The upper and lower margins while setting the footer and header of the page is important because they may overlap with the page content, thus, making it unreadable.
How to Scrape Web Pages into a PDF Using the PDF.co API in JavaScript with Asynchronous Processing (Node.js)
Jan 9, 2025·12 Minutes Read
This tutorial explains how to generate a PDF from a web URL using the PDF.co Web API with JavaScript (Node.js). It demonstrates how to store important information from web pages in PDF files, either on local storage or in the cloud.
However, in this updated tutorial, we will focus on asynchronous processing, which is the preferred method for handling such tasks efficiently, especially when dealing with external APIs or processes that may take time to complete.
The Essence of Asynchronous Processing
In asynchronous processing, instead of waiting for the task (like PDF generation) to finish before moving on to other tasks, your code continues running. Once the task is completed, a callback function or promise is triggered to handle the result. This is particularly useful when working with API calls or large-scale data processing, as it allows for more efficient resource management and a better user experience, especially for longer operations.
In this tutorial, we will use asynchronous processing to scrape web pages and generate PDFs using the PDF.co API. This will ensure that our application remains responsive and efficient, especially when handling multiple requests concurrently.
For more details on asynchronous processing, refer to the PDF.co Documentation.
How to Scrape Web Pages with PDF from URL Endpoint
You can use the PDF from the URL endpoint of PDF.co web API to generate PDF files from the web URL or link to HTML pages. This endpoint takes the URL link and other optional parameters to generate an output link to a PDF file. Moreover, you can set the header and footer of the PDF files of your choice. Finally, you can choose to download the file using various filing modules to store them on local storage.
Endpoint Parameters
Following are the parameters of PDF from URL endpoint:
1. Url: It is a required parameter which is a string containing the web URL or the HTML file that you want to convert. The PDF.co platform supports any publicly accessible URL, including those from Dropbox, Google Drive, and the built-in file storage of PDF.co.
2. async: It is an optional parameter that you can set to “true” to run it asynchronously. You may encounter the error “405” if you try to process large documents synchronously. In that case, you must set it to “true” to convert those documents or web pages or specify the page range.
3. name: It is an optional parameter, a string containing the name of the output file. It is set to “result.pdf” by default.
4. expiration: It is an optional parameter defining the output file’s link expiration in minutes. It is set to 60 minutes by default, and you can set it to different periods depending on their subscription plan. The files get automatically deleted from the cloud after this period. However, you can permanently store them using the PDF.co built-in file storage system.
5. margins: It is an optional parameter containing the margins of the output PDF file. You can set the margins as in CSS styling, such as writing “2px, 2px, 2px, 2px” to adjust the top, right, bottom, and left margins.
6. paperSize: It is an optional parameter to set the paper size of the output file. It is set to “Letter” by default. However, you can set it to “Letter”, “Legal”, “Tabloid”, “Ledger”, “A0”, “A1”, “A2”, “A3”, “A4”, “A5”, “A6” or any custom size. The custom sizes can be in px (pixels), mm (millimeters), or in (inches). For instance, 100px, 200px to set width and height respectively.
7. Orientation: It is an optional parameter to define the orientation of the output file’s pages. You can set it to “Portrait” or “Landscape”. By default, it is set to “Portrait.”
8. printBackground: It is an optional parameter to disable or enable background printing. It is set to “true” by default.
9. DoNotWaitFullLoad: It is an optional parameter to explicitly control the waiting and skip the wait for a full load, such as large images and videos, to manage the total conversion time. It is set to “false” by default.
10. profiles: It is an optional parameter, a string that allows you to set custom configurations.
11. Header: It is an optional parameter to set the header of the output PDF file (every page of the file). You can use HTML elements to design the header.
12. footer: It is an optional parameter to set the footer of the output PDF file (every page of the file). This parameter accepts HTML to apply at the end of the pages.
How to Inject Printing Values into Header and Footer
You can use the following classes to inject the printing values into the header and footer:
date: This class prints the formatted datetitle: This class prints the document title.Url: This class prints the document location.pageNumber: This class prints the current pageNumber of the document.totalPages: This class prints the total pages in the document.
Read more about the classes and see sample examples here.
Scrape Web Pages and Generate PDF using Javascript
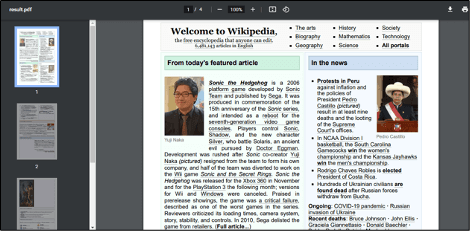
The following source code explains how to generate PDF files from a web URL using the PDF.co web API. This code takes the website URL of Wikipedia’s main page and converts it to a PDF file. Moreover, the parameter “DoNotWaitFullLoad” is set to “true” to reduce the time needed to convert the whole website page to a PDF file. Finally, you can see the output URL in your terminal and use that link to view the resulting file or use the JavaScript file stream module to download the file contents and store them on your local storage as a PDF file.
