How to Convert PDF to JSON from a File in Python using the PDF.co Web API
Learn how to merge and convert document data with Python and PDF.co.
Introduction
Merge two PDF files and then to convert PDF to JSON using Python.
The following simple and easy-to-understand source code shows the users how to merge two PDF files in Python using the Merge functionality and then convert the result into JSON using PDF to JSON functionality.
Solution Overview
An overview of our Python code is as follows:
- The first steps in our Python code will be to import required modules and setup variables.
- The next step is to define the API endpoint given in the PDF.co API documentation.
- Then, declare the
api_keyvariable with the provided API key from your PDF.co account. - Upload the files that the user wants to merge on Google Drive, Dropbox, or PDF.co internal storage and get the link to the files.
- Store the files in the separate variables and concatenate those variables using comma
,as a delimiter in the merging order. For instance, for:"files = file1 + ',' + file2", the API will appendfile2tofile1and create the merged output file.
Merge Function
Below is the step-by-step guide to merge two PDF files using the PDF.co API:
- Create a post request using the imported requests module to send the POST request to the API endpoint.
- In the requests function, provide the API key in the headers to authorize the request.
- Then, provide the URL and other parameters in the JSON object in the data field of the requests function.
- Store the API response in the variable and check if the status code of that response is successful or not. Generally, a
200hundred status code means that the request was successful. - If the request was successful, convert the response to a JSON object and print it on the user’s screen, and the output will contain the URL to the merged file.
- If the request was unsuccessful, print that the request was unsuccessful and repeat steps one to four thrice. If the request is still unsuccessful, close the program after informing the user that his request has failed.
Note: The time.sleep() delays the request initiation if the endpoint considers the repeated requests an attack or the massive traffic halts it from sending a successful response.
Python Code
In our Python main function we will request to merge two files.
- The main function is the primary function of any program from where the execution begins. We call the
mergeFiles()function within the main function to merge the two PDF files. - Note: A Python programmer could pass the files as the parameters to this function and use them inside it or declare them globally.
Below is the sample code to merge two PDF files using PDF.co API:
Obtain your api_key by logging into PDF.co and replace the asterisks ***** with your key.
# importing module
import requests
import time
# API endpoint to merge pdfs
url = "https://api.pdf.co/v1/pdf/merge"
# defining parameter
api_key ="************************************"
# files to be merged
file1 = "https://drive.google.com/file/d/1DvAV1iRpVVc1TxsQ2BcX_NJnapEaU41w/view?usp=sharing"
file2 = "https://drive.google.com/file/d/1sPFzo2EZjt190cpirdsstJ60fq3nbhel/view?usp=sharing"
# combining file URLs, separated by comma
files = file1 + ',' + file2
# function to merge to pdf files
def merge_files():
tries = 3
# try at least three time if the request gets failed
while (tries >= 0):
# post request to the API endpoint to merge to pdf files
response = requests.post(url,
headers={
"x-api-key": api_key
},
data={
"url": files
}
)
# checking if the request is successful or not
if response.status_code == 200:
print(response)
print(response.json())
return
else:
tries = tries -1
# sleep for some time
time.sleep(0.5)
print("request failed, trying again")
print("request failed, returning")
# file's main function
def main():
merge_files()
main()
JSON Output
On a successful response (200) JSON will be output, for example:
{
'url': 'https://pdf-temp-files.s3.amazonaws.com/43a10d61095b47698fcb03102b0e6995/view.pdf',
'pageCount': 2,
'error': False,
'status': 200,
'name': 'view.pdf',
'remainingCredits': 250,
'credits': 4
}The JSON object in the above output contains the URL to the merged file, the page count in the output file, the error report of the merging process, merge status, and the merged file name. Moreover, it contains the API’s remaining credits and the used credits to inform the user of their remaining credits.
The url value from the JSON can be used to access the resulting PDF, for example:
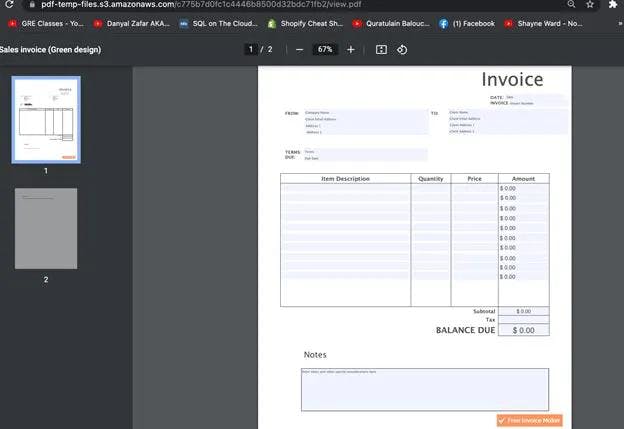
Converting the Merged File into JSON
Below is the step-by-step guide to convert the merged file obtained in the above example into JSON:
- Store the URL gotten from the merged API response in a variable called
file_url. - Define a function to convert PDF to JSON, and pass the
file_urlas its parameter. - In the
pdf_to_json()function, send the post request to the pdf_to_json API’s endpoint, stored in theurl_jsonvariable. - In the request function, provide the API key in the headers and the
file_urlin the data. - Store the response in a variable and check if the request was successful or not using its status code.
