const string SourceFile = @"https://bytescout-com.s3-us-west-2.amazonaws.com/files/demo-files/cloud-api/pdf-split/multiple-invoices.pdf";
const string Pages = "";
const string SearchString = @"(\p{Sc}) *([0-9.]*)";
const bool RegexSearch = true;
static void Main(string[] args)
{
WebClient webClient = new WebClient();
webClient.Headers.Add("x-api-key", API_KEY);
string url = "https://api.pdf.co/v1/pdf/find";
Dictionary<string, object> parameters = new Dictionary<string, object>();
parameters.Add("pages", Pages);
parameters.Add("url", SourceFile);
parameters.Add("searchString", SearchString);
parameters.Add("regexSearch", RegexSearch);
// Convert dictionary of params to JSON
string jsonPayload = JsonConvert.SerializeObject(parameters);
try
{
// Execute POST request with JSON payload
string response = webClient.UploadString(url, jsonPayload);
// Parse JSON response
JObject json = JObject.Parse(response);
if (json["status"].ToString() != "error")
{
foreach (JToken item in json["body"])
{
Console.WriteLine($"Found text \"{item["text"]}\" at coordinates {item["left"]}, {item["top"]}");
}
}
else
{
Console.WriteLine(json["message"].ToString());
}
}
catch (WebException e)
{
Console.WriteLine(e.ToString());
}
webClient.Dispose();
Console.WriteLine();
Console.WriteLine("Press any key...");
Console.ReadKey();
}
}
}
Input Document in PDF
Here is our input PDF document.
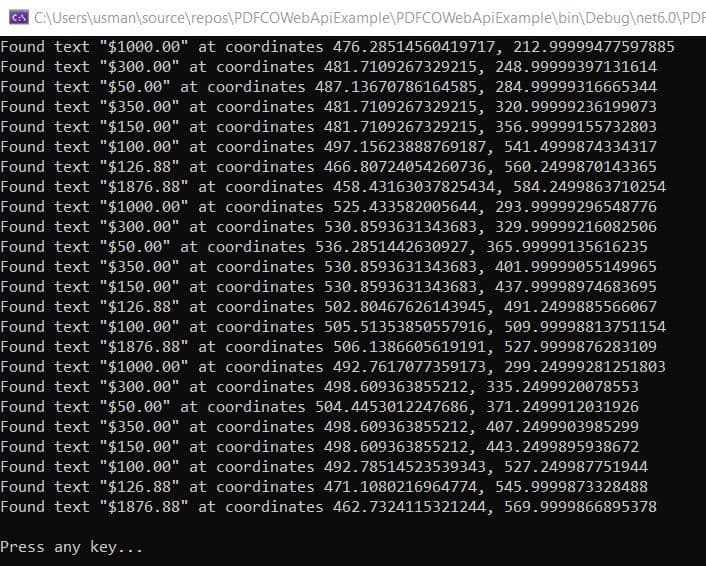
Since we searched for all the digits that follow a currency symbol, you can see all the amounts from your invoice and their coordinates.
Related Tutorials