Source Code for Web Scraping
Below is the sample code to generate PDF from a URL:
Code Sample: Here
PDF File Output
Below are the screenshots of the code output and the output file obtained in the API response:
Sample Header and Footer
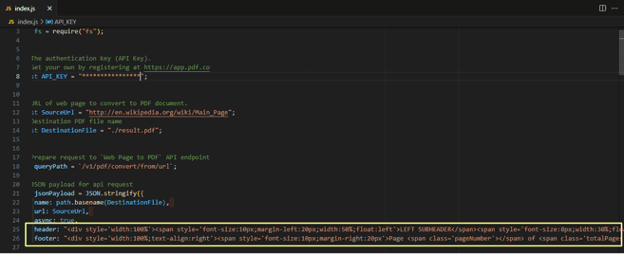
Below is the source code containing the header and footer parameters in addition to the parameters mentioned above. These HTML codes set the header to display the “left subheader” and “right subheader” at the top left and top right sections of every page, respectively. Similarly, the footer code uses the classes “pageNumber” and “totalPages” to write “page N of NN” at the bottom right of each page. Moreover, you can see from the coding example and the screenshot that you can style these spans and divs just as you would when writing regular HTML.
Code Snippet
var https = require("https");
var path = require("path");
var fs = require("fs");
// The authentication key (API Key).
// Get your own by registering at https://app.pdf.co
const API_KEY = "****************";
// URL of web page to convert to PDF document.
const SourceUrl = "http://en.wikipedia.org/wiki/Main_Page";
// Destination PDF file name
const DestinationFile = "./result.pdf";
// Prepare request to `Web Page to PDF` API endpoint
var queryPath = `/v1/pdf/convert/from/url`;
// JSON payload for api request
var jsonPayload = JSON.stringify({
name: path.basename(DestinationFile),
url: SourceUrl,
async: true,
header: "<div style='width:100%'><span style='font-size:10px;margin-left:20px;width:50%;float:left'>LEFT SUBHEADER</span><span style='font-size:8px;width:30%;float:right'>RIGHT SUBHEADER</span></div>",
footer: "<div style='width:100%;text-align:right'><span style='font-size:10px;margin-right:20px'>Page <span class='pageNumber'></span> of <span class='totalPages'></span>.</span></div>"
});
var reqOptions = {
host: "api.pdf.co",
method: "POST",
path: queryPath,
headers: {
"x-api-key": API_KEY,
"Content-Type": "application/json",
"Content-Length": Buffer.byteLength(jsonPayload, 'utf8')
}
};
// Send request
var postRequest = https.request(reqOptions, (response) => {
response.on("data", (d) => {
// Parse JSON response
var data = JSON.parse(d);
if (data.error == false) {
console.log(`Job #${data.jobId} has been created!`);
checkIfJobIsCompleted(data.jobId, data.url);
}
else {
// Service reported error
console.log(data.message);
}
});
}).on("error", (e) => {
// Request error
console.log(e);
});
// Write request data
postRequest.write(jsonPayload);
postRequest.end();
function checkIfJobIsCompleted(jobId, resultFileUrl) {
let queryPath = `/v1/job/check`;
// JSON payload for api request
let jsonPayload = JSON.stringify({
jobid: jobId
});
let reqOptions = {
host: "api.pdf.co",
path: queryPath,
method: "POST",
headers: {
"x-api-key": API_KEY,
"Content-Type": "application/json",
"Content-Length": Buffer.byteLength(jsonPayload, 'utf8')
}
};
// Send request
var postRequest = https.request(reqOptions, (response) => {
response.on("data", (d) => {
response.setEncoding("utf8");
// Parse JSON response
let data = JSON.parse(d);
console.log(`Checking Job #${jobId}, Status: ${data.status}, Time: ${new Date().toLocaleString()}`);
if (data.status == "working") {
// Check again after 3 seconds
setTimeout(function(){ checkIfJobIsCompleted(jobId, resultFileUrl);}, 3000);
}
else if (data.status == "success") {
// Download PDF file
var file = fs.createWriteStream(DestinationFile);
https.get(resultFileUrl, (response2) => {
response2.pipe(file)
.on("close", () => {
console.log(`Generated PDF file saved as "${DestinationFile}" file.`);
});
});
}
else {
console.log(`Operation ended with status: "${data.status}".`);
}
})
});
// Write request data
postRequest.write(jsonPayload);
postRequest.end();
}Final PDF Output
Below are the screenshots of the code output and the output file obtained in the API response:

You can find an advanced example with the file downloading functions here.
Related Tutorials

How to Split PDF in Google Drive Folder with Google Apps Script and PDF.co
Sep 2, 2024·6 Minutes Read
Create PDF with JavaScript using HTML Invoice Template
Sep 2, 2024·15 Minutes Read
How to Automatically Add New Wufoo entries to PDF using PDF.co and Zapier
Sep 2, 2024·5 Minutes Read