- If the request is successful, convert the response to a JSON object and print it on the user’s screen, and the output will contain the URL to the required JSON.
- If the request is unsuccessful, print that the request was unsuccessful and repeat steps one to four thrice. If the request is still unsuccessful, close the program after informing the user that his request has failed.
- The users can directly call the
pdf_to_json()function from the main function and convert any PDF file to the JSON format. Moreover, the users can choose to convert only a part of a PDF file using the data parameters of the converting API. - Change the tries variable to any value to set the request limits to the endpoints. Additionally, the users can manipulate the
time.sleep()function inside both functions, i.e., pdf_to_json and merging, to set the time delay between the two requests.
Python Code
Below is the sample code to convert the PDF file into JSON using PDF.co API
Obtain your api_key by logging into PDF.co and replace the asterisks ***** with your key.
# importing modules
import requests
import time
# API endpoint to merge pdfs
url = "https://api.pdf.co/v1/pdf/merge"
# API endpoint to convert pdf to json
url_json = "https://api.pdf.co/v1/pdf/convert/to/json2"
# defining parameter
api_key = "****************************************"
# files to be merged
file1 = "https://drive.google.com/file/d/1DvAV1iRpVVc1TxsQ2BcX_NJnapEaU41w/view?usp=sharing"
file2 = "https://drive.google.com/file/d/1sPFzo2EZjt190cpirdsstJ60fq3nbhel/view?usp=sharing"
# combining file urls, separated by comma
files = file1 + ',' + file2
def pdf_to_json(file_url):
tries = 3
# try atleast three time if the reqeust gets failed
while (tries >= 0):
# post request to the API endpoint to merge to pdf files
response = requests.post(url_json,
headers={
"x-api-key": api_key
},
data={
"url": file_url
}
)
# checking if the request is successful or not
if response.status_code == 200:
print(response)
response_json = response.json()
print(response_json)
return
else:
tries = tries -1
# sleep for some time
time.sleep(0.5)
print("request failed, trying again")
print("request failed, returning")
# function to merge to pdf files
def merge_files_output_JSON():
tries =3
# try at least three times if the request gets failed
while (tries >= 0):
# post request to the API endpoint to merge to pdf files
response = requests.post(url,
headers={
"x-api-key": api_key
},
data={
"url": files
}
)
# checking if the request is successful or not
if response.status_code == 200:
print(response)
response_json = response.json()
print(response_json)
file_url = response_json['url']
print(file_url)
pdf_to_json(file_url)
return
else:
tries = tries -1
# sleep for some time
time.sleep(0.5)
print("request failed, trying again")
print("request failed, returning")
# file's main function
def main():
merge_files_output_JSON()
main()JSON Output
On a successful response (200) a JSON output representing your merged PDF will be available, for example:
{
'url': 'https://pdf-temp-files.s3.amazonaws.com/40ba2d7c5083470b8d6dee86170c2e3b/view.json',
'pageCount': 2,
'error': False,
'status': 200,
'name':
'view.json',
'remainingCredits': 194,
'credits': 56
}The above output is the response’s status code, and the JSON object below it is the JSON response of the API. The JSON object contains the URL to the JSON output, the page count in the output file, the error report of the merging process, merge status, and the merged file name. Moreover, the merging endpoint contains the API’s remaining credits and the used credits to inform the user of his credits.
The url value from the JSON can be used to access the resulting PDF, for example:
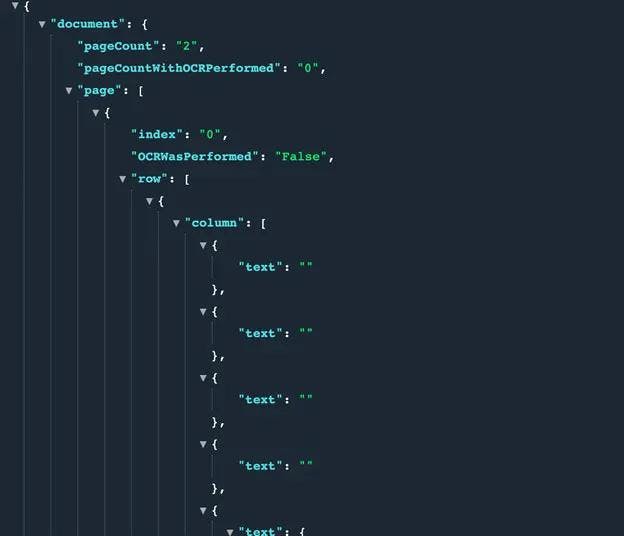
Video Guide
Here’s a short demo guide showing how to convert PDF to JSON in Python using an uploaded file and PDF.co Web API. That’s just a sample workflow and programming code that can be used to parse PDF in Python.
Related Tutorials

